
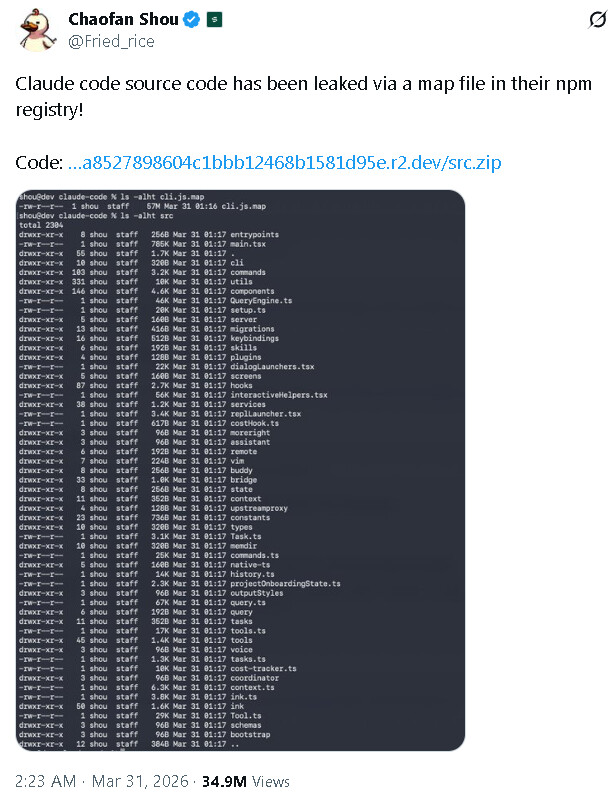
Supplemental for - Local And Distributed AI Redux (Proxmox)
Local AI (Deepseek-R1) Using Open WebUi Within a Proxmox LXC Container
You might think it’s wise to install an advanced LLM chat bot with unknown allegiances outside of a controlled container. I don’t. Enter ‘The Best Way to Get Deepseek-R1: By Using an LXC in Proxmox.’ Did I mention you can scale containers using Kubernetes and/or a fabric of resources; or even a swarm of chat bots? Spiffy. I digress…
Prerequisites:
Proxmox Installed - Installation - Proxmox Virtual Environment
Minimum System Requirements:
A computer or node with 8GB RAM, 32GB Hard Drive, 4 Processor Cores, and a second computer to access Open WebUI from inside browser (Chrome, Brave, etc.).
Recommend:
16GB RAM minimum, 100GB Hard Drive, 8 Processor Cores minimum, your gaming friend’s finest graphics card ~2018 or newer with at least 8GB of RAM, and a second computer to access Open WebUI from inside browser (Chrome, Brave, etc.).
Installation
From: Proxmox VE Helper-Scripts (scroll down)
In a Proxmox Host’s shell, we need to command the host to create our LXC:
bash -c "$(wget -qLO - https://github.com/tteck/Proxmox/raw/main/ct/openwebui.sh)"
You can select default settings for ease of use, but you will save yourself some problems in the future as enumerated below if you set yourself up for success by performing a manual installation instead.
Specifically, give your LXC a static IP address (e.g. 192.168.0.14/24) so it’s easy for you to find later, set the root password yourself so it’s easier to find later, give Open WebUI about 100GB instead of 16GB hard disk space, give yourself as much RAM as possible instead of the default 4GB. Give yourself minimum 8 processor cores, more is better. (We will follow up later on with instructions for graphics card passthrough which dramatically improves performance).
Hop On Your Other Computer
Now that it’s installed navigate in web browser to the address provided by the installer, or the web address you had provided as the static IP address (192.168.0.14:8080). Yes, you need the port 8080 at the end of your URL.
After that, we need to download our model of choice for this example, ‘deepseek-r1’. The following guide was helpful, but skip to the next sentence for the simplest method.
https://dev.to/pavanbelagatti/run-deepseek-r1-locally-for-free-in-just-3-minutes-1e82
Simpler method: use the search box inside of the web-based WebUI, search for ‘deepseek-r1’. Scroll down for screenshots. But first…
As before, for the default of 16GB HDD, 8GB RAM is not sufficient for this download. You will need to shut down your LXC, resize the disk (try 100GB for starts), boot back up. You do this by clicking on the LXC container that was created by the installer script, then click resources, click memory, click edit, change your RAM size. Then click Root Disk → Volume Action → Resize to also increase your hard drive space.

Now navigate to your LXC in browser including port 8080 (e.g. http://192.168.0.14:8080), search for ‘deepseek-r1,’ and click ‘Pull “deepseek-r1” from Ollama.com’ to download. It’s 4.7GB. We already increased our RAM prior.


A Common Problem?
I had the following error - 500: Ollama: 500, message=‘Internal Server Error’, url=‘http://0.0.0.0:11434/api/chat’

I read this was resolved if you simply update Ollama by running the install script again in the LXC’s shell. This didn’t fix the issue for me, but this is a nice command to have in your toolbelt:
curl -fsSL https://ollama.com/install.sh | sh
shutdown
To actually resolve the issue, I went to container->resources->memory->edit and increased my memory to greater than 8GB to resolve the error message preemptively.
Now click start (inside Proxmox) to boot the LXC with the shiny new resources.
Next hop back on the other computer, navigate again to our static IP 192.168.0.14:8080 and the error should be resolved.
CONGRATULATIONS!
So we are off to the races. Next I will brush on adding our graphics card(s) or coprocessors to significantly improve performance.



")







")
