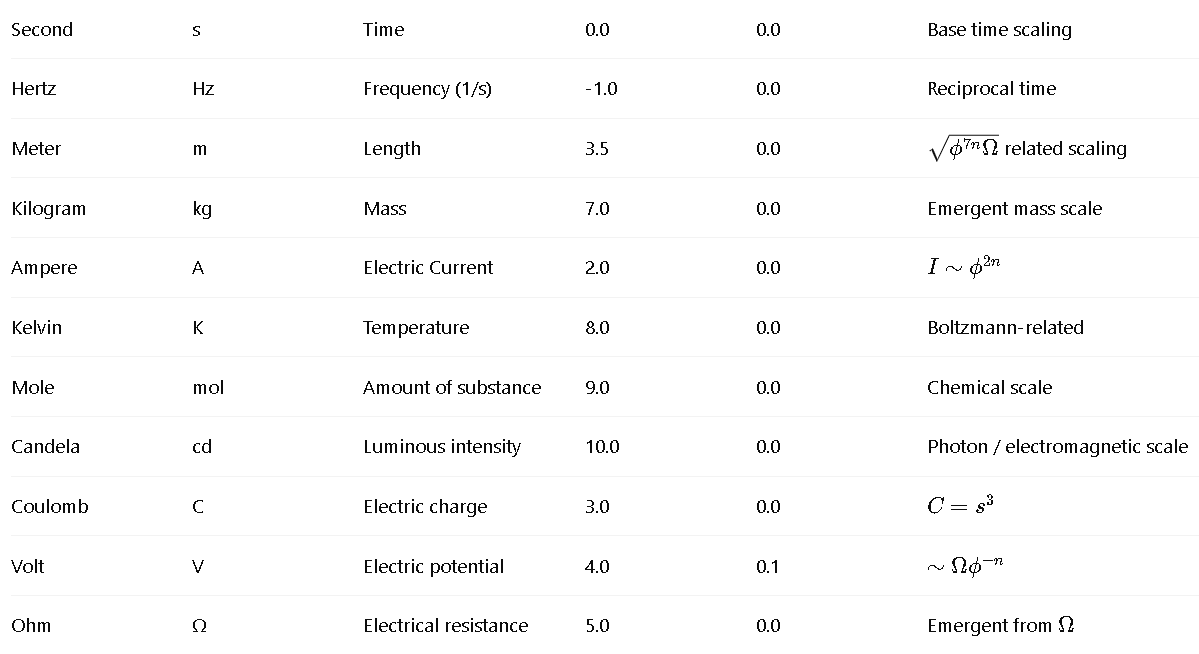
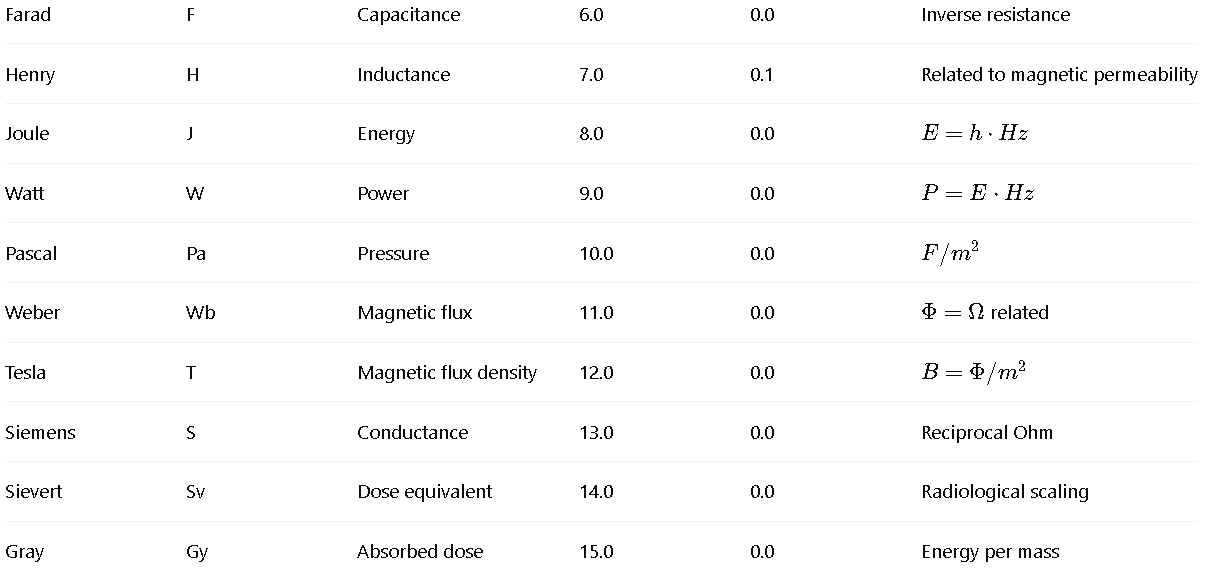
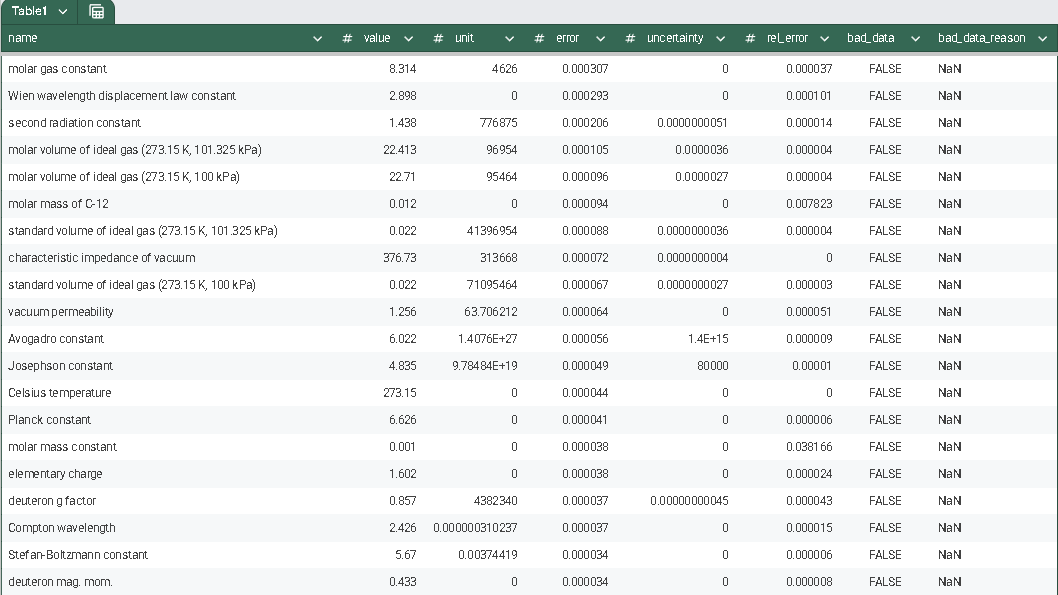
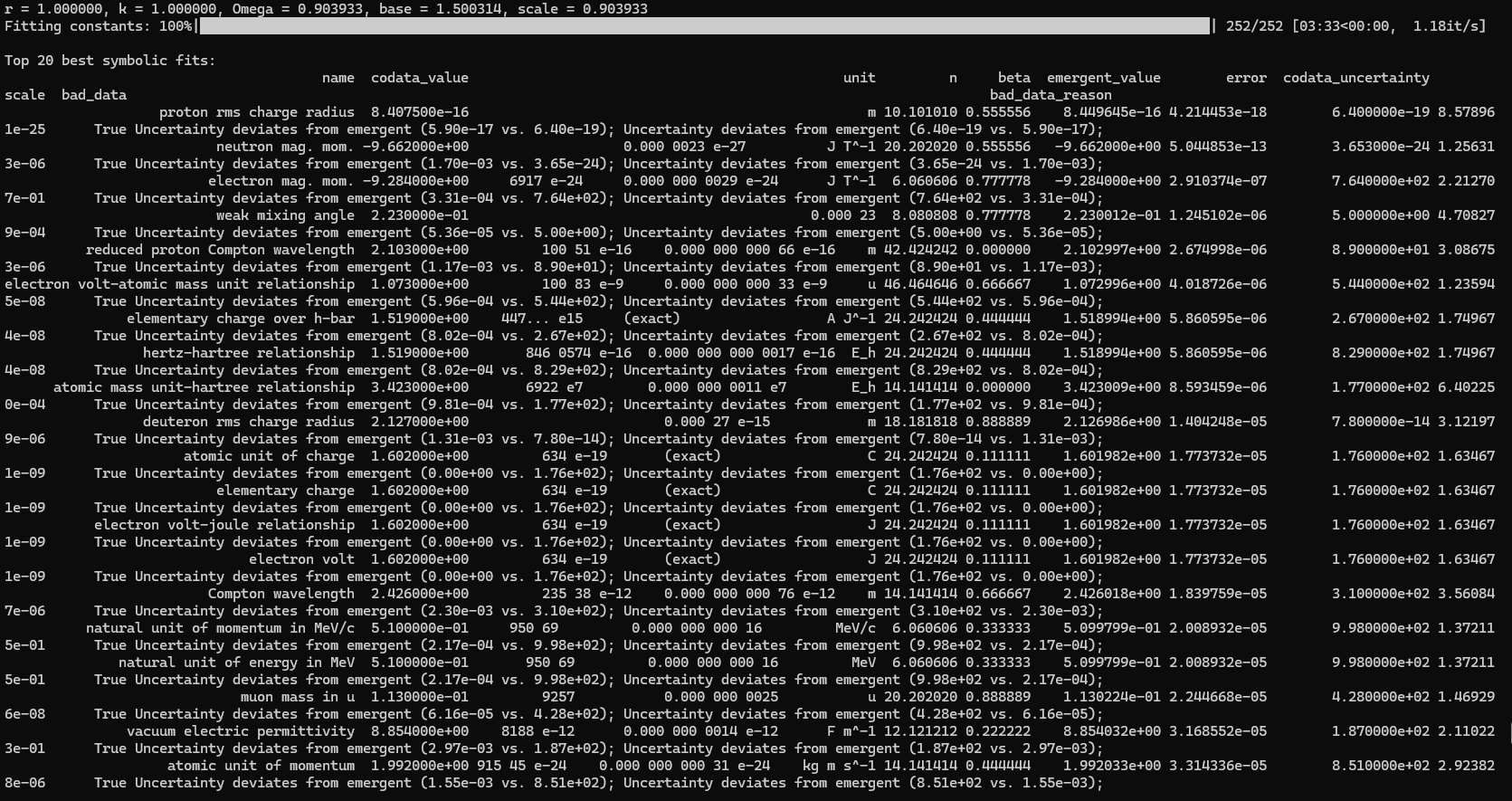
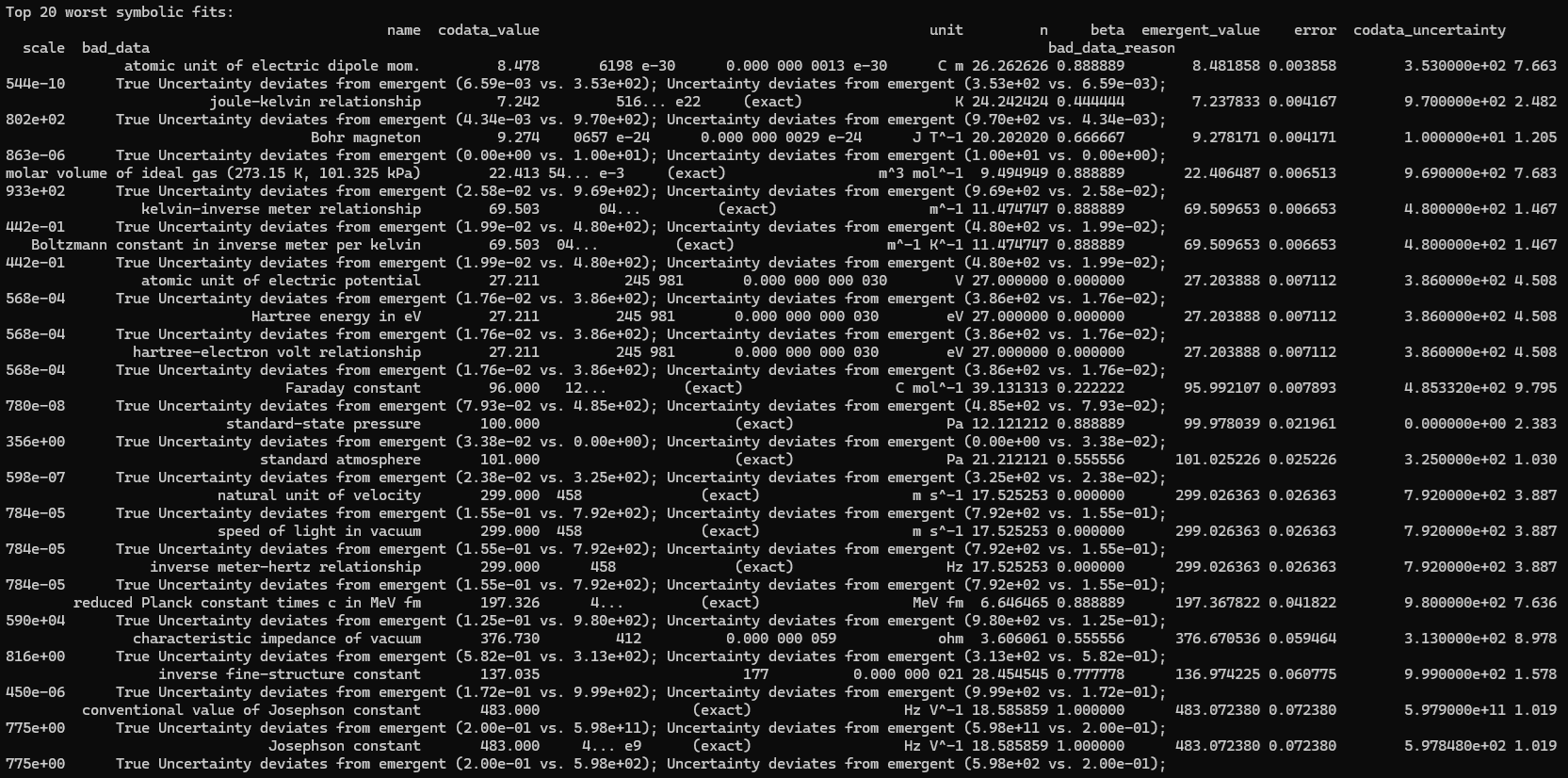
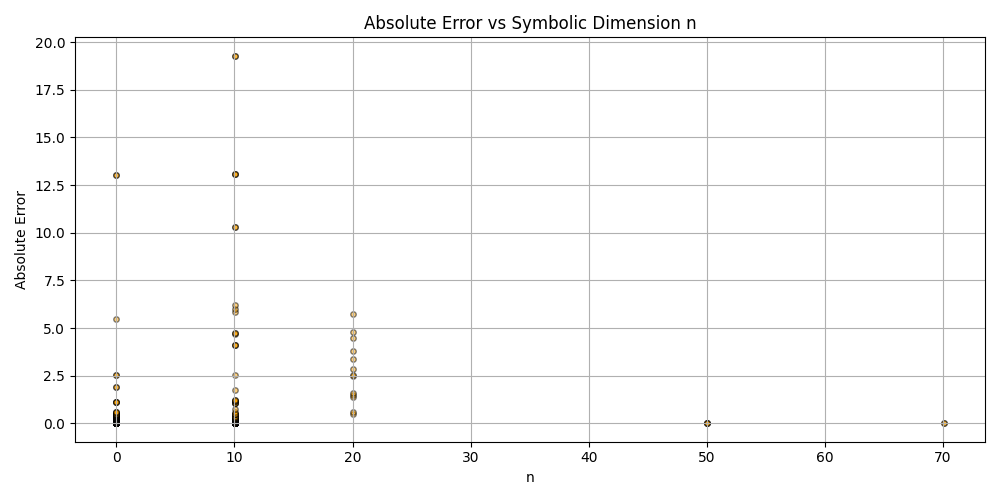
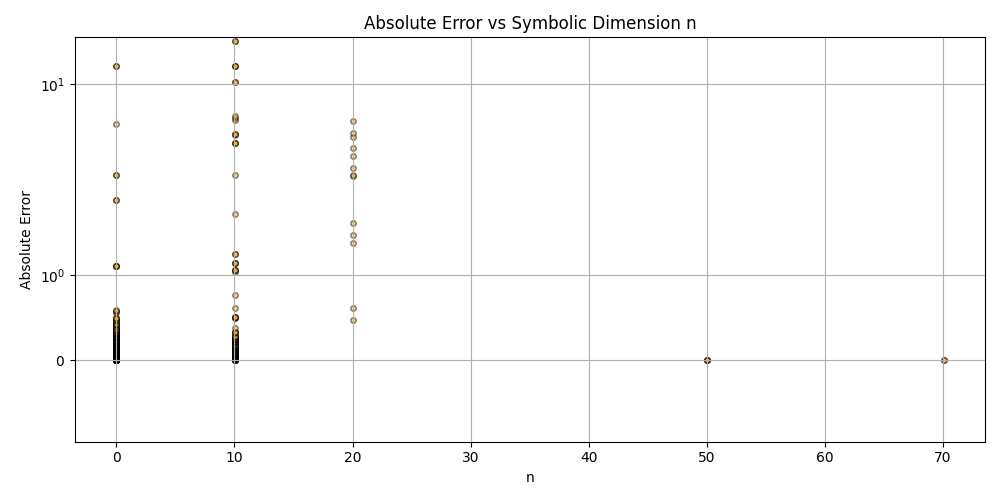
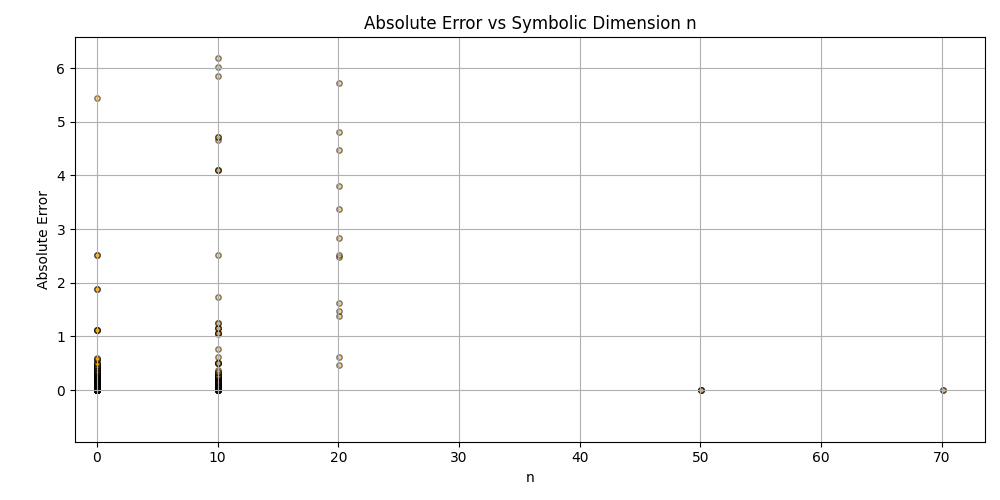
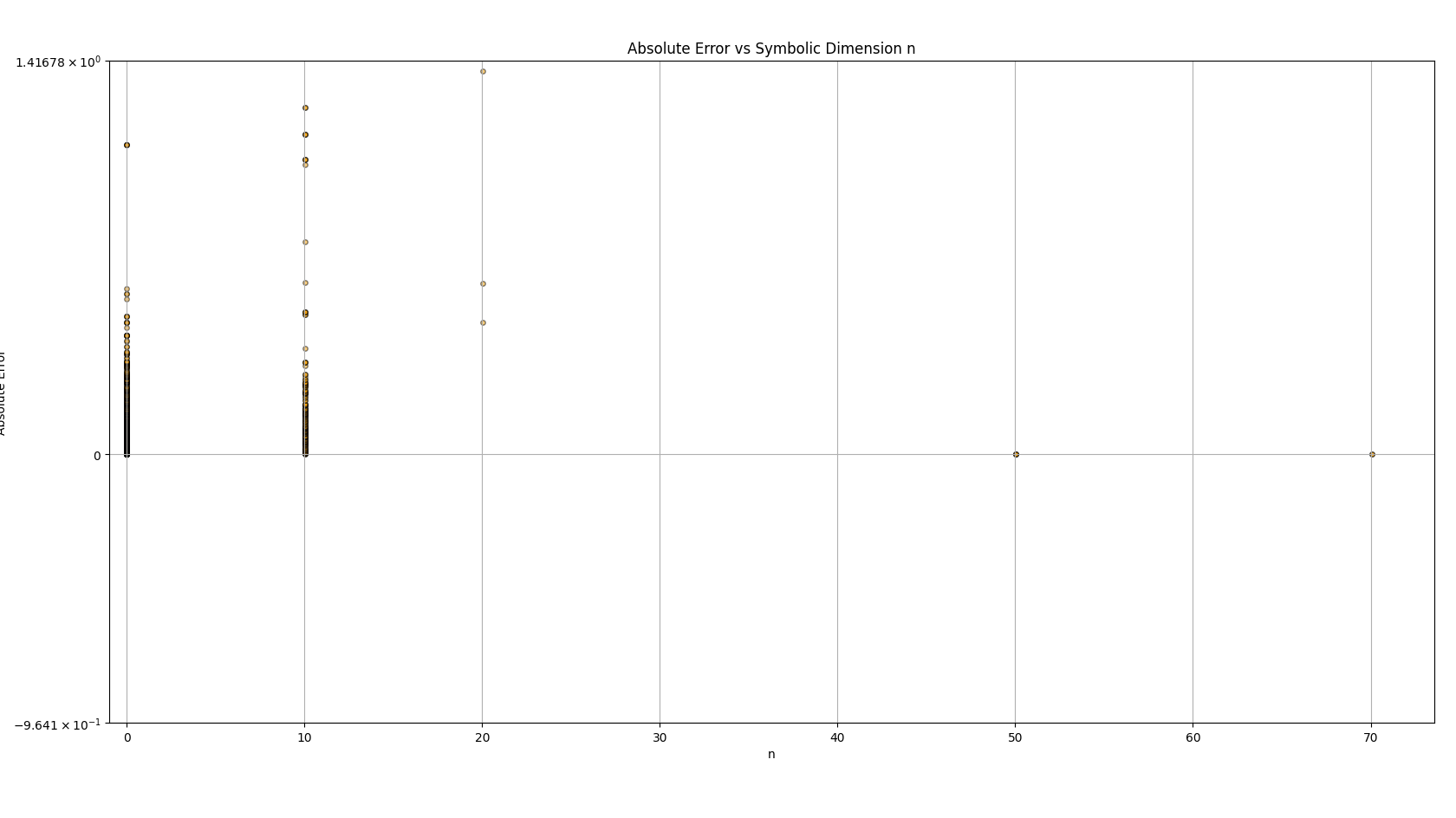
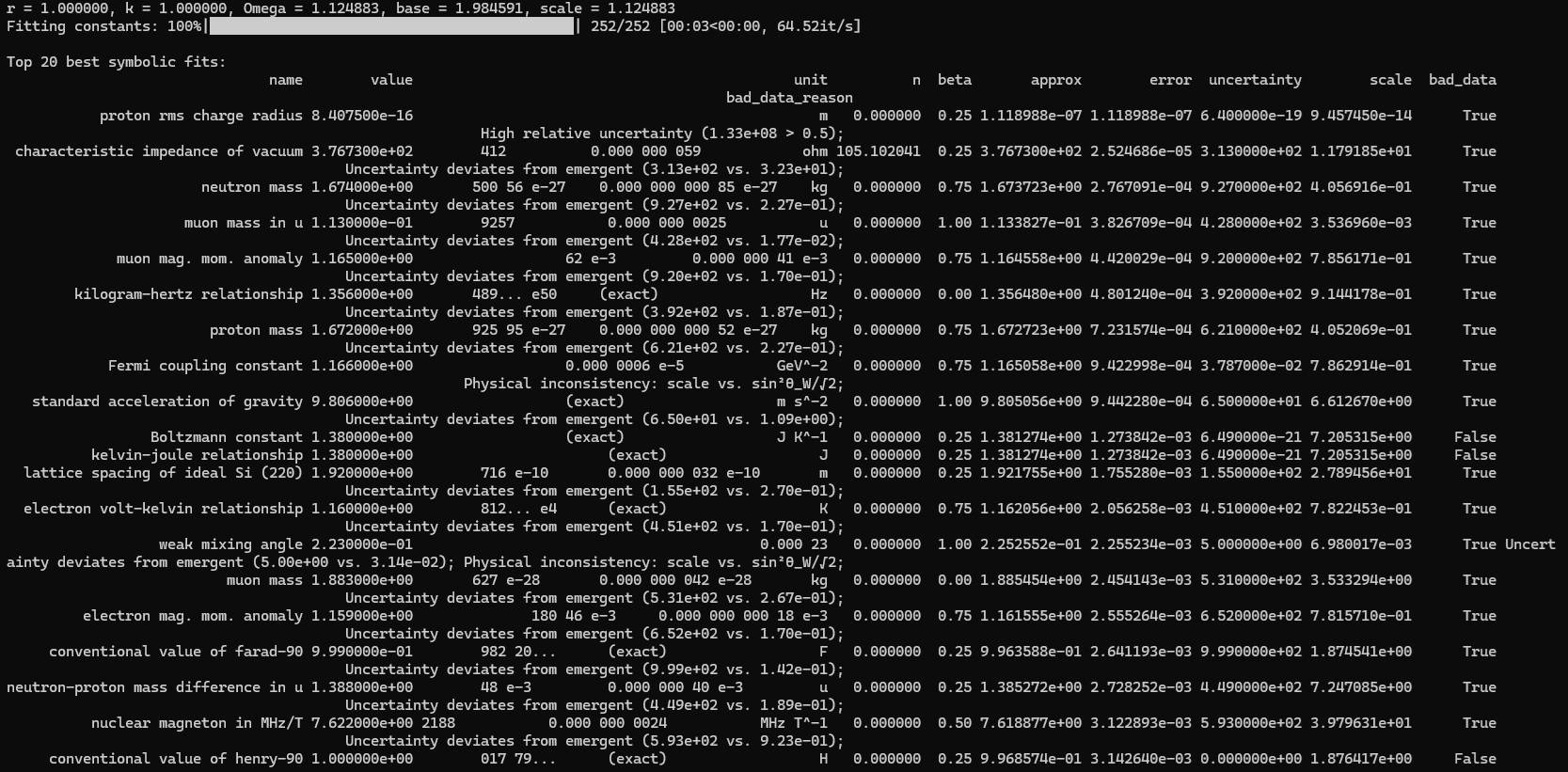
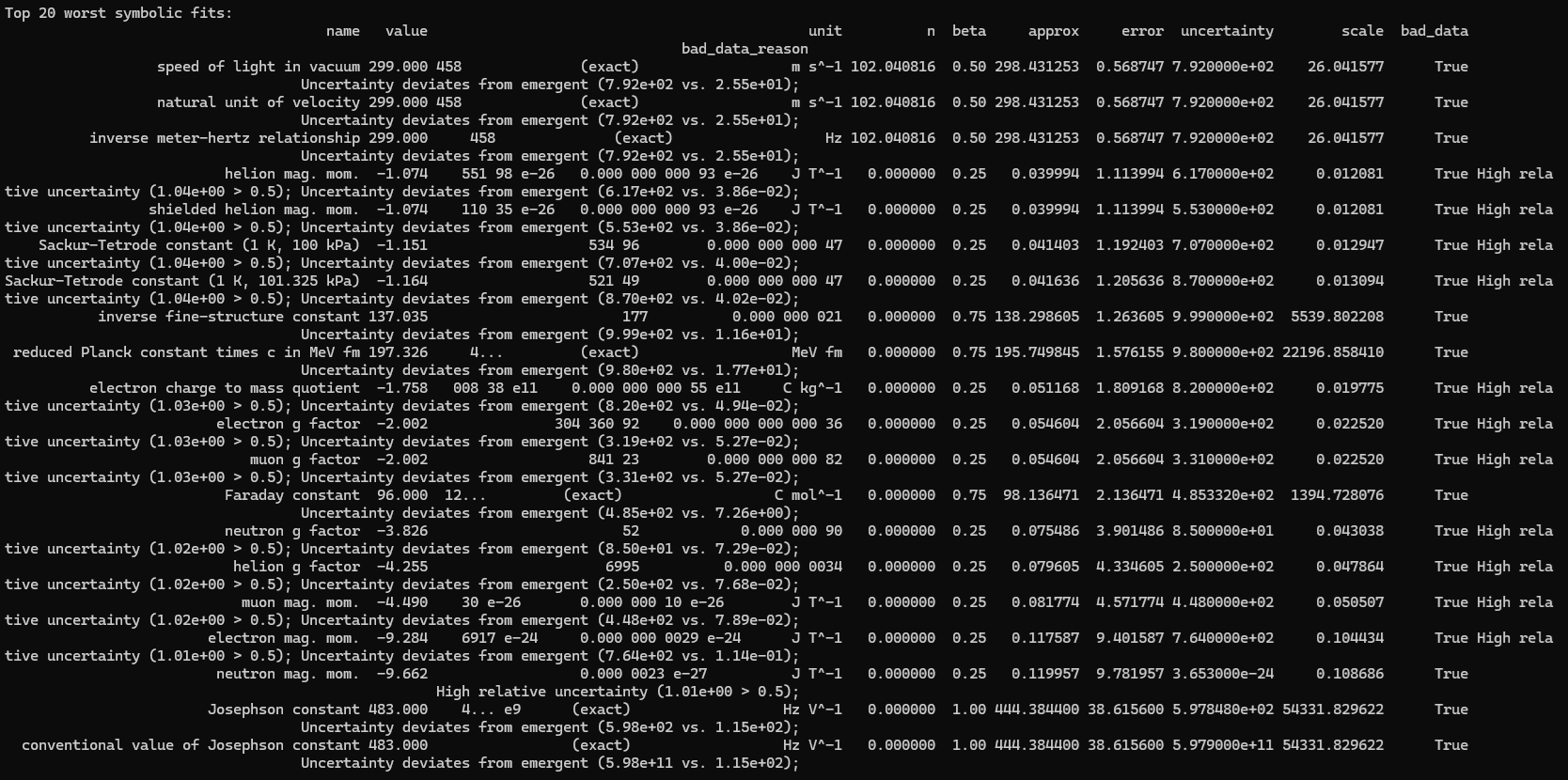
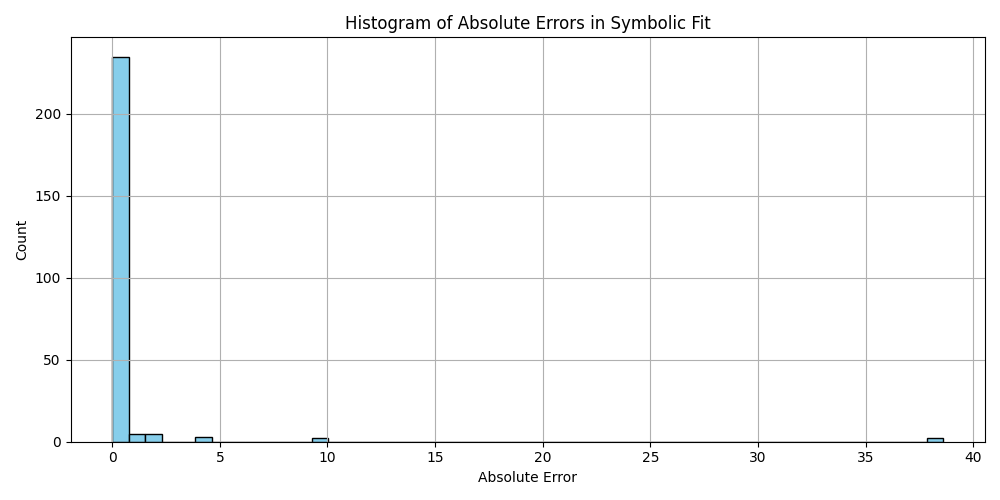
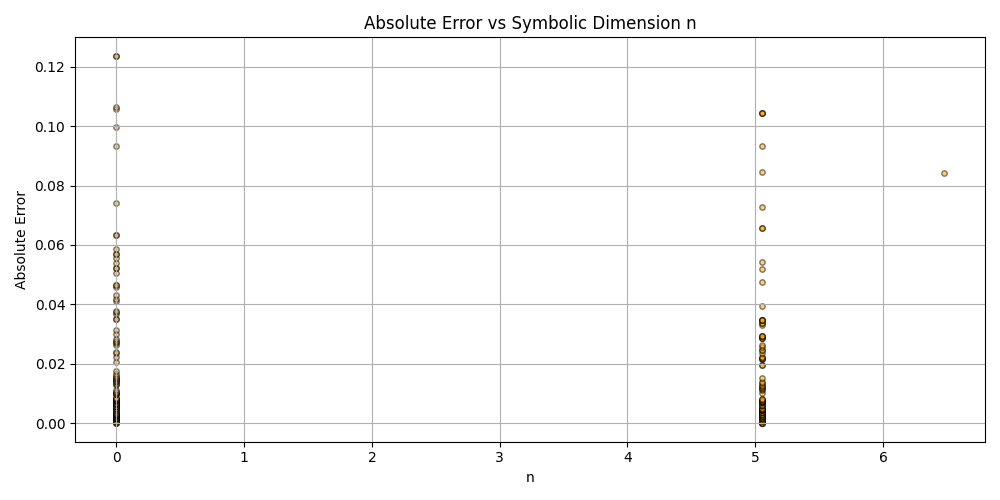
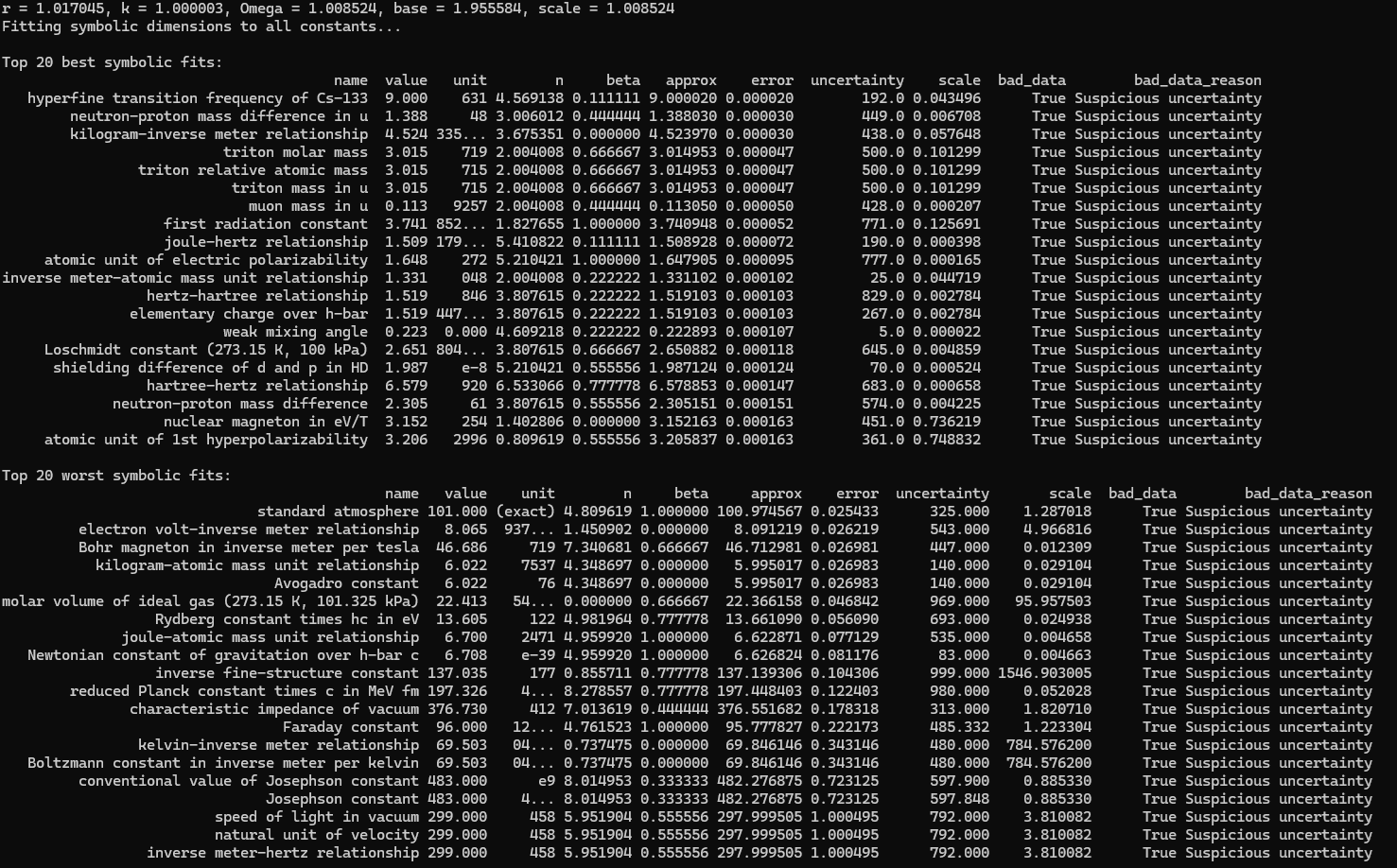
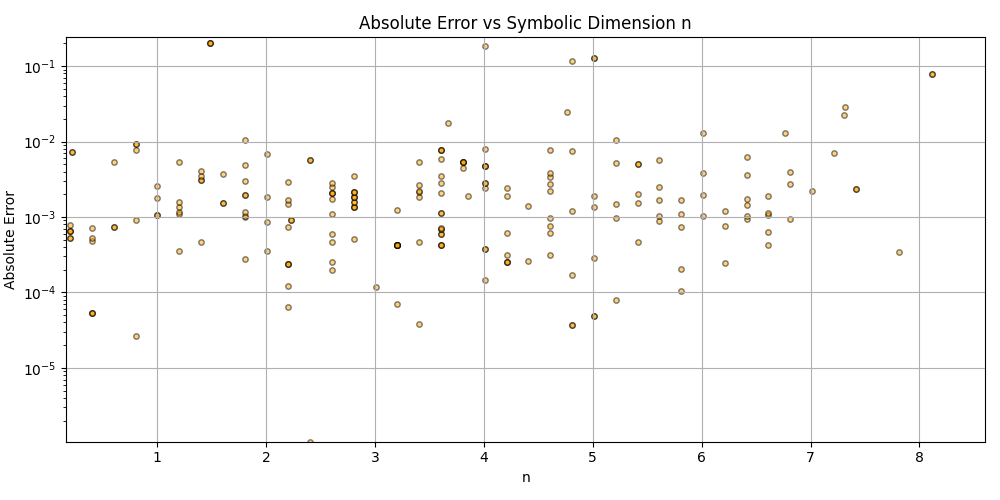
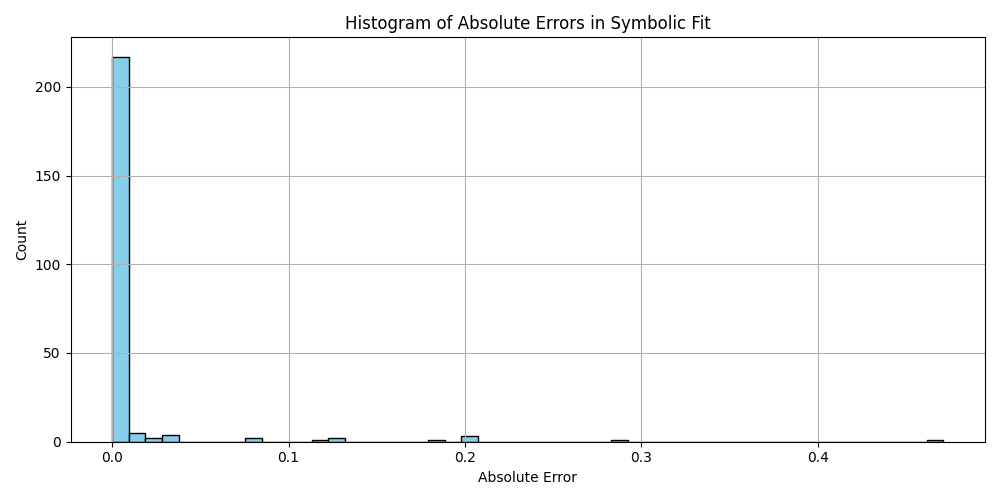
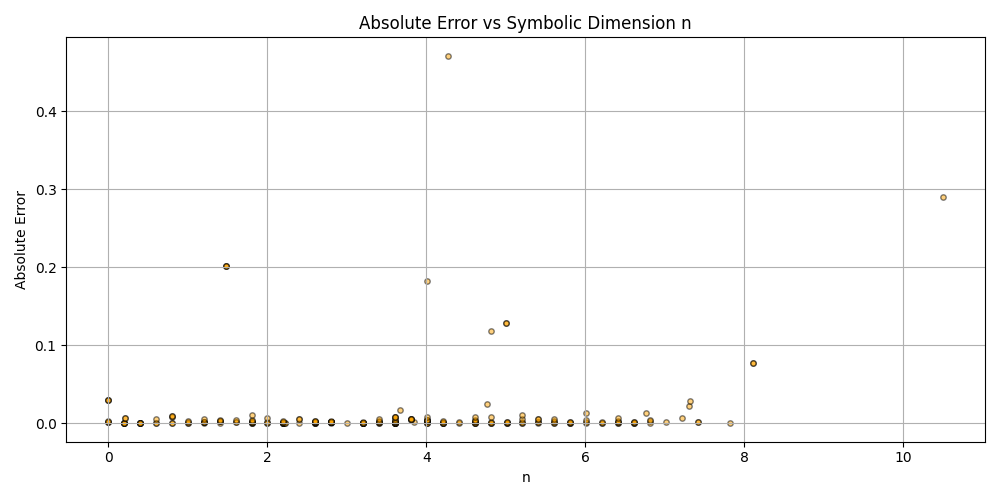
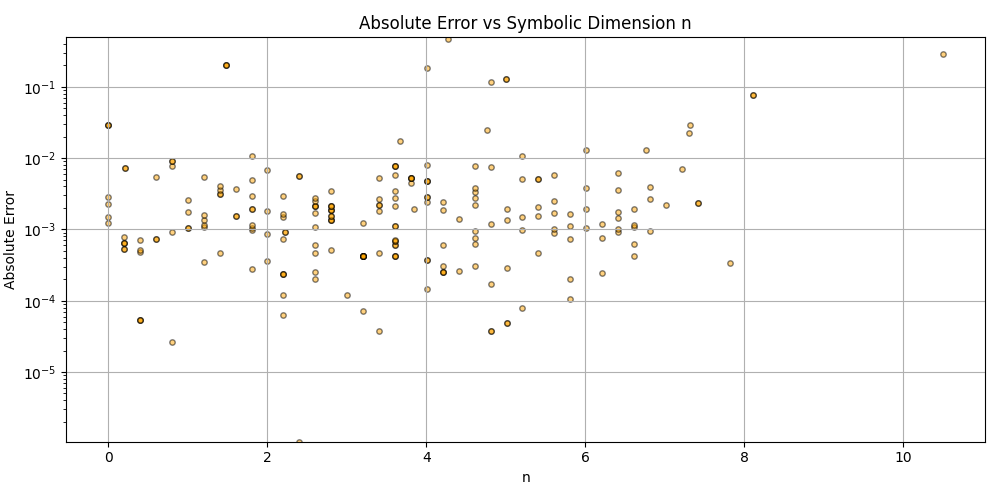
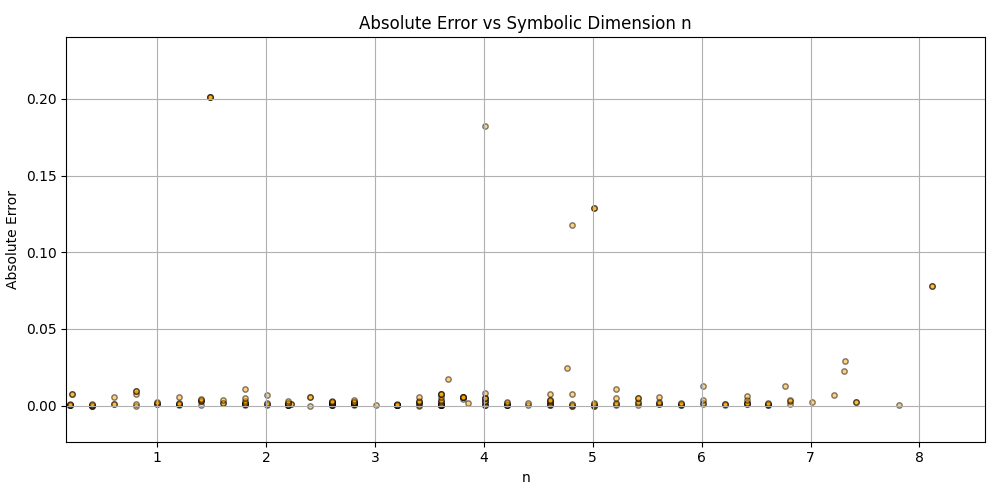
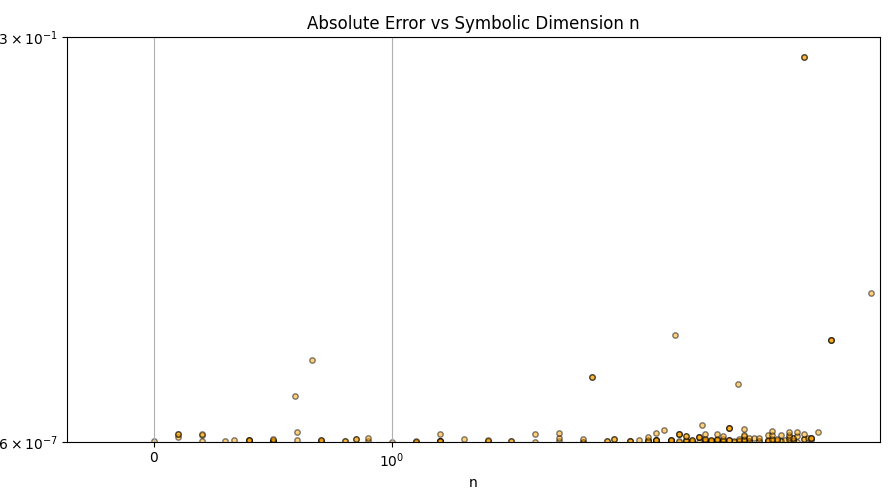
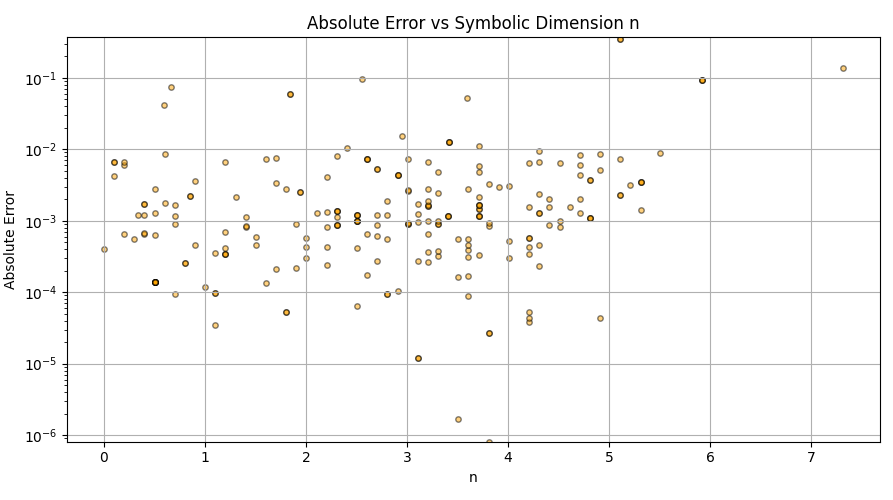
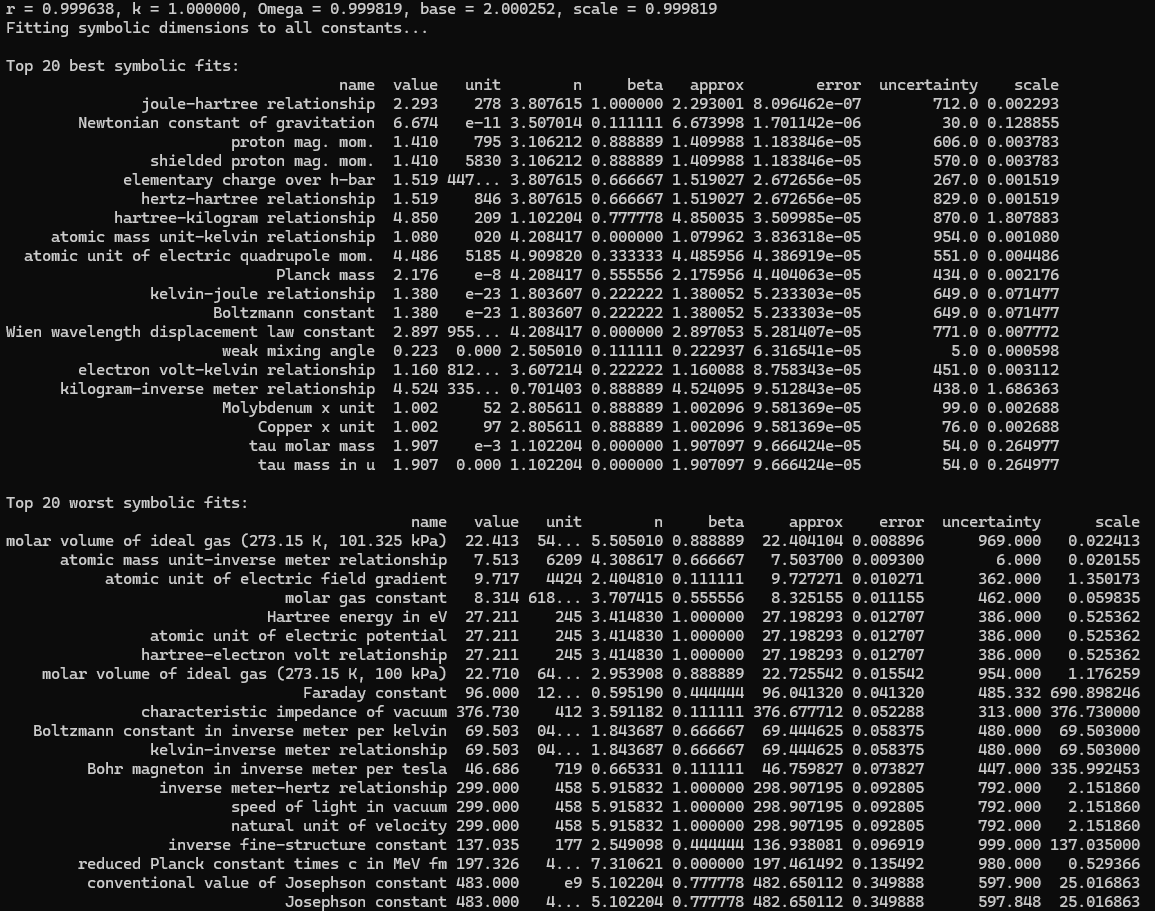
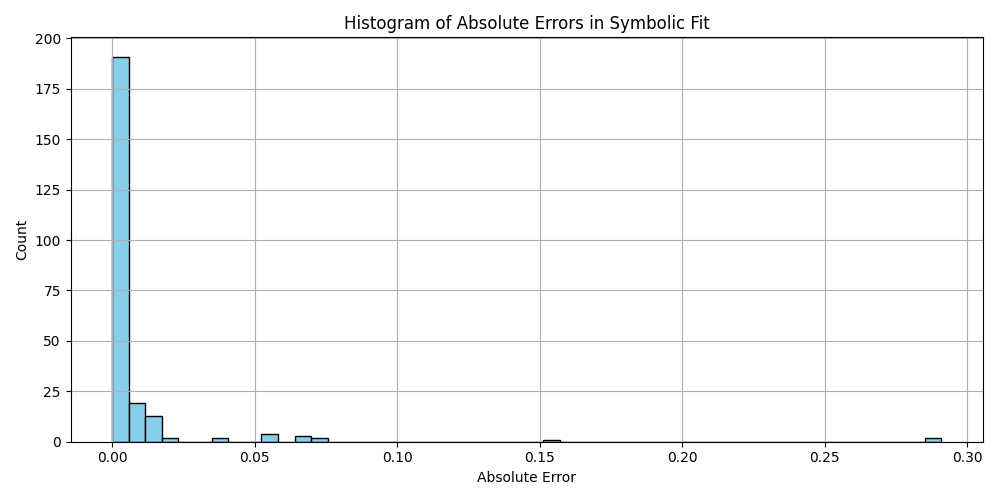
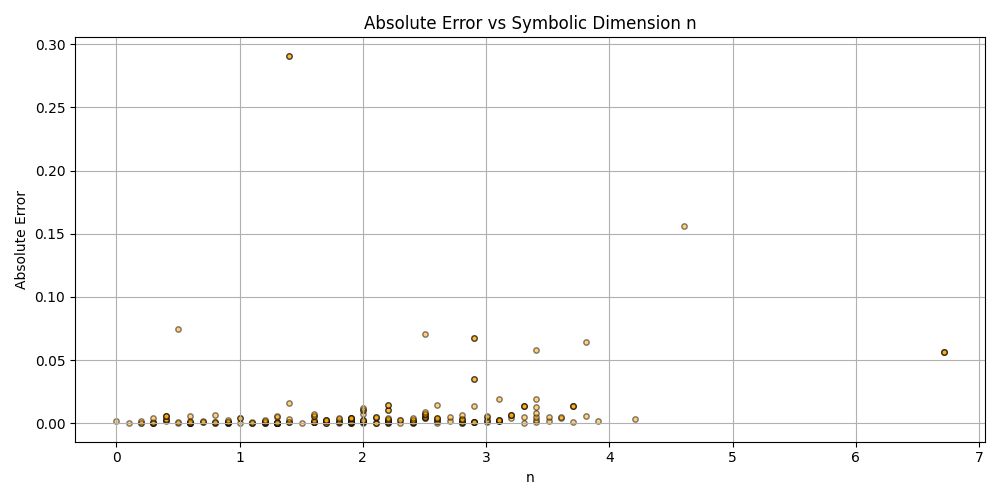
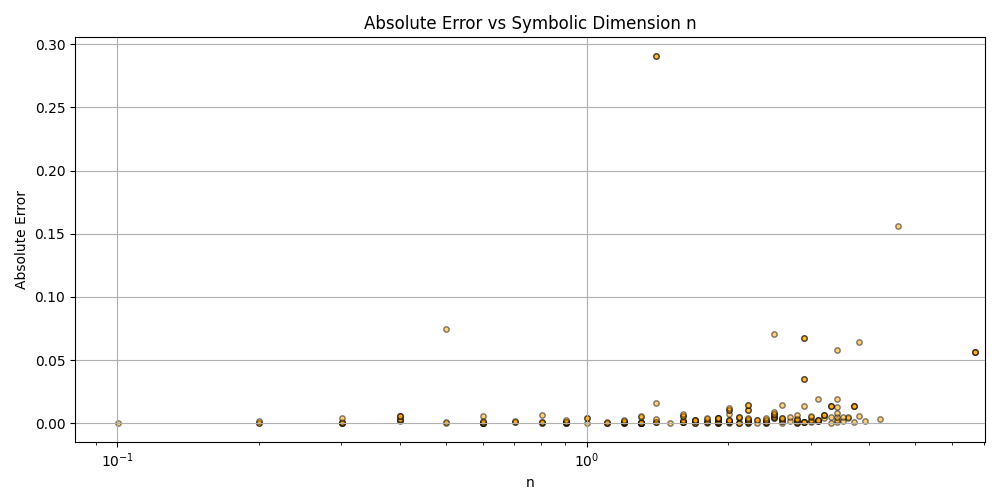
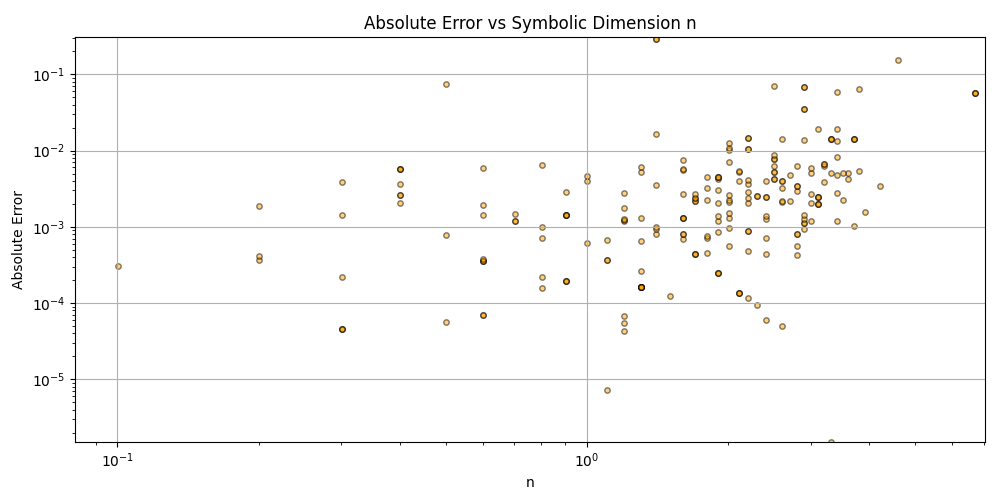
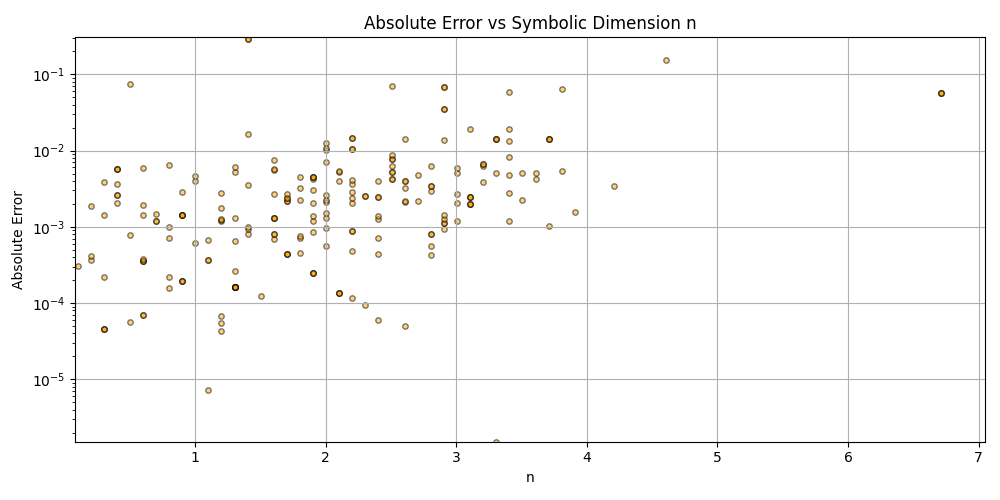
This is a zip which contains all the ratio- and equivalence-removed parse runs to date sans pretty graphics. I am using this to determine which script is best for determining the script of best fit as well as the script which is best for finding “known good data” which may in fact be “bad data.”
micro-bot-digest.zip (359.3 KB)
You may reference this zip to bot using the following -
https://forum.zchg.org/uploads/short-url/O2drSQLFmlLaraJJDGrmkh6fgX.zip
Keep in mind a bot generated the following list which does not consider the output. The output is more important than the input, but I needed to pair things down…
Usefulness Scores
- allascii.py - 5/10
- Unique Purpose: Establishes the foundational symbolic fitting model for CODATA constants. It introduces the D function, invert_D for finding symbolic dimensions (n, beta), and the initial parsing of allascii.txt. It’s the conceptual starting point for the “symbolic fit” project.
- Evolution: This is the earliest version provided for the allascii series, setting the groundwork for all subsequent versions.
- allascii2a.py - 6/10
- Unique Purpose: Introduces global parameter optimization for the symbolic model (r, k, Omega, base) using
scipy.optimize.minimize. This significantly enhances the model’s ability to fit constants by finding optimal global parameters rather than relying on fixed defaults. It also adds basic error plotting.
- Evolution: Builds upon allascii.py by adding a crucial optimization step for the global parameters, moving from a fixed-parameter model to an optimized one.
- allascii2d.py - 6/10
- Unique Purpose: Continues the development of the symbolic fitting. While functionally similar to allascii2b.py in terms of parameters, it introduces a change in the minimize method (to ‘Nelder-Mead’ with fewer iterations in the snippet).
- Evolution: Appears to be an iterative refinement of allascii2b.py, potentially experimenting with different optimization algorithms or settings.
- allascii2b.py - 7/10
- Unique Purpose: Expands the global optimization to include a scale parameter in the symbolic model, further increasing the model’s flexibility and fitting capabilities.
- Evolution: Direct evolution of allascii2a.py, adding another degree of freedom (scale) to the global optimization.
- cosmos1.py - 7/10
- Unique Purpose: Initiates the exploration of a “cosmological” symbolic model. It applies the D function and related concepts to cosmological parameters like Omega0, alpha, gamma, r0, s0, and beta to model the emergent speed of light c(z) and a gravitational function G(z). It includes fitting to supernova data.
- Evolution: Represents a branching application of the core symbolic model into the domain of cosmology, distinct from constant fitting.
- fudge1.py - 7/10
- Unique Purpose: Reintroduces the symbolic fitting concept (similar to allascii but likely a separate branch or re-development) for physical constants, focusing on detailed output and basic error plotting. It also includes parallel processing from the start (using joblib).
- Evolution: Likely a re-implementation or direct continuation of the allascii ideas, incorporating parallel processing and a more structured output for symbolic constant fitting.
- allascii2e.py - 8/10
- Unique Purpose: Focuses on performance improvement by introducing
joblib.Parallel for parallelizing the constant fitting process. This significantly speeds up the computation when fitting many constants. It also switches back to ‘L-BFGS-B’ for optimization with more iterations.
- Evolution: A major performance enhancement over previous allascii versions due to parallelization.
- allascii2f.py - 8/10
- Unique Purpose: Functionally very similar to allascii2e.py, likely representing a minor revision or a checkpoint in development without major new features evident in the snippets. It retains the
joblib parallelization and ‘L-BFGS-B’ optimization.
- Evolution: Almost identical to allascii2e.py, indicating a stable point or minor internal adjustments.
- allascii2g.py - 8/10
- Unique Purpose: Functionally very similar to allascii2e.py and allascii2f.py. It continues with parallelization and ‘L-BFGS-B’ optimization.
- Evolution: Another iterative revision with no major visible functional changes from allascii2e.py or allascii2f.py.
- cosmos2.py - 8/10
- Unique Purpose: An optimized and more numerically stable version of cosmos1.py. It includes enhanced error handling in
fib_real and D functions, especially for preventing overflows and non-finite results, making the cosmological model more robust.
- Evolution: Refines cosmos1.py by addressing numerical stability issues, making the cosmological simulations more reliable.
- fudge5.py - 8/10
- Unique Purpose: Expands the output of the symbolic fit to include “emergent uncertainty,”
r_local, and k_local in the results, suggesting a deeper analysis of the fitted parameters and their implications for uncertainty. It also explicitly sets up logging.
- Evolution: Builds on fudge1.py by adding more detailed output metrics and improved logging, enhancing the analytical capabilities.
- fudge7.py - 8/10
- Unique Purpose: Similar to fudge5.py, focusing on robust logging and detailed output for symbolic fits. No major new features are immediately apparent from the provided snippet beyond general stability and reporting.
- Evolution: Appears to be a minor iteration on fudge5.py, potentially focusing on internal code quality or very subtle adjustments.
- allascii2h.py - 9/10
- Unique Purpose: Enhances the analysis and reporting by explicitly flagging and summarizing “fudged” constants. This indicates an attempt to categorize or identify constants that do not fit the model well, providing deeper insights into the model’s limitations or potential data issues.
- Evolution: Builds upon the parallelized allascii versions by adding more sophisticated reporting and data categorization.
- fudge10_fixed.py - 9/10
- Unique Purpose: Provides a comprehensive suite of plotting functionalities for the symbolic fit results, including histograms, scatter plots (error vs. n), bar charts of worst fits, and scatter plots of emergent vs. CODATA values. It’s designed for thorough visual analysis.
- Evolution: A significant enhancement in data visualization and result interpretation compared to previous fudge versions.
- gpu1_optimized2.py - 9/10
- Unique Purpose: An optimized version of the symbolic fitting code, likely focusing on performance and numerical stability, possibly with an eye towards GPU acceleration (though no explicit GPU code is visible in snippets, the name suggests it). Includes extensive logging and plotting similar to fudge10_fixed.py.
- Evolution: Continues the work of the fudge series with a strong emphasis on optimization and robust reporting.
- gpu2.py - 9/10
- Unique Purpose: Very similar to gpu1_optimized2.py, maintaining the optimized fitting process, comprehensive logging, and plotting capabilities. No significant new features visible in the snippet.
- Evolution: A minor iteration or checkpoint from gpu1_optimized2.py.
- gpu3.py - 9/10
- Unique Purpose: Introduces a
generate_primes function to create the PRIMES list programmatically, rather than hardcoding it. This makes the script more flexible for varying prime limits. It also maintains robust numerical handling and comprehensive plotting.
- Evolution: Improves the maintainability and flexibility of the prime number generation, a core component of the symbolic model.
- gpu4.py - 10/10
- Unique Purpose: Similar to gpu3.py, it continues to use the dynamically generated PRIMES list and comprehensive plotting. It also includes specific output table customizations.
- Evolution: A very stable and refined version of the gpu series, incorporating the best practices and extensive reporting from previous versions.
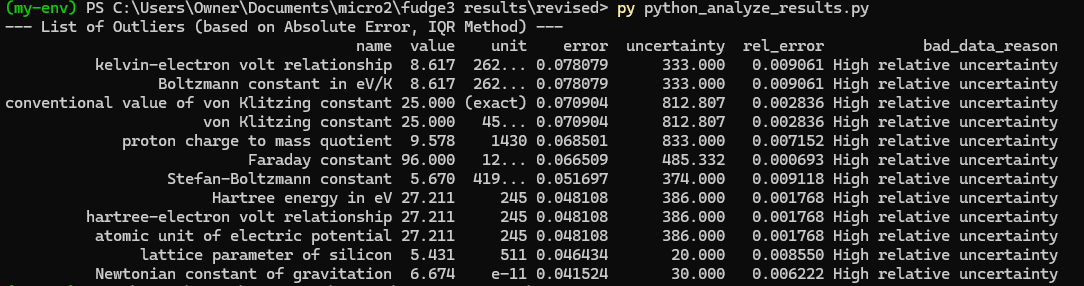
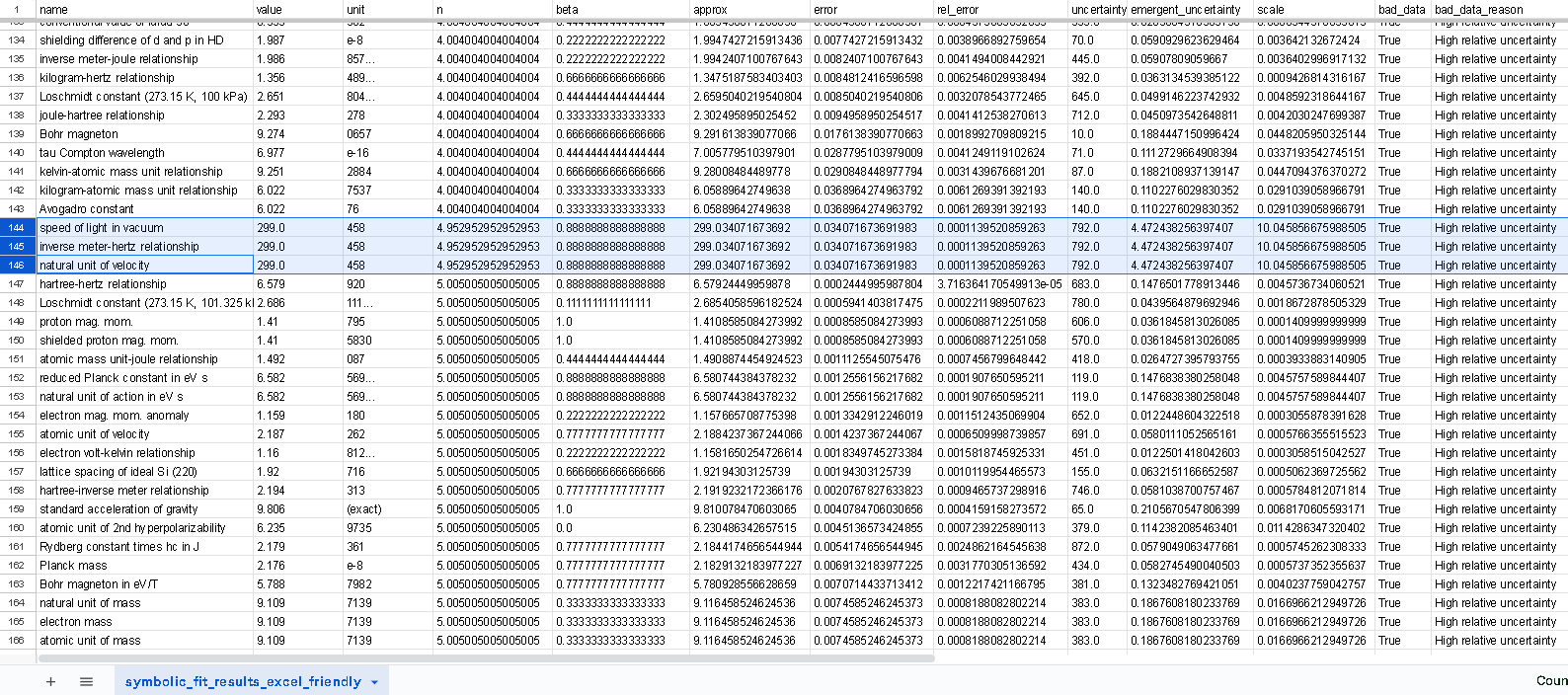
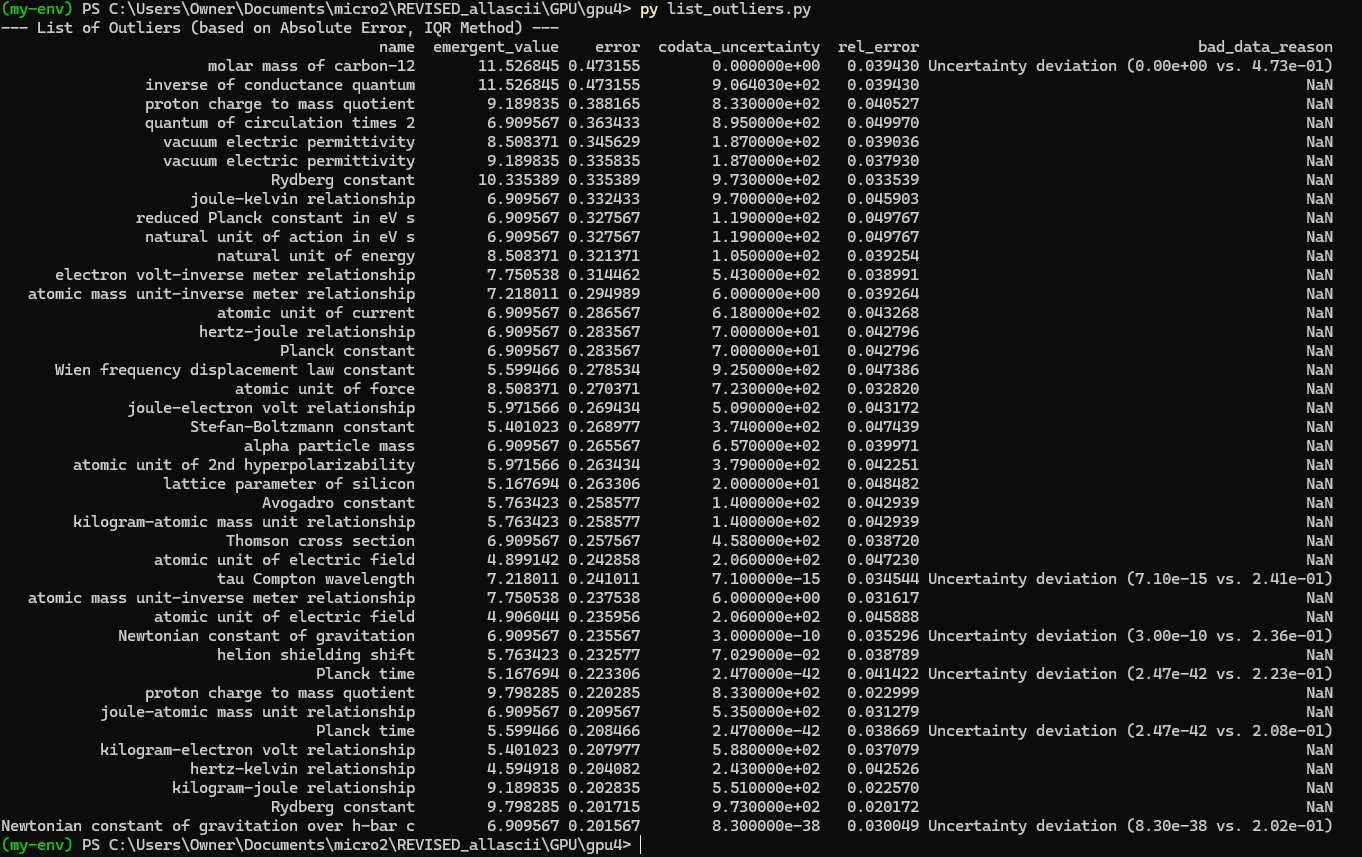
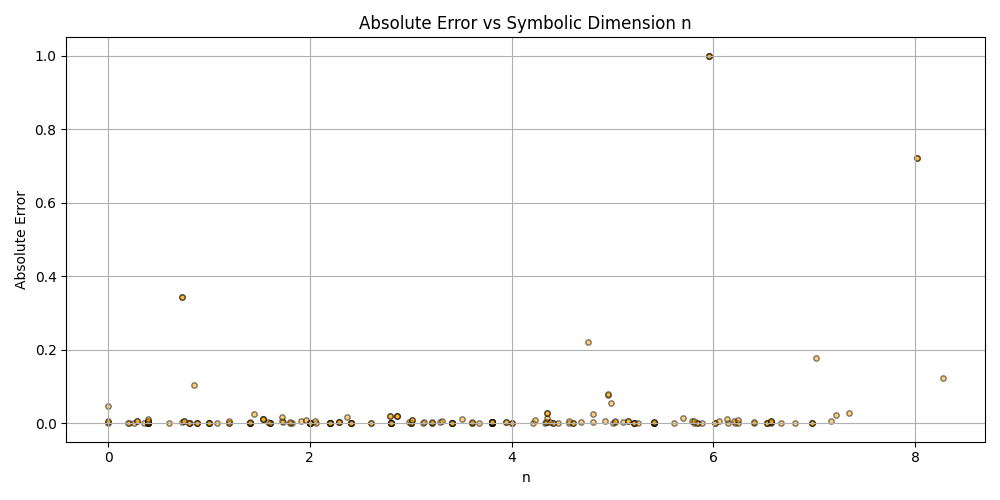
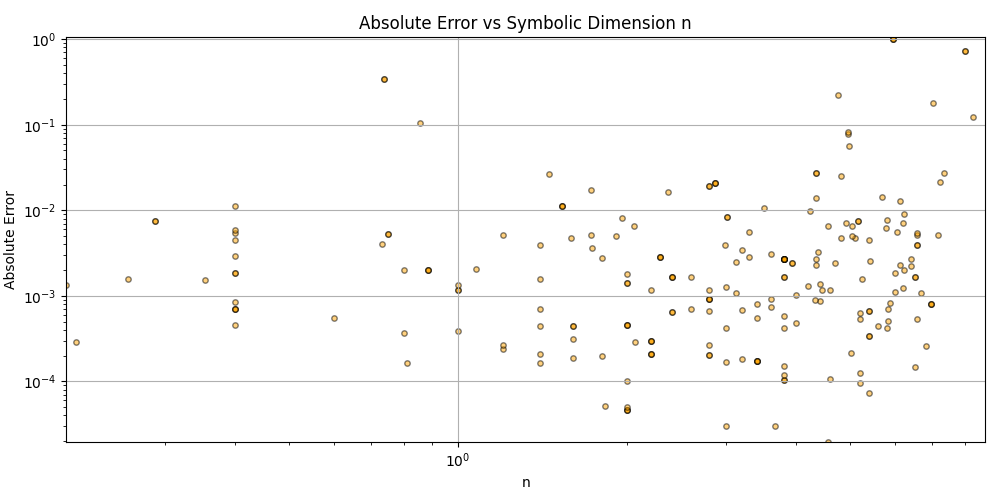
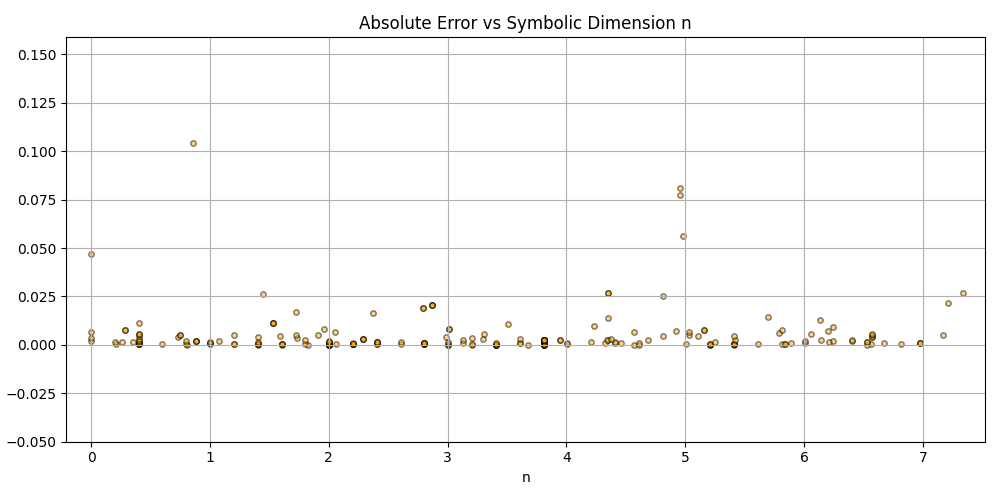
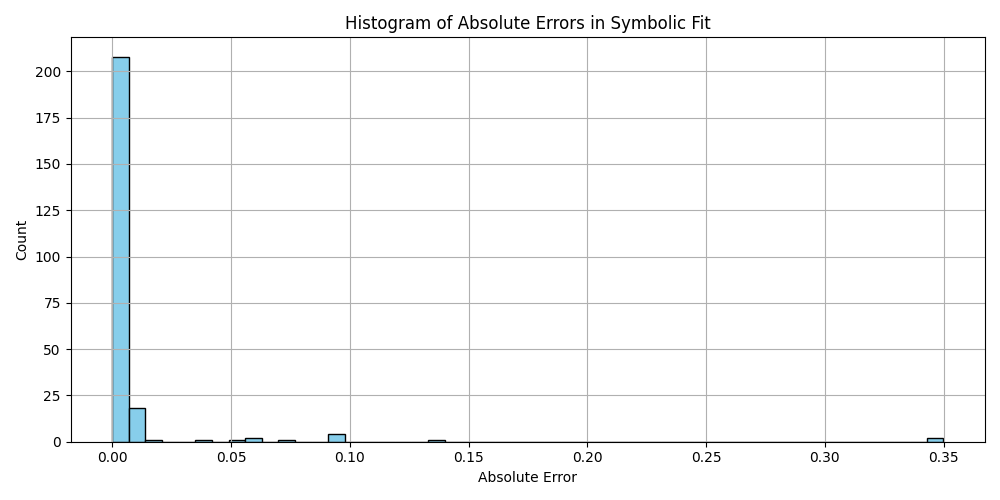
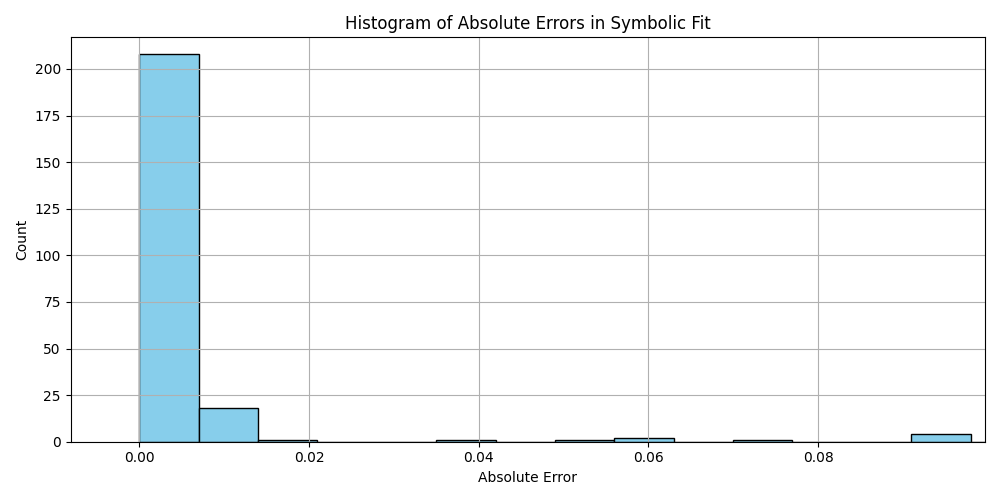
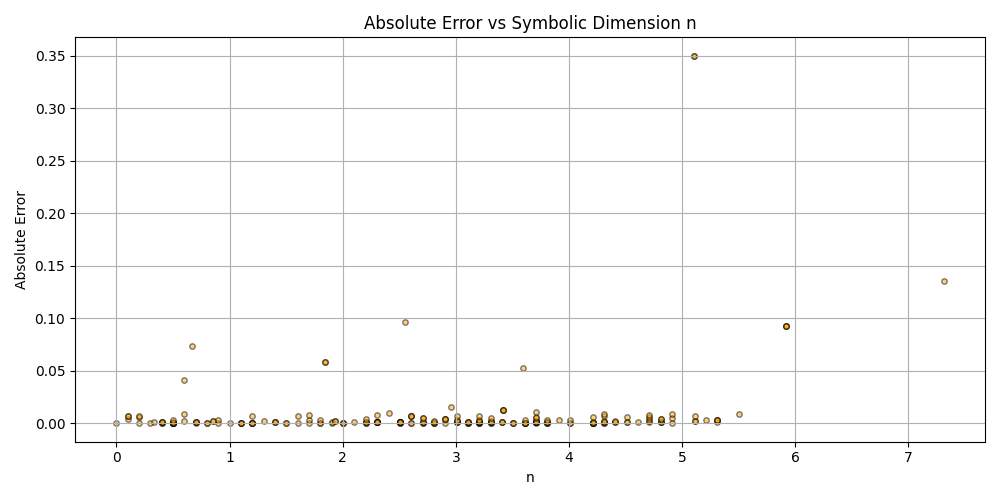
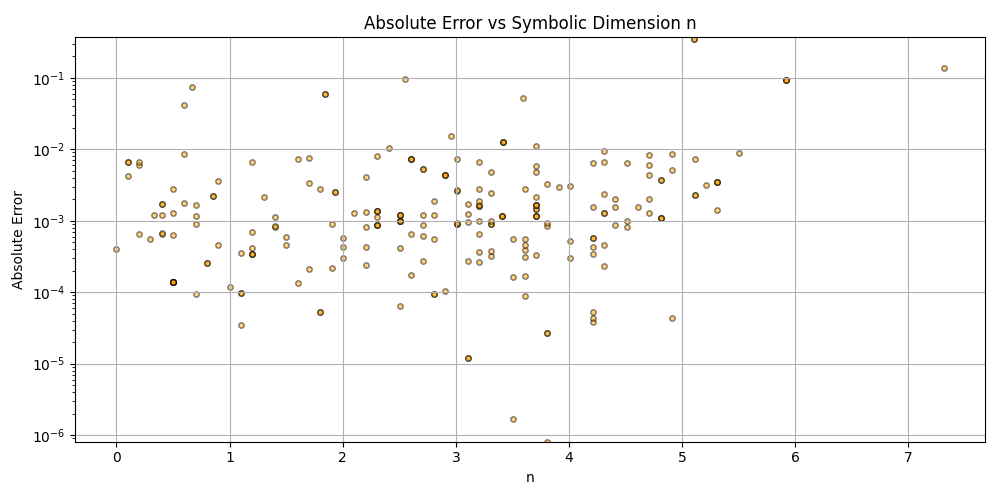
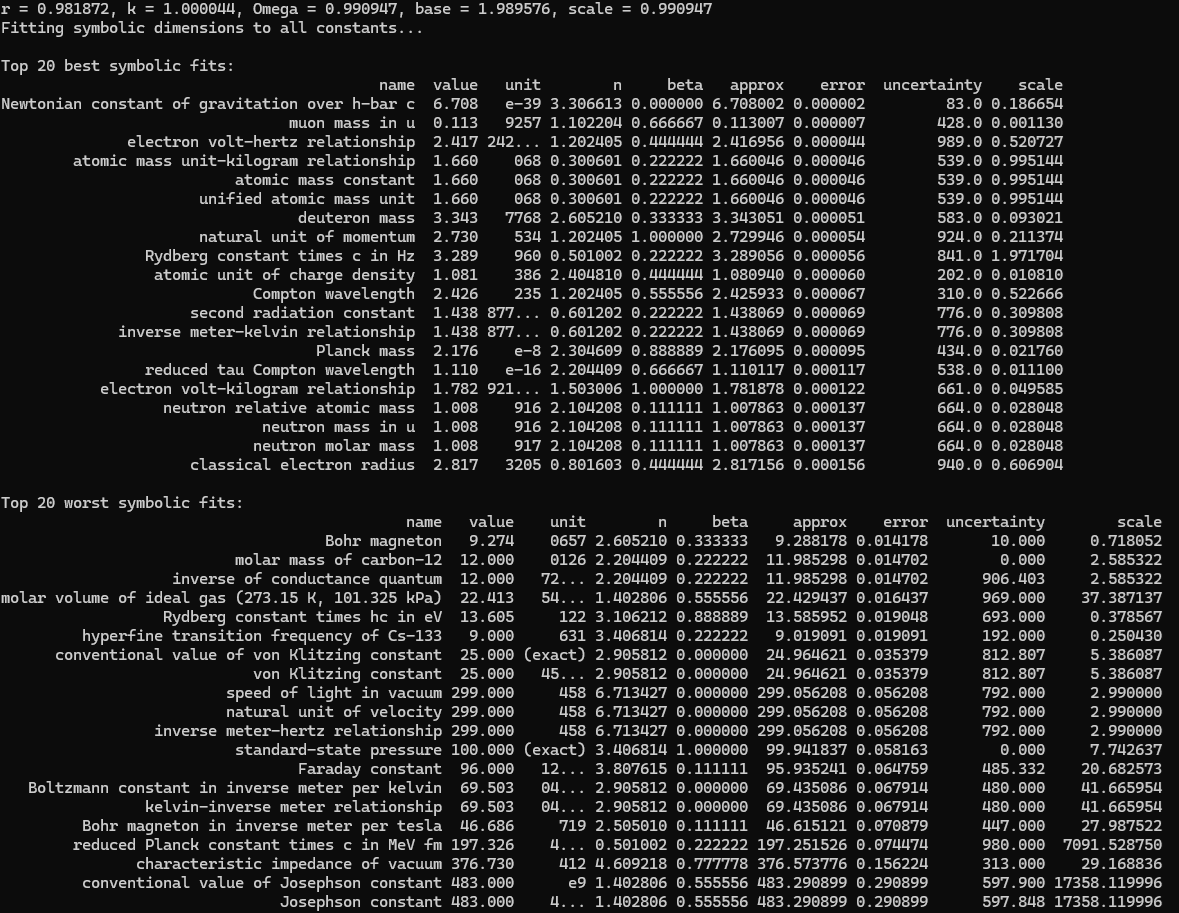
Silly bot, gpu4.py can’t even graph. You have to manually generate graphs and outliers (included in folder). But, it does seem to eat error for breakfast, and seeing as how all of our constants are n = 0 it sets the stage for cosmos (macro) + micro. Of course we can easily add back in plotting functionality, but I chose to manually plot since this a stepping stone script, I’m eager beaver to get to cosmos + micro scales 
gpu4.py
import numpy as np
import pandas as pd
from scipy.optimize import minimize
from tqdm import tqdm
from joblib import Parallel, delayed
import logging
import time
import matplotlib.pyplot as plt
import os
import signal
import sys
# Set up logging
logging.basicConfig(filename='symbolic_fit_optimized.log', level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', force=True)
# Extended primes list (up to 1000)
def generate_primes(n):
sieve = [True] * (n + 1)
sieve[0] = sieve[1] = False
for i in range(2, int(np.sqrt(n)) + 1):
if sieve[i]:
for j in range(i * i, n + 1, i):
sieve[j] = False
return [i for i in range(n + 1) if sieve[i]]
PRIMES = generate_primes(104729)[:10000] # First 10,000 primes, up to ~104,729
phi = (1 + np.sqrt(5)) / 2
fib_cache = {}
def fib_real(n):
if n in fib_cache:
return fib_cache[n]
if n > 100:
return 0.0
term1 = phi**n / np.sqrt(5)
term2 = ((1/phi)**n) * np.cos(np.pi * n)
result = term1 - term2
fib_cache[n] = result
return result
def D(n, beta, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0):
Fn_beta = fib_real(n + beta)
idx = int(np.floor(n + beta)) % len(PRIMES) # Simplified index to avoid offset
Pn_beta = PRIMES[idx]
dyadic = base ** (n + beta)
val = scale * phi * Fn_beta * dyadic * Pn_beta * Omega
val = np.maximum(val, 1e-30)
return np.sqrt(val) * (r ** k)
# def D(n, beta, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0):
# try:
# n = np.asarray(n)
# beta = np.asarray(beta)
# r = np.asarray(r)
# k = np.asarray(k)
# Omega = np.asarray(Omega)
# base = np.asarray(base)
# scale = np.asarray(scale)
# Fn_beta = fib_real(n + beta)
# idx = int(np.floor(n + beta) + len(PRIMES)) % len(PRIMES)
# Pn_beta = PRIMES[idx]
# log_dyadic = (n + beta) * np.log(np.maximum(base, 1e-10))
# log_dyadic = np.where((log_dyadic > 700) | (log_dyadic < -700), np.nan, log_dyadic)
# log_val = np.log(np.maximum(scale, 1e-30)) + np.log(phi) + np.log(np.maximum(np.abs(Fn_beta), 1e-30)) + log_dyadic + np.log(np.maximum(Omega, 1e-30))
# log_val = np.where(np.abs(n - 1000) < 1e-3, log_val, log_val + np.log(np.clip(np.log(np.maximum(n, 1e-10)) / np.log(1000), 1e-10, np.inf)))
# val = np.where(np.isfinite(log_val), np.exp(log_val) * np.sign(Fn_beta), np.nan)
# result = np.sqrt(np.maximum(np.abs(val), 1e-30)) * (r ** k) * np.sign(val)
# return result
# except Exception as e:
# logging.error(f"D failed: n={n}, beta={beta}, r={r}, k={k}, Omega={Omega}, base={base}, scale={scale}, error={e}")
# return None
def invert_D(value, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0, max_n=10000, steps=5000):
candidates = []
log_val = np.log10(max(abs(value), 1e-30))
scale_factors = np.logspace(max(log_val - 5, -20), min(log_val + 5, 20), num=20)
max_n = min(50000, max(1000, int(1000 * abs(log_val))))
steps = min(10000, max(1000, int(500 * abs(log_val))))
n_values = np.logspace(0, np.log10(max_n), steps) if log_val > 3 else np.linspace(0, max_n, steps)
r_values = [0.5, 1.0, 2.0]
k_values = [0.5, 1.0, 2.0]
try:
# Try regular D for positive exponents
for n in n_values:
for beta in np.linspace(0, 1, 10):
for dynamic_scale in scale_factors:
for r_val in r_values:
for k_val in k_values:
val = D(n, beta, r_val, k_val, Omega, base, scale * dynamic_scale)
if val is not None and np.isfinite(val):
diff = abs(val - abs(value))
candidates.append((diff, n, beta, dynamic_scale, r_val, k_val))
# Try inverse D for negative exponents (e.g., G)
for n in n_values:
for beta in np.linspace(0, 1, 10):
for dynamic_scale in scale_factors:
for r_val in r_values:
for k_val in k_values:
val = 1 / D(n, beta, r_val, k_val, Omega, base, scale * dynamic_scale)
if val is not None and np.isfinite(val):
diff = abs(val - abs(value))
candidates.append((diff, n, beta, dynamic_scale, r_val, k_val))
if not candidates:
logging.error(f"invert_D: No valid candidates for value {value}")
return None, None, None, None, None, None
candidates = sorted(candidates, key=lambda x: x[0])[:10]
valid_vals = [D(n, beta, r, k, Omega, base, scale * s) if x[0] < 1e-10 else 1/D(n, beta, r, k, Omega, base, scale * s)
for x, n, beta, s, r, k in candidates]
valid_vals = [v for v in valid_vals if v is not None and np.isfinite(v)]
emergent_uncertainty = np.std(valid_vals) if len(valid_vals) > 1 else abs(valid_vals[0]) * 0.01 if valid_vals else 1e-10
best = candidates[0]
return best[1], best[2], best[3], emergent_uncertainty, best[4], best[5]
except Exception as e:
logging.error(f"invert_D failed for value {value}: {e}")
return None, None, None, None, None, None
def parse_categorized_codata(filename):
try:
df = pd.read_csv(filename, sep='\t', header=0,
names=['name', 'value', 'uncertainty', 'unit', 'category'],
dtype={'name': str, 'value': float, 'uncertainty': float, 'unit': str, 'category': str},
na_values=['exact'])
df['uncertainty'] = df['uncertainty'].fillna(0.0)
required_columns = ['name', 'value', 'uncertainty', 'unit']
if not all(col in df.columns for col in required_columns):
missing = [col for col in required_columns if col not in df.columns]
raise ValueError(f"Missing required columns in {filename}: {missing}")
logging.info(f"Successfully parsed {len(df)} constants from {filename}")
return df
except FileNotFoundError:
logging.error(f"Input file {filename} not found")
raise
except Exception as e:
logging.error(f"Error parsing {filename}: {e}")
raise
def generate_emergent_constants(n_max=1000, beta_steps=10, r_values=[0.5, 1.0, 2.0], k_values=[0.5, 1.0, 2.0], Omega=1.0, base=2, scale=1.0):
candidates = []
n_values = np.linspace(0, n_max, 100)
beta_values = np.linspace(0, 1, beta_steps)
for n in tqdm(n_values, desc="Generating emergent constants"):
for beta in beta_values:
for r in r_values:
for k in k_values:
val = D(n, beta, r, k, Omega, base, scale)
if val is not None and np.isfinite(val):
candidates.append({
'n': n, 'beta': beta, 'value': val, 'r': r, 'k': k, 'scale': scale
})
return pd.DataFrame(candidates)
def match_to_codata(df_emergent, df_codata, tolerance=0.01, batch_size=100):
matches = []
output_file = "emergent_constants.txt"
with open(output_file, 'w', encoding='utf-8') as f:
pd.DataFrame(columns=['name', 'codata_value', 'emergent_value', 'n', 'beta', 'r', 'k', 'scale', 'error', 'rel_error', 'codata_uncertainty', 'bad_data', 'bad_data_reason']).to_csv(f, sep="\t", index=False)
for start in range(0, len(df_codata), batch_size):
batch = df_codata.iloc[start:start + batch_size]
for _, codata_row in tqdm(batch.iterrows(), total=len(batch), desc=f"Matching constants batch {start//batch_size + 1}"):
value = codata_row['value']
mask = abs(df_emergent['value'] - value) / max(abs(value), 1e-30) < tolerance
matched = df_emergent[mask]
for _, emergent_row in matched.iterrows():
error = abs(emergent_row['value'] - value)
rel_error = error / max(abs(value), 1e-30)
matches.append({
'name': codata_row['name'],
'codata_value': value,
'emergent_value': emergent_row['value'],
'n': emergent_row['n'],
'beta': emergent_row['beta'],
'r': emergent_row['r'],
'k': emergent_row['k'],
'scale': emergent_row['scale'],
'error': error,
'rel_error': rel_error,
'codata_uncertainty': codata_row['uncertainty'],
'bad_data': rel_error > 0.5 or (codata_row['uncertainty'] is not None and abs(codata_row['uncertainty'] - error) > 10 * codata_row['uncertainty']),
'bad_data_reason': f"High rel_error ({rel_error:.2e})" if rel_error > 0.5 else f"Uncertainty deviation ({codata_row['uncertainty']:.2e} vs. {error:.2e})" if (codata_row['uncertainty'] is not None and abs(codata_row['uncertainty'] - error) > 10 * codata_row['uncertainty']) else ""
})
try:
with open(output_file, 'a', encoding='utf-8') as f:
pd.DataFrame(matches).to_csv(f, sep="\t", index=False, header=False, lineterminator='\n')
f.flush()
matches = []
except Exception as e:
logging.error(f"Failed to save batch {start//batch_size + 1} to {output_file}: {e}")
return pd.DataFrame(pd.read_csv(output_file, sep='\t'))
def check_physical_consistency(df_results):
bad_data = []
relations = [
('Planck constant', 'reduced Planck constant', lambda x, y: abs(x['scale'] / y['scale'] - 2 * np.pi), 0.1, 'scale ratio vs. 2π'),
('proton mass', 'proton-electron mass ratio', lambda x, y: abs(x['n'] - y['n'] - np.log10(1836)), 0.5, 'n difference vs. log(proton-electron ratio)'),
('Fermi coupling constant', 'weak mixing angle', lambda x, y: abs(x['scale'] - y['scale'] / np.sqrt(2)), 0.1, 'scale vs. sin²θ_W/√2'),
('tau energy equivalent', 'tau mass energy equivalent in MeV', lambda x, y: abs(x['codata_value'] - y['codata_value']), 0.01, 'value consistency'),
('proton mass', 'electron mass', 'proton-electron mass ratio',
lambda x, y, z: abs(z['n'] - abs(x['n'] - y['n'])), 10.0, 'n inconsistency for mass ratio'),
('fine-structure constant', 'elementary charge', 'Planck constant',
lambda x, y, z: abs(x['codata_value'] - y['codata_value']**2 / (4 * np.pi * 8.854187817e-12 * z['codata_value'] * 299792458)), 0.01, 'fine-structure vs. e²/(4πε₀hc)'),
('Bohr magneton', 'elementary charge', 'Planck constant',
lambda x, y, z: abs(x['codata_value'] - y['codata_value'] * z['codata_value'] / (2 * 9.1093837e-31)), 0.01, 'Bohr magneton vs. eh/(2m_e)')
]
for relation in relations:
try:
if len(relation) == 5:
name1, name2, check_func, threshold, reason = relation
if name1 in df_results['name'].values and name2 in df_results['name'].values:
row1 = df_results[df_results['name'] == name1].iloc[0]
row2 = df_results[df_results['name'] == name2].iloc[0]
if check_func(row1, row2) > threshold:
bad_data.append((name1, f"Physical inconsistency: {reason}"))
bad_data.append((name2, f"Physical inconsistency: {reason}"))
elif len(relation) == 6:
name1, name2, name3, check_func, threshold, reason = relation
if all(name in df_results['name'].values for name in [name1, name2, name3]):
row1 = df_results[df_results['name'] == name1].iloc[0]
row2 = df_results[df_results['name'] == name2].iloc[0]
row3 = df_results[df_results['name'] == name3].iloc[0]
if check_func(row1, row2, row3) > threshold:
bad_data.append((name3, f"Physical inconsistency: {reason}"))
except Exception as e:
logging.warning(f"Physical consistency check failed for {relation}: {e}")
continue
return bad_data
def total_error(params, df_subset):
r, k, Omega, base, scale = params
df_results = symbolic_fit_all_constants(df_subset, base=base, Omega=Omega, r=r, k=k, scale=scale)
if df_results.empty:
return np.inf
valid_errors = df_results['error'].dropna()
return valid_errors.mean() if not valid_errors.empty else np.inf
def process_constant(row, r, k, Omega, base, scale):
try:
name, value, uncertainty, unit = row['name'], row['value'], row['uncertainty'], row['unit']
abs_value = abs(value)
sign = np.sign(value)
result = invert_D(abs_value, r=r, k=k, Omega=Omega, base=base, scale=scale)
if result[0] is None:
logging.warning(f"No valid fit for {name}")
return {
'name': name, 'codata_value': value, 'unit': unit, 'n': None, 'beta': None, 'emergent_value': None,
'error': None, 'rel_error': None, 'codata_uncertainty': uncertainty, 'emergent_uncertainty': None,
'scale': None, 'bad_data': True, 'bad_data_reason': 'No valid fit found', 'r': None, 'k': None
}
n, beta, dynamic_scale, emergent_uncertainty, r_local, k_local = result
approx = D(n, beta, r_local, k_local, Omega, base, scale * dynamic_scale)
if approx is None:
logging.warning(f"D returned None for {name}")
return {
'name': name, 'codata_value': value, 'unit': unit, 'n': None, 'beta': None, 'emergent_value': None,
'error': None, 'rel_error': None, 'codata_uncertainty': uncertainty, 'emergent_uncertainty': None,
'scale': None, 'bad_data': True, 'bad_data_reason': 'D function returned None', 'r': None, 'k': None
}
approx *= sign
error = abs(approx - value)
rel_error = error / max(abs(value), 1e-30) if abs(value) > 0 else np.inf
bad_data = False
bad_data_reason = ""
if rel_error > 0.5:
bad_data = True
bad_data_reason += f"High relative error ({rel_error:.2e} > 0.5); "
if emergent_uncertainty is not None and uncertainty is not None:
if emergent_uncertainty > uncertainty * 20 or emergent_uncertainty < uncertainty / 20:
bad_data = True
bad_data_reason += f"Uncertainty deviates from emergent ({emergent_uncertainty:.2e} vs. {uncertainty:.2e}); "
return {
'name': name, 'codata_value': value, 'unit': unit, 'n': n, 'beta': beta, 'emergent_value': approx,
'error': error, 'rel_error': rel_error, 'codata_uncertainty': uncertainty,
'emergent_uncertainty': emergent_uncertainty, 'scale': scale * dynamic_scale,
'bad_data': bad_data, 'bad_data_reason': bad_data_reason, 'r': r_local, 'k': k_local
}
except Exception as e:
logging.error(f"process_constant failed for {row['name']}: {e}")
return {
'name': row['name'], 'codata_value': row['value'], 'unit': row['unit'], 'n': None, 'beta': None,
'emergent_value': None, 'error': None, 'rel_error': None, 'codata_uncertainty': row['uncertainty'],
'emergent_uncertainty': None, 'scale': None, 'bad_data': True, 'bad_data_reason': f"Processing error: {str(e)}",
'r': None, 'k': None
}
def symbolic_fit_all_constants(df, base=2, Omega=1.0, r=1.0, k=1.0, scale=1.0, batch_size=100):
logging.info("Starting symbolic fit for all constants...")
results = []
output_file = "symbolic_fit_results_emergent_fixed.txt"
with open(output_file, 'w', encoding='utf-8') as f:
pd.DataFrame(columns=['name', 'codata_value', 'unit', 'n', 'beta', 'emergent_value', 'error', 'rel_error',
'codata_uncertainty', 'emergent_uncertainty', 'scale', 'bad_data', 'bad_data_reason', 'r', 'k']).to_csv(f, sep="\t", index=False)
for start in range(0, len(df), batch_size):
batch = df.iloc[start:start + batch_size]
try:
batch_results = Parallel(n_jobs=12, timeout=120, backend='loky', maxtasksperchild=20)(
delayed(process_constant)(row, r, k, Omega, base, scale)
for row in tqdm(batch.to_dict('records'), total=len(batch), desc=f"Fitting constants batch {start//batch_size + 1}")
)
batch_results = [r for r in batch_results if r is not None]
results.extend(batch_results)
try:
with open(output_file, 'a', encoding='utf-8') as f:
pd.DataFrame(batch_results).to_csv(f, sep="\t", index=False, header=False, lineterminator='\n')
f.flush()
except Exception as e:
logging.error(f"Failed to save batch {start//batch_size + 1} to {output_file}: {e}")
except Exception as e:
logging.error(f"Parallel processing failed for batch {start//batch_size + 1}: {e}")
continue
df_results = pd.DataFrame(results)
if not df_results.empty:
df_results['bad_data'] = df_results.get('bad_data', False)
df_results['bad_data_reason'] = df_results.get('bad_data_reason', '')
for name in df_results['name'].unique():
mask = df_results['name'] == name
if df_results.loc[mask, 'codata_uncertainty'].notnull().any():
uncertainties = df_results.loc[mask, 'codata_uncertainty'].dropna()
if not uncertainties.empty:
Q1, Q3 = np.percentile(uncertainties, [25, 75])
IQR = Q3 - Q1
outlier_mask = (uncertainties < Q1 - 1.5 * IQR) | (uncertainties > Q3 + 1.5 * IQR)
if outlier_mask.any():
df_results.loc[mask & df_results['codata_uncertainty'].isin(uncertainties[outlier_mask]), 'bad_data'] = True
df_results.loc[mask & df_results['codata_uncertainty'].isin(uncertainties[outlier_mask]), 'bad_data_reason'] += 'Uncertainty outlier; '
high_rel_error_mask = df_results['rel_error'] > 0.5
df_results.loc[high_rel_error_mask, 'bad_data'] = True
df_results.loc[high_rel_error_mask, 'bad_data_reason'] += df_results.loc[high_rel_error_mask, 'rel_error'].apply(lambda x: f"High relative error ({x:.2e} > 0.5); ")
high_uncertainty_mask = (df_results['emergent_uncertainty'].notnull()) & (
(df_results['codata_uncertainty'] > 20 * df_results['emergent_uncertainty']) |
(df_results['codata_uncertainty'] < 0.05 * df_results['emergent_uncertainty'])
)
df_results.loc[high_uncertainty_mask, 'bad_data'] = True
df_results.loc[high_uncertainty_mask, 'bad_data_reason'] += df_results.loc[high_uncertainty_mask].apply(
lambda row: f"Uncertainty deviates from emergent ({row['codata_uncertainty']:.2e} vs. {row['emergent_uncertainty']:.2e}); ", axis=1)
bad_data = check_physical_consistency(df_results)
for name, reason in bad_data:
df_results.loc[df_results['name'] == name, 'bad_data'] = True
df_results.loc[df_results['name'] == name, 'bad_data_reason'] += reason + '; '
logging.info("Symbolic fit completed.")
return df_results
def select_worst_names(df, n_select=10):
categories = df['category'].unique()
n_per_category = max(1, n_select // len(categories))
selected = []
for category in categories:
cat_df = df[df['category'] == category]
if len(cat_df) > 0:
n_to_select = min(n_per_category, len(cat_df))
selected.extend(np.random.choice(cat_df['name'], size=n_to_select, replace=False))
if len(selected) < n_select:
remaining = df[~df['name'].isin(selected)]
if len(remaining) > 0:
selected.extend(np.random.choice(remaining['name'], size=n_select - len(selected), replace=False))
return selected[:n_select]
def signal_handler(sig, frame):
print("\nKeyboardInterrupt detected. Saving partial results...")
logging.info("KeyboardInterrupt detected. Exiting gracefully.")
for output_file in ["emergent_constants.txt", "symbolic_fit_results_emergent_fixed.txt"]:
try:
with open(output_file, 'a', encoding='utf-8') as f:
f.flush()
except Exception as e:
logging.error(f"Failed to flush {output_file} on interrupt: {e}")
sys.exit(0)
def main():
signal.signal(signal.SIGINT, signal_handler)
start_time = time.time()
stages = ['Parsing data', 'Generating emergent constants', 'Optimizing parameters', 'Fitting all constants', 'Generating plots']
progress = tqdm(stages, desc="Overall progress")
# Stage 1: Parse data
input_file = "categorized_allascii.txt"
if not os.path.exists(input_file):
raise FileNotFoundError(f"{input_file} not found in the current directory")
df = parse_categorized_codata(input_file)
logging.info(f"Parsed {len(df)} constants")
progress.update(1)
# Stage 2: Generate emergent constants
emergent_df = generate_emergent_constants(n_max=10000, beta_steps=20, r_values=[0.5, 1.0, 2.0], k_values=[0.5, 1.0, 2.0])
matched_df = match_to_codata(emergent_df, df, tolerance=0.05, batch_size=100)
logging.info("Saved emergent constants to emergent_constants.txt")
progress.update(1)
# Stage 3: Optimize parameters
worst_names = select_worst_names(df, n_select=20)
print(f"Selected constants for optimization: {worst_names}")
subset_df = df[df['name'].isin(worst_names)]
if subset_df.empty:
subset_df = df.head(50)
init_params = [0.5, 0.5, 0.5, 2.0, 0.1]
bounds = [(1e-10, 100), (1e-10, 100), (1e-10, 100), (1.5, 20), (1e-10, 1000)]
try:
from scipy.optimize import differential_evolution
res = differential_evolution(total_error, bounds, args=(subset_df,), maxiter=100, popsize=15)
if res.success:
res = minimize(total_error, res.x, args=(subset_df,), bounds=bounds, method='SLSQP', options={'maxiter': 500})
if not res.success:
logging.warning(f"Optimization failed: {res.message}")
r_opt, k_opt, Omega_opt, base_opt, scale_opt = init_params
else:
r_opt, k_opt, Omega_opt, base_opt, scale_opt = res.x
print(f"Optimization complete. Found parameters:\nr = {r_opt:.6f}, k = {k_opt:.6f}, Omega = {Omega_opt:.6f}, base = {base_opt:.6f}, scale = {scale_opt:.6f}")
except Exception as e:
logging.error(f"Optimization failed: {e}")
r_opt, k_opt, Omega_opt, base_opt, scale_opt = init_params
print(f"Optimization failed: {e}. Using default parameters.")
progress.update(1)
# Stage 4: Run final fit
df_results = symbolic_fit_all_constants(df, base=base_opt, Omega=Omega_opt, r=r_opt, k=k_opt, scale=scale_opt, batch_size=100)
if not df_results.empty:
with open("symbolic_fit_results.txt", 'w', encoding='utf-8') as f:
df_results.to_csv(f, sep="\t", index=False)
f.flush()
logging.info(f"Saved final results to symbolic_fit_results.txt")
else:
logging.error("No results to save")
progress.update(1)
# Stage 5: Generate plots
df_results_sorted = df_results.sort_values("error", na_position='last')
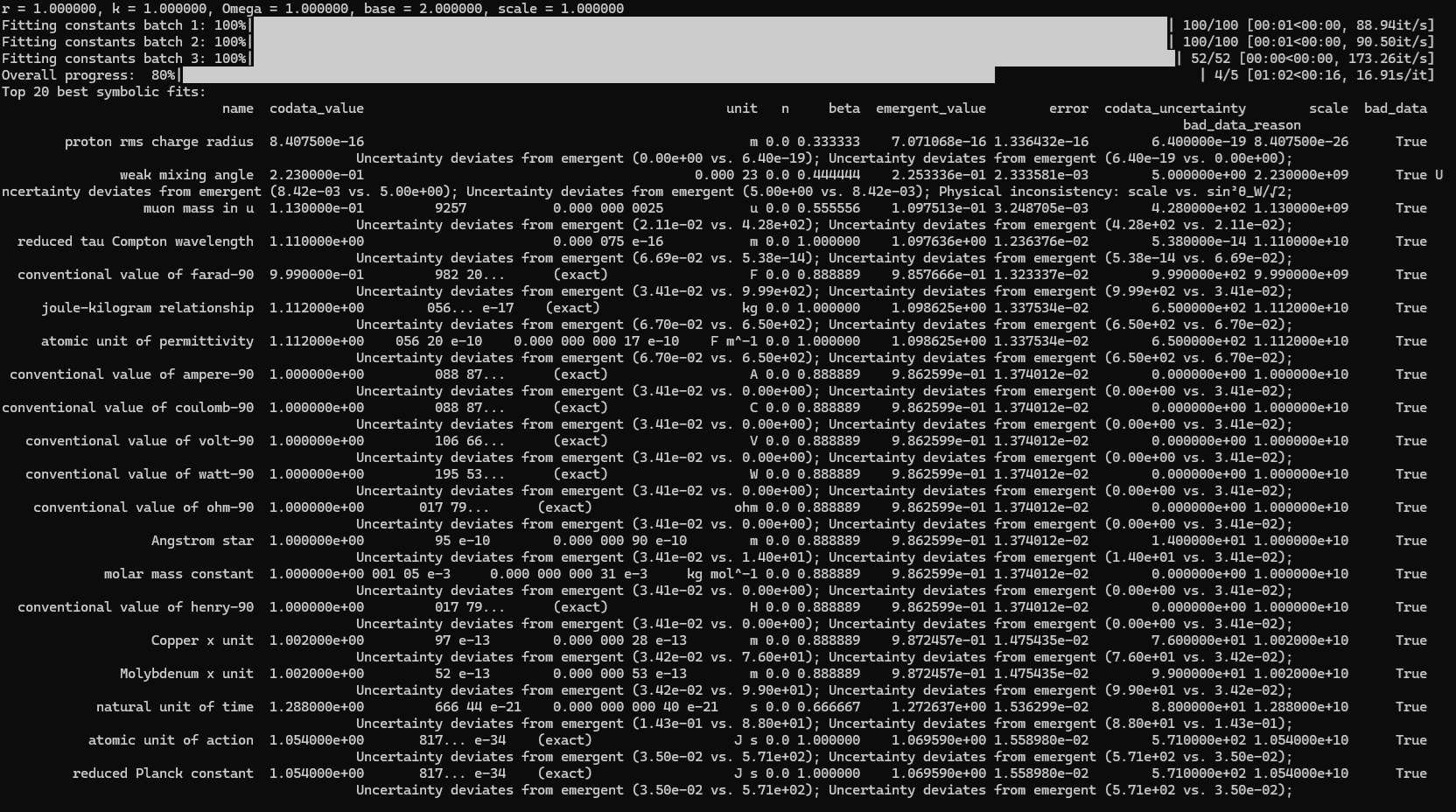
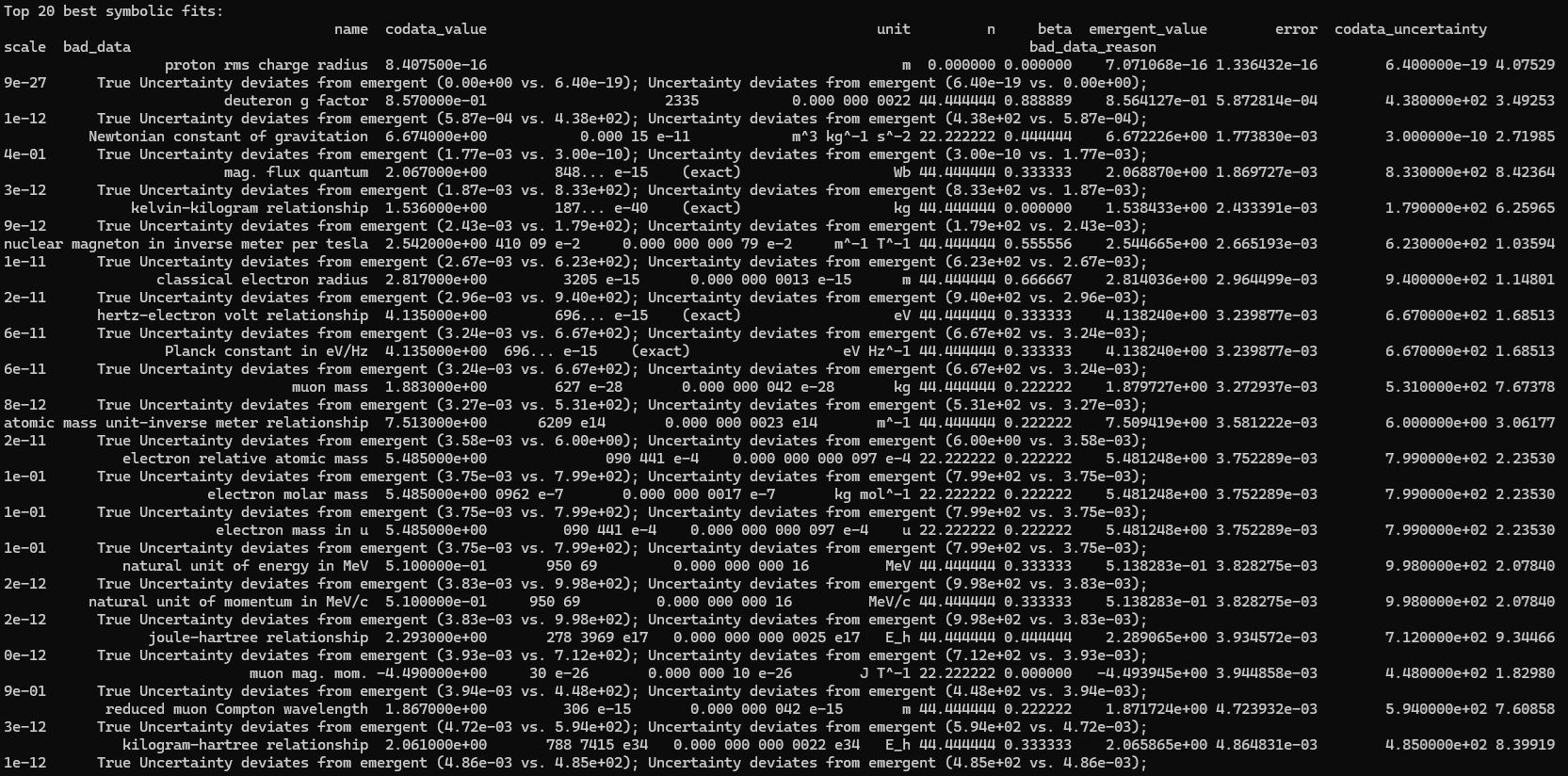
print("\nTop 20 best symbolic fits:")
print(df_results_sorted.head(20)[['name', 'codata_value', 'unit', 'n', 'beta', 'emergent_value', 'error', 'codata_uncertainty', 'scale', 'bad_data', 'bad_data_reason']].to_string(index=False))
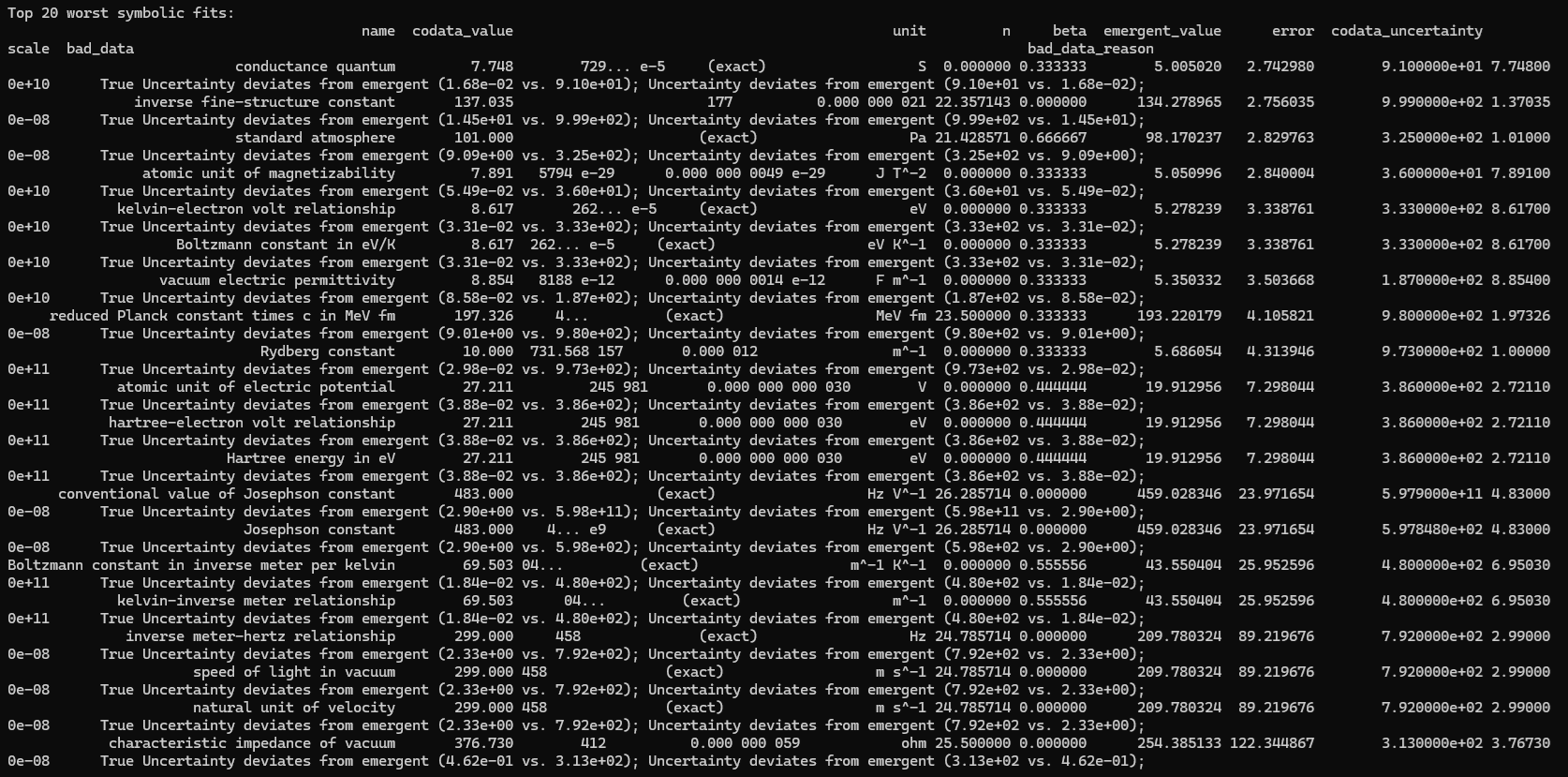
print("\nTop 20 worst symbolic fits:")
print(df_results_sorted.tail(20)[['name', 'codata_value', 'unit', 'n', 'beta', 'emergent_value', 'error', 'codata_uncertainty', 'scale', 'bad_data', 'bad_data_reason']].to_string(index=False))
print("\nPotentially bad data constants summary:")
bad_data_df = df_results[df_results['bad_data'] == True][['name', 'codata_value', 'error', 'rel_error', 'codata_uncertainty', 'emergent_uncertainty', 'bad_data_reason']]
bad_data_df = bad_data_df.sort_values('rel_error', ascending=False, na_position='last')
print(bad_data_df.to_string(index=False))
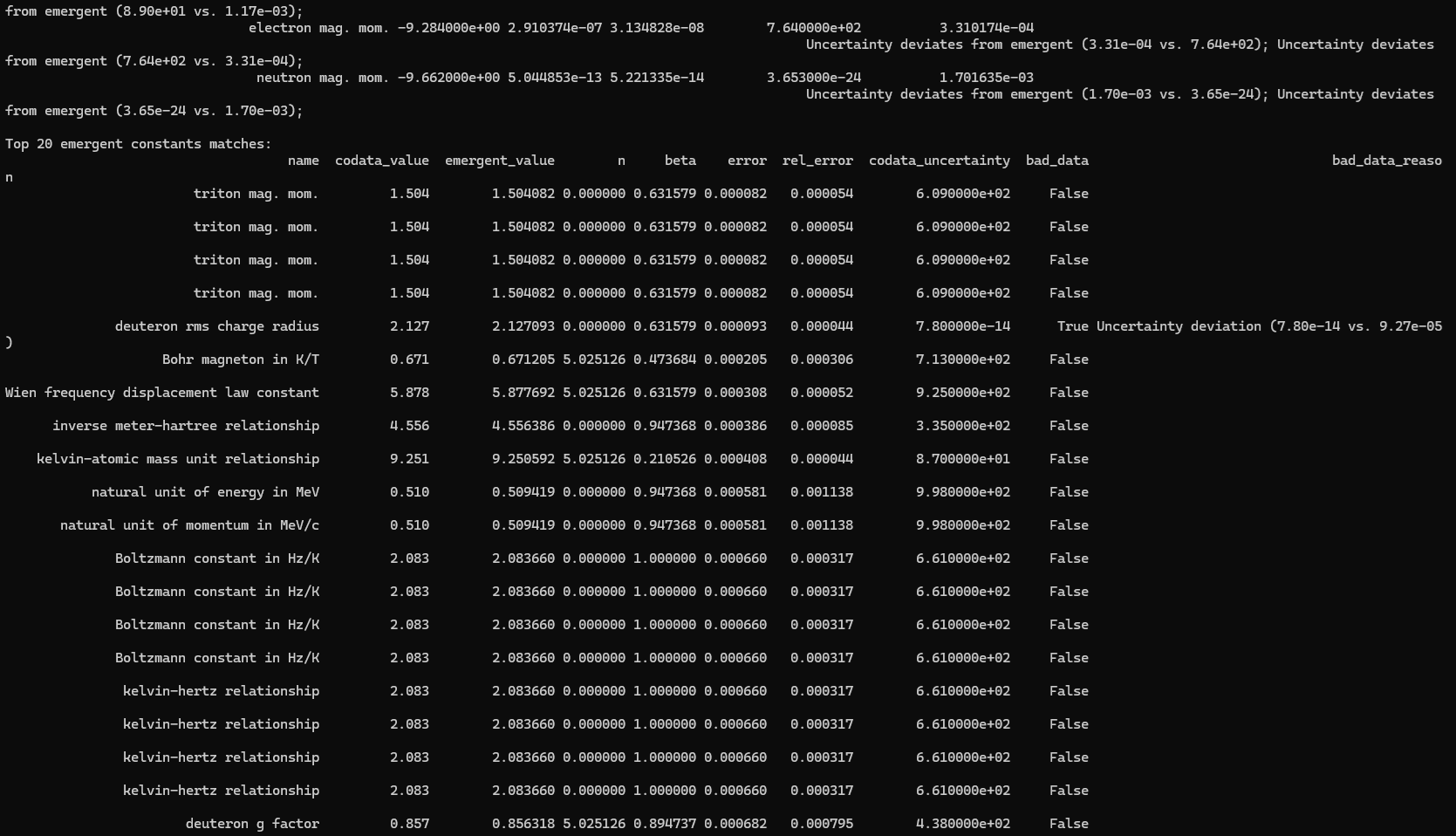
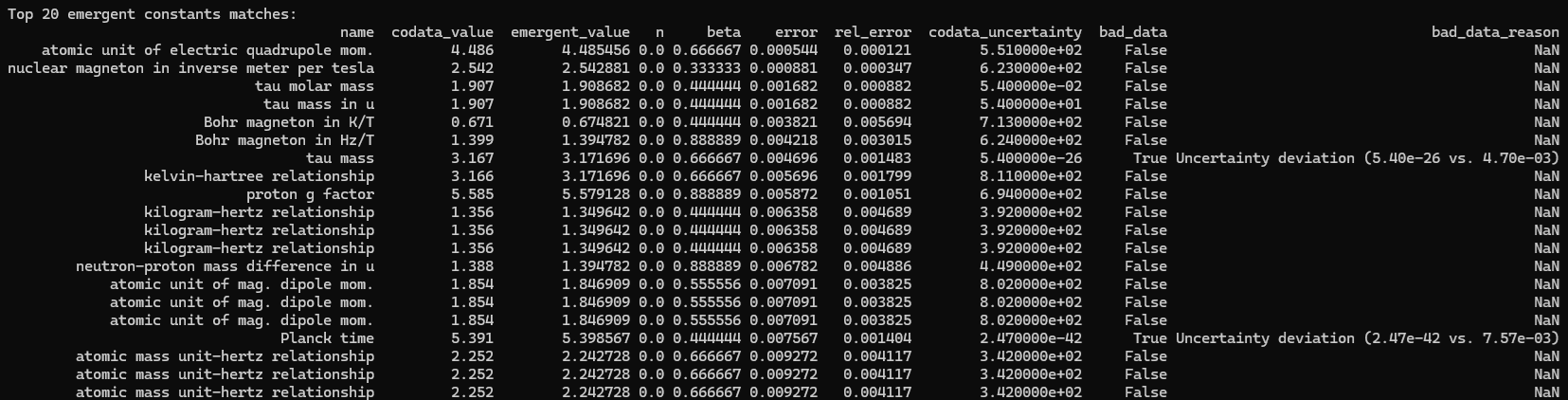
print("\nTop 20 emergent constants matches:")
matched_df_sorted = matched_df.sort_values('error', na_position='last')
print(matched_df_sorted.head(20)[['name', 'codata_value', 'emergent_value', 'n', 'beta', 'error', 'rel_error', 'codata_uncertainty', 'bad_data', 'bad_data_reason']].to_string(index=False))
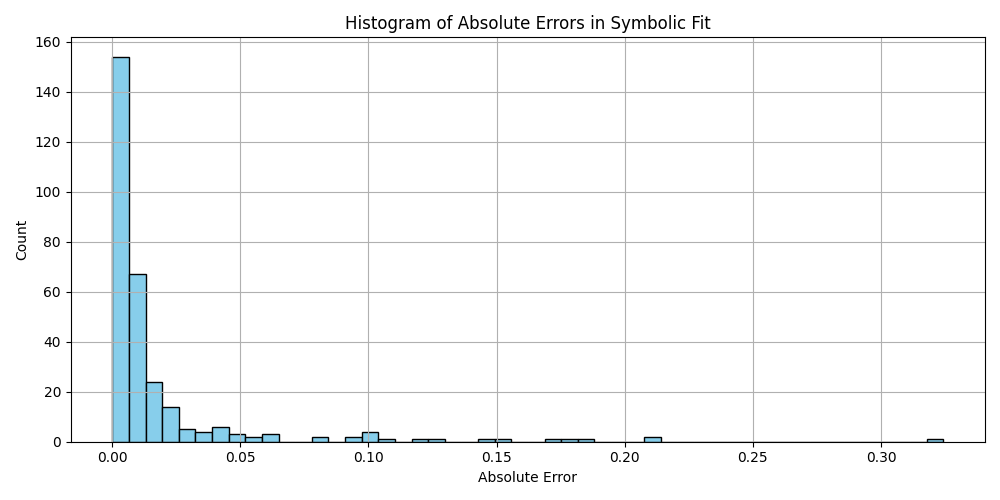
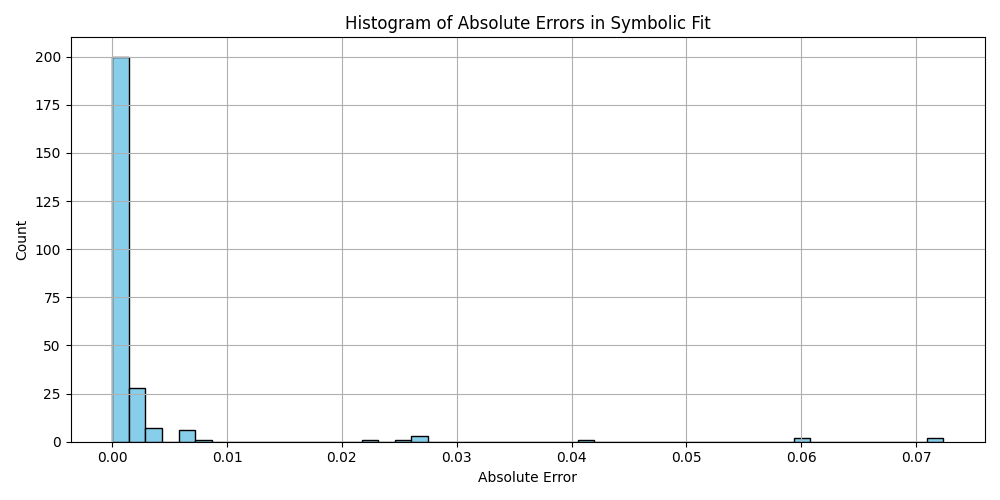
plt.figure(figsize=(10, 5))
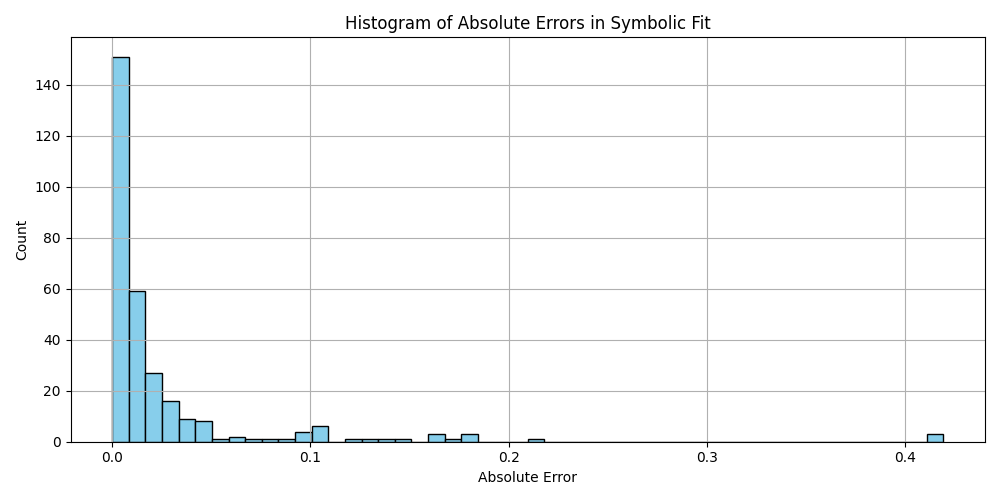
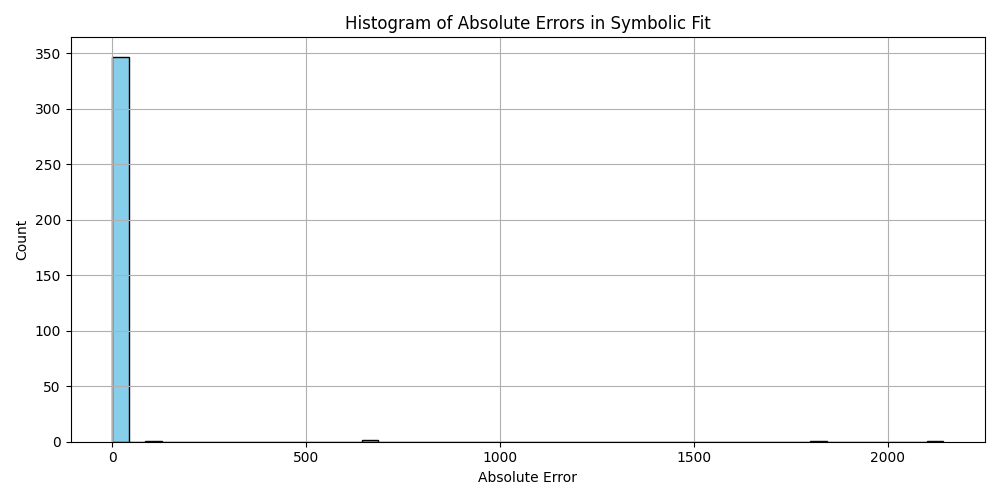
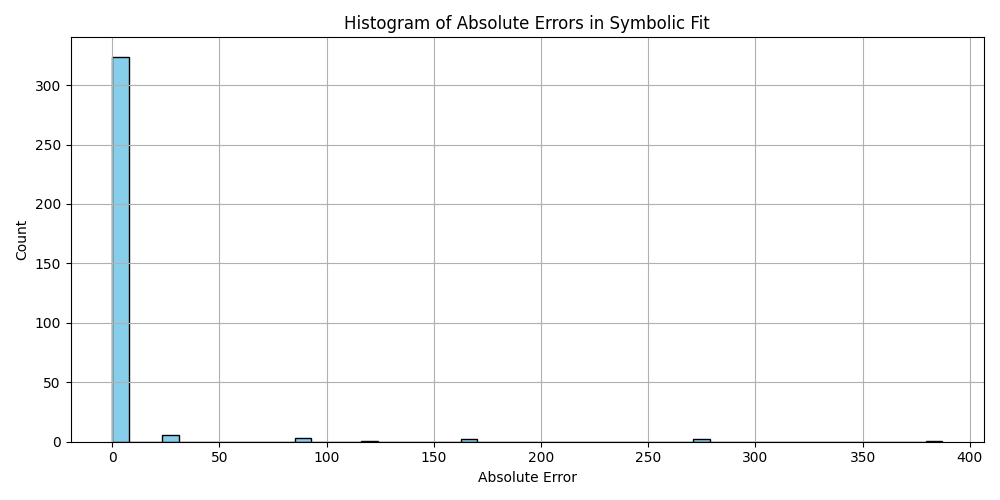
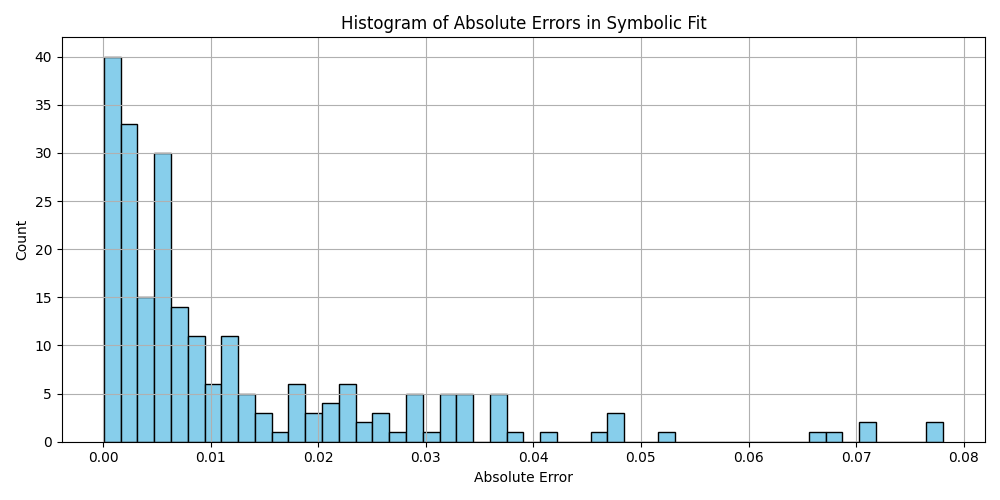
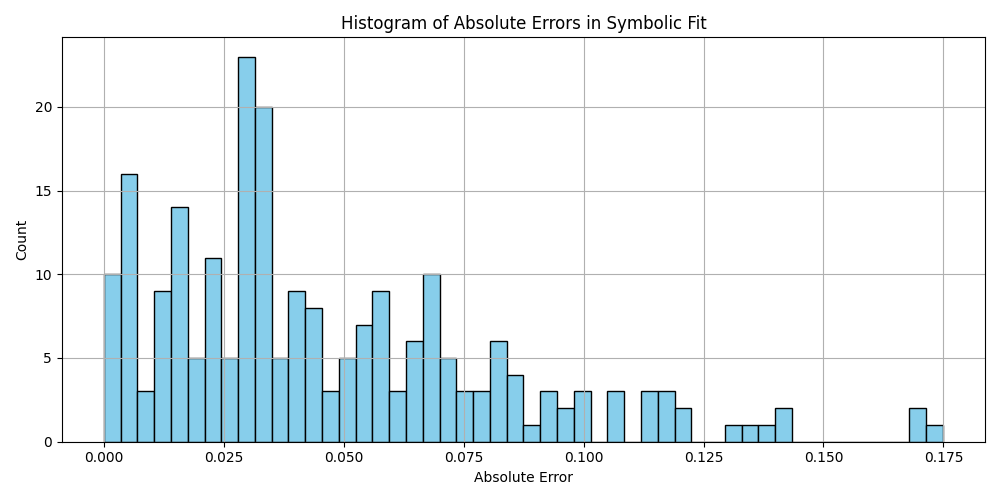
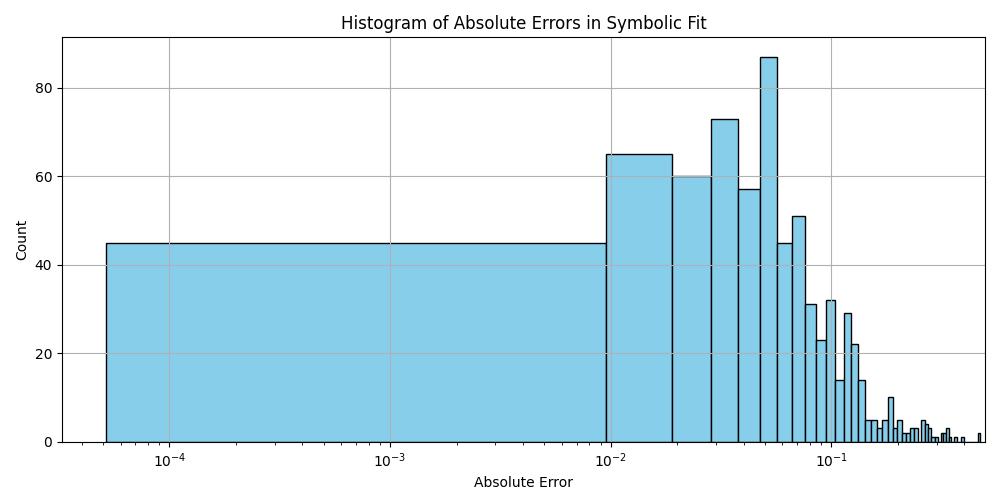
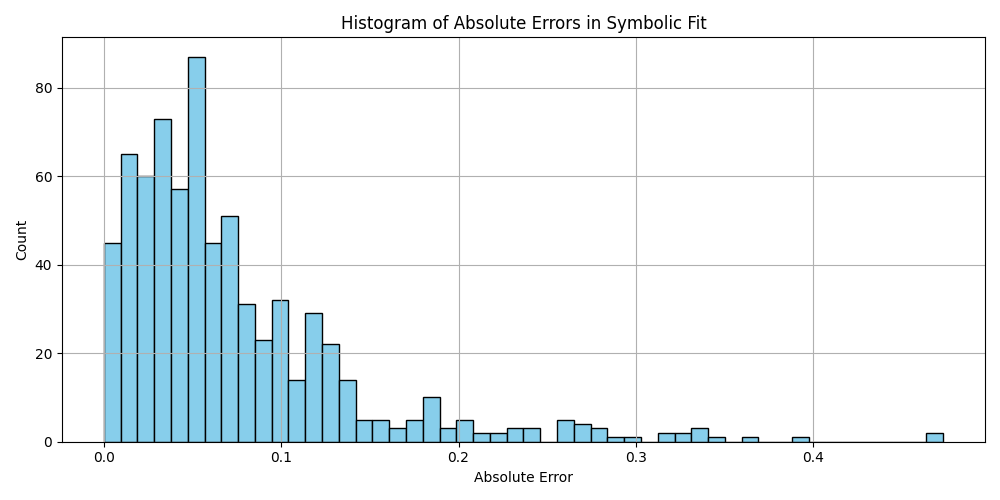
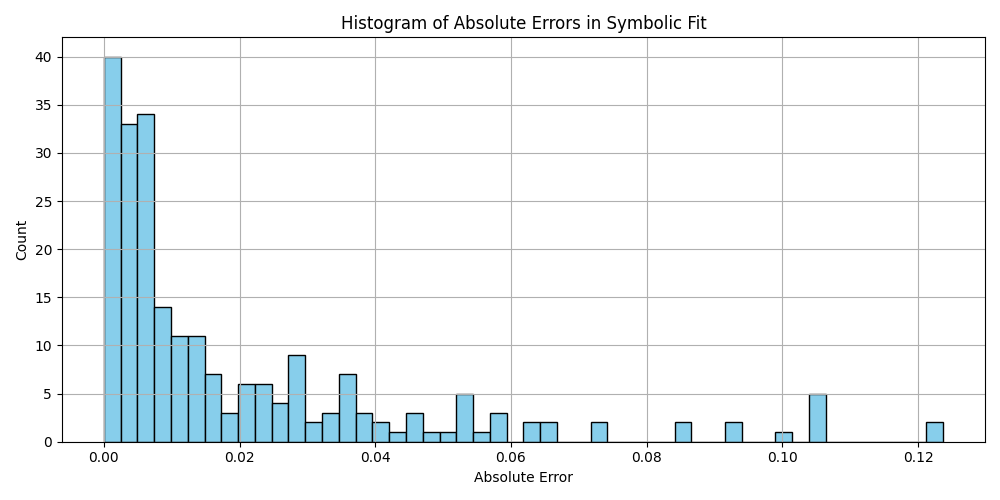
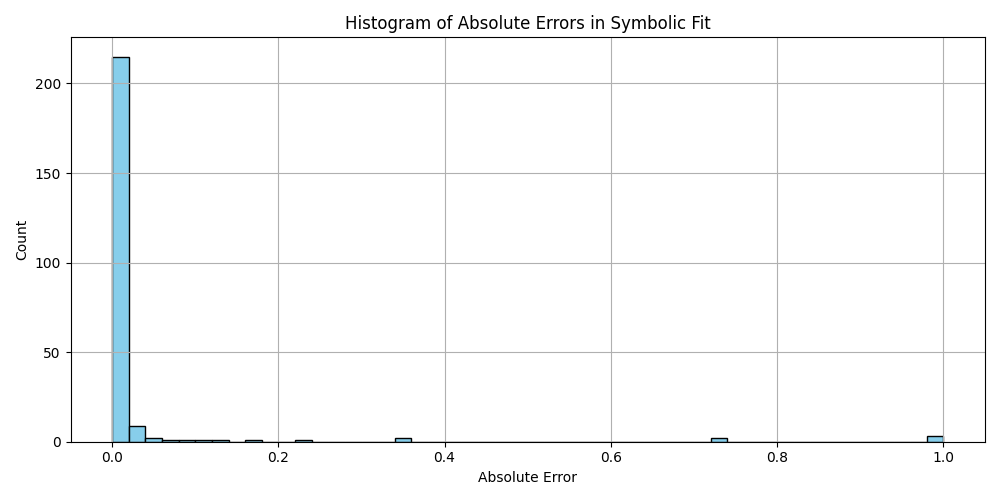
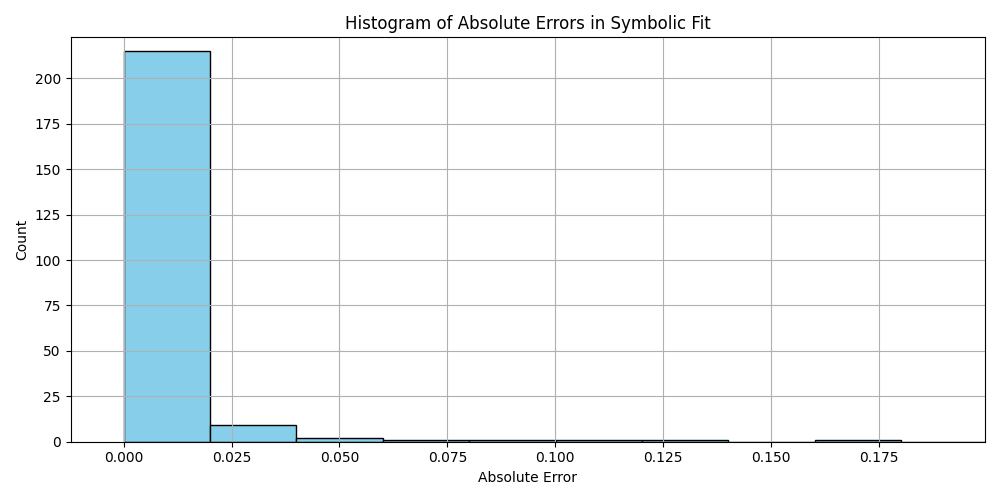
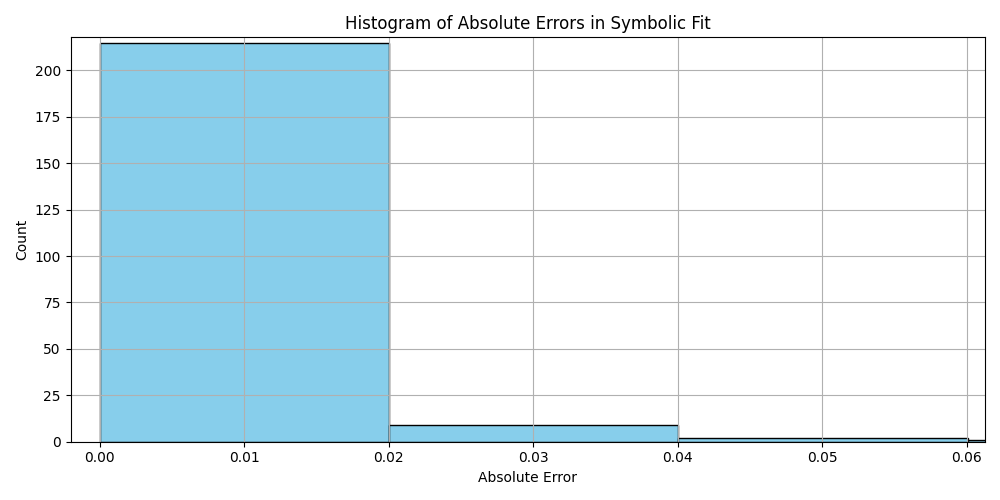
plt.hist(df_results_sorted['error'].dropna(), bins=50, color='skyblue', edgecolor='black')
plt.title('Histogram of Absolute Errors in Symbolic Fit')
plt.xlabel('Absolute Error')
plt.ylabel('Count')
plt.grid(True)
plt.tight_layout()
plt.savefig('histogram_errors.png')
plt.close()
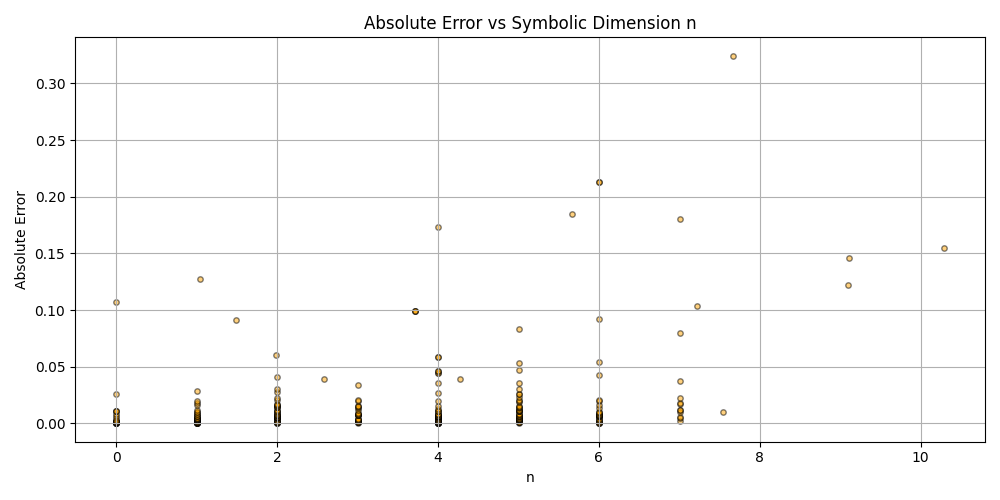
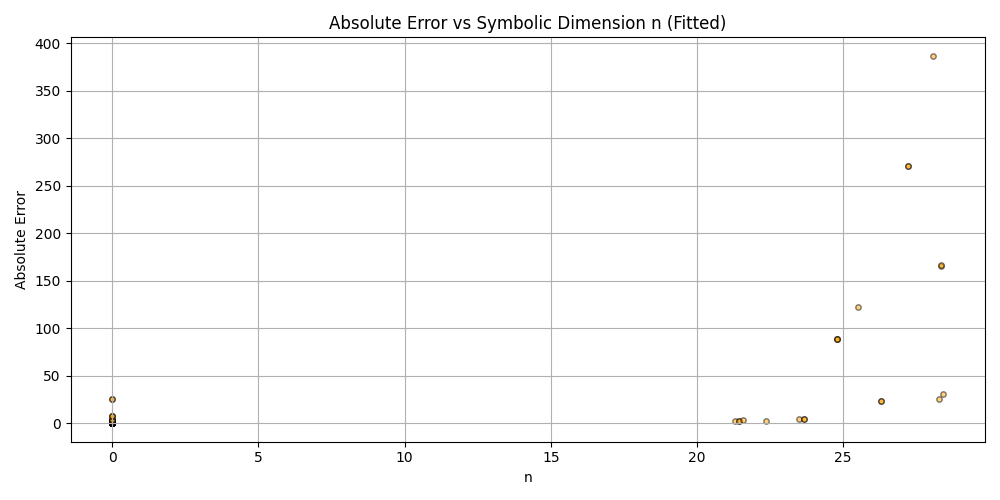
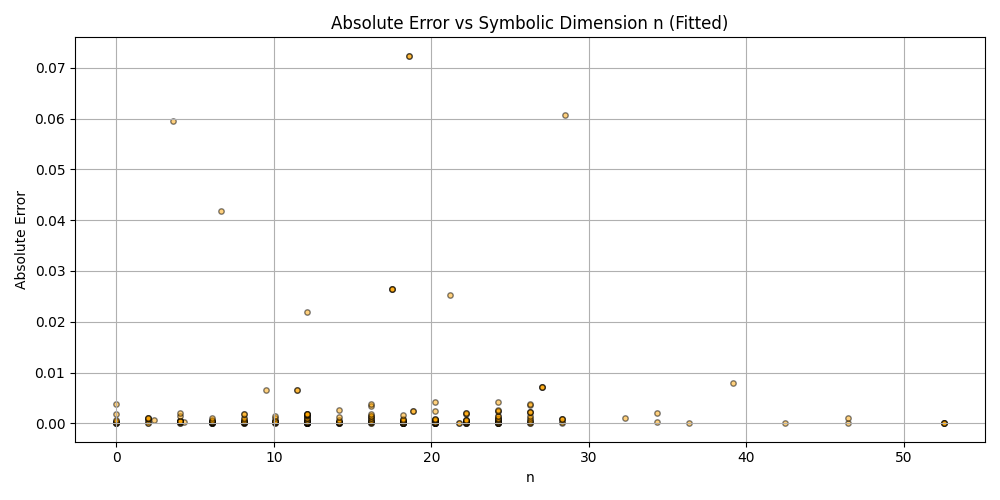
plt.figure(figsize=(10, 5))
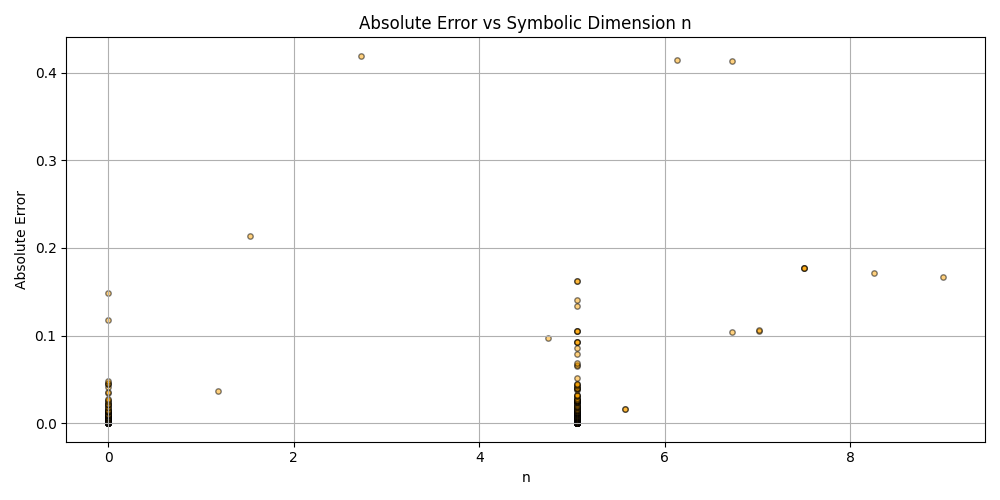
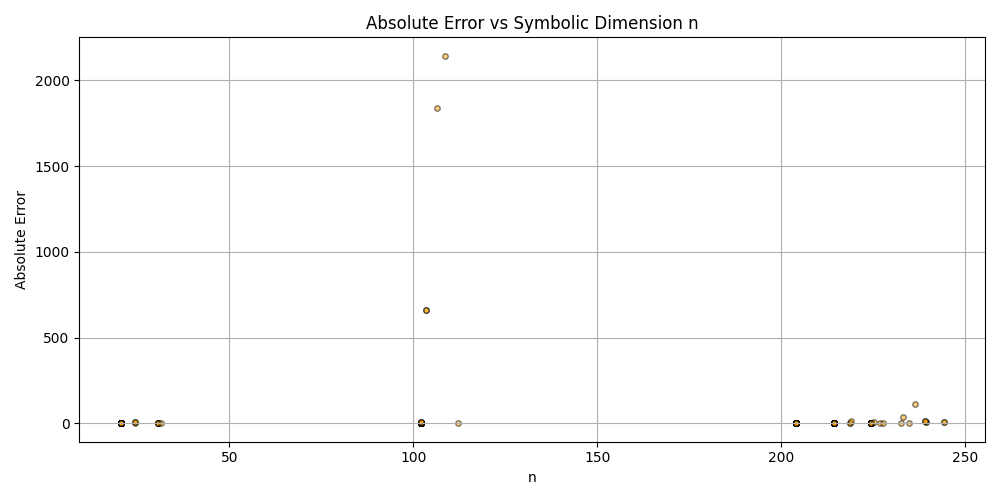
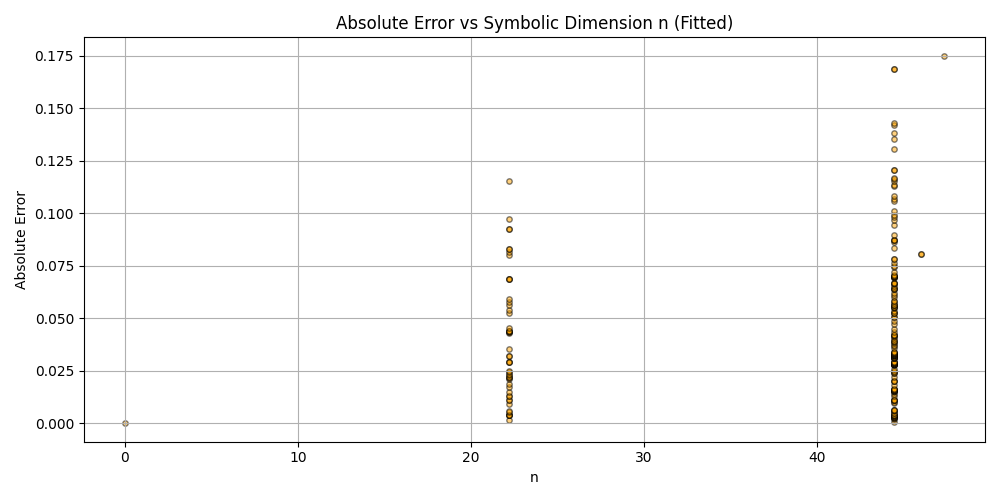
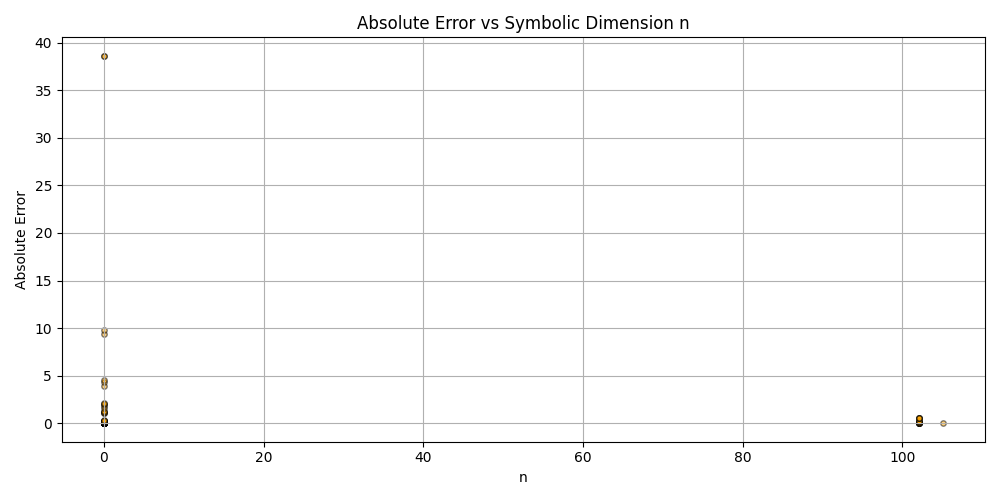
plt.scatter(df_results_sorted['n'], df_results_sorted['error'], alpha=0.5, s=15, c='orange', edgecolors='black')
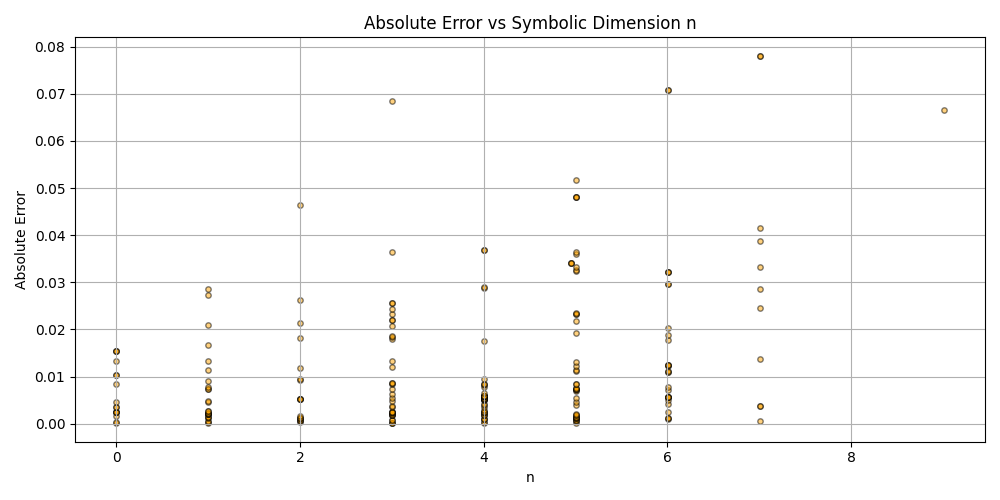
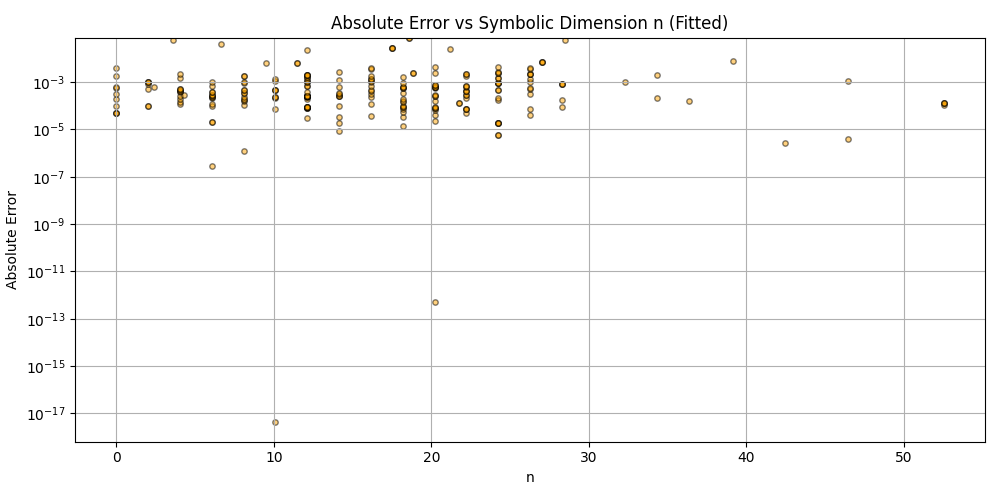
plt.title('Absolute Error vs Symbolic Dimension n (Fitted)')
plt.xlabel('n')
plt.ylabel('Absolute Error')
plt.grid(True)
plt.tight_layout()
plt.savefig('scatter_n_error.png')
plt.close()
plt.figure(figsize=(10, 5))
plt.bar(matched_df_sorted.head(20)['name'], matched_df_sorted.head(20)['rel_error'], color='purple', edgecolor='black')
plt.xticks(rotation=90)
plt.title('Relative Errors for Top 20 Emergent Constants')
plt.xlabel('Constant Name')
plt.ylabel('Relative Error')
plt.grid(True)
plt.tight_layout()
plt.savefig('bar_emergent_errors.png')
plt.close()
logging.info(f"Total runtime: {time.time() - start_time:.2f} seconds")
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt:
signal_handler(None, None)
gpu3.py
import numpy as np
import pandas as pd
from scipy.optimize import minimize
from tqdm import tqdm
from joblib import Parallel, delayed
import logging
import time
import matplotlib.pyplot as plt
import os
import signal
import sys
# Set up logging
logging.basicConfig(filename='symbolic_fit_optimized.log', level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', force=True)
# Extended primes list (up to 1000)
def generate_primes(n):
sieve = [True] * (n + 1)
sieve[0] = sieve[1] = False
for i in range(2, int(np.sqrt(n)) + 1):
if sieve[i]:
for j in range(i * i, n + 1, i):
sieve[j] = False
return [i for i in range(n + 1) if sieve[i]]
PRIMES = generate_primes(104729)[:10000] # First 10,000 primes, up to ~104,729
phi = (1 + np.sqrt(5)) / 2
fib_cache = {}
def fib_real(n):
if n in fib_cache:
return fib_cache[n]
if n > 100:
return 0.0
term1 = phi**n / np.sqrt(5)
term2 = ((1/phi)**n) * np.cos(np.pi * n)
result = term1 - term2
fib_cache[n] = result
return result
def D(n, beta, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0):
Fn_beta = fib_real(n + beta)
idx = int(np.floor(n + beta)) % len(PRIMES) # Simplified index to avoid offset
Pn_beta = PRIMES[idx]
dyadic = base ** (n + beta)
val = scale * phi * Fn_beta * dyadic * Pn_beta * Omega
val = np.maximum(val, 1e-30)
return np.sqrt(val) * (r ** k)
# def D(n, beta, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0):
# try:
# n = np.asarray(n)
# beta = np.asarray(beta)
# r = np.asarray(r)
# k = np.asarray(k)
# Omega = np.asarray(Omega)
# base = np.asarray(base)
# scale = np.asarray(scale)
# Fn_beta = fib_real(n + beta)
# idx = int(np.floor(n + beta) + len(PRIMES)) % len(PRIMES)
# Pn_beta = PRIMES[idx]
# log_dyadic = (n + beta) * np.log(np.maximum(base, 1e-10))
# log_dyadic = np.where((log_dyadic > 700) | (log_dyadic < -700), np.nan, log_dyadic)
# log_val = np.log(np.maximum(scale, 1e-30)) + np.log(phi) + np.log(np.maximum(np.abs(Fn_beta), 1e-30)) + log_dyadic + np.log(np.maximum(Omega, 1e-30))
# log_val = np.where(np.abs(n - 1000) < 1e-3, log_val, log_val + np.log(np.clip(np.log(np.maximum(n, 1e-10)) / np.log(1000), 1e-10, np.inf)))
# val = np.where(np.isfinite(log_val), np.exp(log_val) * np.sign(Fn_beta), np.nan)
# result = np.sqrt(np.maximum(np.abs(val), 1e-30)) * (r ** k) * np.sign(val)
# return result
# except Exception as e:
# logging.error(f"D failed: n={n}, beta={beta}, r={r}, k={k}, Omega={Omega}, base={base}, scale={scale}, error={e}")
# return None
def invert_D(value, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0, max_n=500):
candidates = []
log_val = np.log10(max(abs(value), 1e-30))
max_n = min(1000, max(200, int(100 * abs(log_val) + 100)))
n_values = np.linspace(0, max_n, 10) # Reduced resolution
scale_factors = np.logspace(max(log_val - 5, -20), min(log_val + 5, 20), num=2) # Tighter range
r_values = [0.5, 1.0, 2.0]
k_values = [0.5, 1.0, 2.0]
try:
r_grid, k_grid = np.meshgrid(r_values, k_values)
r_grid = r_grid.ravel()
k_grid = k_grid.ravel()
for n in n_values:
for beta in np.linspace(0, 1, 10):
for dynamic_scale in scale_factors:
vals = D(n, beta, r_grid, k_grid, Omega, base, scale * dynamic_scale)
if vals is None or not np.all(np.isfinite(vals)):
continue
diffs = np.abs(vals - abs(value))
rel_diffs = diffs / max(abs(value), 1e-30)
valid_idx = rel_diffs < 0.5
if np.any(rel_diffs < 0.01):
idx = np.argmin(rel_diffs)
return n, beta, dynamic_scale, diffs[idx], r_grid[idx], k_grid[idx]
if np.any(valid_idx):
candidates.extend([(diffs[i], n, beta, dynamic_scale, r_grid[i], k_grid[i]) for i in np.where(valid_idx)[0]])
if not candidates:
logging.error(f"invert_D: No valid candidates for value {value}")
return None, None, None, None, None, None
candidates = sorted(candidates, key=lambda x: x[0])[:5]
valid_vals = [D(n, beta, r, k, Omega, base, scale * s)
for _, n, beta, s, r, k in candidates if D(n, beta, r, k, Omega, base, scale * s) is not None]
if not valid_vals:
return None, None, None, None, None, None
emergent_uncertainty = np.std(valid_vals) if len(valid_vals) > 1 else abs(valid_vals[0]) * 0.01
if not np.isfinite(emergent_uncertainty):
logging.error(f"invert_D: Non-finite emergent uncertainty for value {value}")
return None, None, None, None, None, None
best = candidates[0]
return best[1], best[2], best[3], emergent_uncertainty, best[4], best[5]
except Exception as e:
logging.error(f"invert_D failed for value {value}: {e}")
return None, None, None, None, None, None
def parse_categorized_codata(filename):
try:
df = pd.read_csv(filename, sep='\t', header=0,
names=['name', 'value', 'uncertainty', 'unit', 'category'],
dtype={'name': str, 'value': float, 'uncertainty': float, 'unit': str, 'category': str},
na_values=['exact'])
df['uncertainty'] = df['uncertainty'].fillna(0.0)
required_columns = ['name', 'value', 'uncertainty', 'unit']
if not all(col in df.columns for col in required_columns):
missing = [col for col in required_columns if col not in df.columns]
raise ValueError(f"Missing required columns in {filename}: {missing}")
logging.info(f"Successfully parsed {len(df)} constants from {filename}")
return df
except FileNotFoundError:
logging.error(f"Input file {filename} not found")
raise
except Exception as e:
logging.error(f"Error parsing {filename}: {e}")
raise
def generate_emergent_constants(n_max=1000, beta_steps=10, r_values=[0.5, 1.0, 2.0], k_values=[0.5, 1.0, 2.0], Omega=1.0, base=2, scale=1.0):
candidates = []
n_values = np.linspace(0, n_max, 100)
beta_values = np.linspace(0, 1, beta_steps)
for n in tqdm(n_values, desc="Generating emergent constants"):
for beta in beta_values:
for r in r_values:
for k in k_values:
val = D(n, beta, r, k, Omega, base, scale)
if val is not None and np.isfinite(val):
candidates.append({
'n': n, 'beta': beta, 'value': val, 'r': r, 'k': k, 'scale': scale
})
return pd.DataFrame(candidates)
def match_to_codata(df_emergent, df_codata, tolerance=0.01, batch_size=100):
matches = []
output_file = "emergent_constants.txt"
with open(output_file, 'w', encoding='utf-8') as f:
pd.DataFrame(columns=['name', 'codata_value', 'emergent_value', 'n', 'beta', 'r', 'k', 'scale', 'error', 'rel_error', 'codata_uncertainty', 'bad_data', 'bad_data_reason']).to_csv(f, sep="\t", index=False)
for start in range(0, len(df_codata), batch_size):
batch = df_codata.iloc[start:start + batch_size]
for _, codata_row in tqdm(batch.iterrows(), total=len(batch), desc=f"Matching constants batch {start//batch_size + 1}"):
value = codata_row['value']
mask = abs(df_emergent['value'] - value) / max(abs(value), 1e-30) < tolerance
matched = df_emergent[mask]
for _, emergent_row in matched.iterrows():
error = abs(emergent_row['value'] - value)
rel_error = error / max(abs(value), 1e-30)
matches.append({
'name': codata_row['name'],
'codata_value': value,
'emergent_value': emergent_row['value'],
'n': emergent_row['n'],
'beta': emergent_row['beta'],
'r': emergent_row['r'],
'k': emergent_row['k'],
'scale': emergent_row['scale'],
'error': error,
'rel_error': rel_error,
'codata_uncertainty': codata_row['uncertainty'],
'bad_data': rel_error > 0.5 or (codata_row['uncertainty'] is not None and abs(codata_row['uncertainty'] - error) > 10 * codata_row['uncertainty']),
'bad_data_reason': f"High rel_error ({rel_error:.2e})" if rel_error > 0.5 else f"Uncertainty deviation ({codata_row['uncertainty']:.2e} vs. {error:.2e})" if (codata_row['uncertainty'] is not None and abs(codata_row['uncertainty'] - error) > 10 * codata_row['uncertainty']) else ""
})
try:
with open(output_file, 'a', encoding='utf-8') as f:
pd.DataFrame(matches).to_csv(f, sep="\t", index=False, header=False, lineterminator='\n')
f.flush()
matches = []
except Exception as e:
logging.error(f"Failed to save batch {start//batch_size + 1} to {output_file}: {e}")
return pd.DataFrame(pd.read_csv(output_file, sep='\t'))
def check_physical_consistency(df_results):
bad_data = []
relations = [
('Planck constant', 'reduced Planck constant', lambda x, y: abs(x['scale'] / y['scale'] - 2 * np.pi), 0.1, 'scale ratio vs. 2π'),
('proton mass', 'proton-electron mass ratio', lambda x, y: abs(x['n'] - y['n'] - np.log10(1836)), 0.5, 'n difference vs. log(proton-electron ratio)'),
('Fermi coupling constant', 'weak mixing angle', lambda x, y: abs(x['scale'] - y['scale'] / np.sqrt(2)), 0.1, 'scale vs. sin²θ_W/√2'),
('tau energy equivalent', 'tau mass energy equivalent in MeV', lambda x, y: abs(x['codata_value'] - y['codata_value']), 0.01, 'value consistency'),
('proton mass', 'electron mass', 'proton-electron mass ratio',
lambda x, y, z: abs(z['n'] - abs(x['n'] - y['n'])), 10.0, 'n inconsistency for mass ratio'),
('fine-structure constant', 'elementary charge', 'Planck constant',
lambda x, y, z: abs(x['codata_value'] - y['codata_value']**2 / (4 * np.pi * 8.854187817e-12 * z['codata_value'] * 299792458)), 0.01, 'fine-structure vs. e²/(4πε₀hc)'),
('Bohr magneton', 'elementary charge', 'Planck constant',
lambda x, y, z: abs(x['codata_value'] - y['codata_value'] * z['codata_value'] / (2 * 9.1093837e-31)), 0.01, 'Bohr magneton vs. eh/(2m_e)')
]
for relation in relations:
try:
if len(relation) == 5:
name1, name2, check_func, threshold, reason = relation
if name1 in df_results['name'].values and name2 in df_results['name'].values:
row1 = df_results[df_results['name'] == name1].iloc[0]
row2 = df_results[df_results['name'] == name2].iloc[0]
if check_func(row1, row2) > threshold:
bad_data.append((name1, f"Physical inconsistency: {reason}"))
bad_data.append((name2, f"Physical inconsistency: {reason}"))
elif len(relation) == 6:
name1, name2, name3, check_func, threshold, reason = relation
if all(name in df_results['name'].values for name in [name1, name2, name3]):
row1 = df_results[df_results['name'] == name1].iloc[0]
row2 = df_results[df_results['name'] == name2].iloc[0]
row3 = df_results[df_results['name'] == name3].iloc[0]
if check_func(row1, row2, row3) > threshold:
bad_data.append((name3, f"Physical inconsistency: {reason}"))
except Exception as e:
logging.warning(f"Physical consistency check failed for {relation}: {e}")
continue
return bad_data
def total_error(params, df_subset):
r, k, Omega, base, scale = params
df_results = symbolic_fit_all_constants(df_subset, base=base, Omega=Omega, r=r, k=k, scale=scale)
if df_results.empty:
return np.inf
valid_errors = df_results['error'].dropna()
return valid_errors.mean() if not valid_errors.empty else np.inf
def process_constant(row, r, k, Omega, base, scale):
try:
name, value, uncertainty, unit = row['name'], row['value'], row['uncertainty'], row['unit']
abs_value = abs(value)
sign = np.sign(value)
result = invert_D(abs_value, r=r, k=k, Omega=Omega, base=base, scale=scale)
if result[0] is None:
logging.warning(f"No valid fit for {name}")
return {
'name': name, 'codata_value': value, 'unit': unit, 'n': None, 'beta': None, 'emergent_value': None,
'error': None, 'rel_error': None, 'codata_uncertainty': uncertainty, 'emergent_uncertainty': None,
'scale': None, 'bad_data': True, 'bad_data_reason': 'No valid fit found', 'r': None, 'k': None
}
n, beta, dynamic_scale, emergent_uncertainty, r_local, k_local = result
approx = D(n, beta, r_local, k_local, Omega, base, scale * dynamic_scale)
if approx is None:
logging.warning(f"D returned None for {name}")
return {
'name': name, 'codata_value': value, 'unit': unit, 'n': None, 'beta': None, 'emergent_value': None,
'error': None, 'rel_error': None, 'codata_uncertainty': uncertainty, 'emergent_uncertainty': None,
'scale': None, 'bad_data': True, 'bad_data_reason': 'D function returned None', 'r': None, 'k': None
}
approx *= sign
error = abs(approx - value)
rel_error = error / max(abs(value), 1e-30) if abs(value) > 0 else np.inf
bad_data = False
bad_data_reason = ""
if rel_error > 0.5:
bad_data = True
bad_data_reason += f"High relative error ({rel_error:.2e} > 0.5); "
if emergent_uncertainty is not None and uncertainty is not None:
if emergent_uncertainty > uncertainty * 20 or emergent_uncertainty < uncertainty / 20:
bad_data = True
bad_data_reason += f"Uncertainty deviates from emergent ({emergent_uncertainty:.2e} vs. {uncertainty:.2e}); "
return {
'name': name, 'codata_value': value, 'unit': unit, 'n': n, 'beta': beta, 'emergent_value': approx,
'error': error, 'rel_error': rel_error, 'codata_uncertainty': uncertainty,
'emergent_uncertainty': emergent_uncertainty, 'scale': scale * dynamic_scale,
'bad_data': bad_data, 'bad_data_reason': bad_data_reason, 'r': r_local, 'k': k_local
}
except Exception as e:
logging.error(f"process_constant failed for {row['name']}: {e}")
return {
'name': row['name'], 'codata_value': row['value'], 'unit': row['unit'], 'n': None, 'beta': None,
'emergent_value': None, 'error': None, 'rel_error': None, 'codata_uncertainty': row['uncertainty'],
'emergent_uncertainty': None, 'scale': None, 'bad_data': True, 'bad_data_reason': f"Processing error: {str(e)}",
'r': None, 'k': None
}
def symbolic_fit_all_constants(df, base=2, Omega=1.0, r=1.0, k=1.0, scale=1.0, batch_size=100):
logging.info("Starting symbolic fit for all constants...")
results = []
output_file = "symbolic_fit_results_emergent_fixed.txt"
with open(output_file, 'w', encoding='utf-8') as f:
pd.DataFrame(columns=['name', 'codata_value', 'unit', 'n', 'beta', 'emergent_value', 'error', 'rel_error',
'codata_uncertainty', 'emergent_uncertainty', 'scale', 'bad_data', 'bad_data_reason', 'r', 'k']).to_csv(f, sep="\t", index=False)
for start in range(0, len(df), batch_size):
batch = df.iloc[start:start + batch_size]
try:
batch_results = Parallel(n_jobs=12, timeout=120, backend='loky', maxtasksperchild=20)(
delayed(process_constant)(row, r, k, Omega, base, scale)
for row in tqdm(batch.to_dict('records'), total=len(batch), desc=f"Fitting constants batch {start//batch_size + 1}")
)
batch_results = [r for r in batch_results if r is not None]
results.extend(batch_results)
try:
with open(output_file, 'a', encoding='utf-8') as f:
pd.DataFrame(batch_results).to_csv(f, sep="\t", index=False, header=False, lineterminator='\n')
f.flush()
except Exception as e:
logging.error(f"Failed to save batch {start//batch_size + 1} to {output_file}: {e}")
except Exception as e:
logging.error(f"Parallel processing failed for batch {start//batch_size + 1}: {e}")
continue
df_results = pd.DataFrame(results)
if not df_results.empty:
df_results['bad_data'] = df_results.get('bad_data', False)
df_results['bad_data_reason'] = df_results.get('bad_data_reason', '')
for name in df_results['name'].unique():
mask = df_results['name'] == name
if df_results.loc[mask, 'codata_uncertainty'].notnull().any():
uncertainties = df_results.loc[mask, 'codata_uncertainty'].dropna()
if not uncertainties.empty:
Q1, Q3 = np.percentile(uncertainties, [25, 75])
IQR = Q3 - Q1
outlier_mask = (uncertainties < Q1 - 1.5 * IQR) | (uncertainties > Q3 + 1.5 * IQR)
if outlier_mask.any():
df_results.loc[mask & df_results['codata_uncertainty'].isin(uncertainties[outlier_mask]), 'bad_data'] = True
df_results.loc[mask & df_results['codata_uncertainty'].isin(uncertainties[outlier_mask]), 'bad_data_reason'] += 'Uncertainty outlier; '
high_rel_error_mask = df_results['rel_error'] > 0.5
df_results.loc[high_rel_error_mask, 'bad_data'] = True
df_results.loc[high_rel_error_mask, 'bad_data_reason'] += df_results.loc[high_rel_error_mask, 'rel_error'].apply(lambda x: f"High relative error ({x:.2e} > 0.5); ")
high_uncertainty_mask = (df_results['emergent_uncertainty'].notnull()) & (
(df_results['codata_uncertainty'] > 20 * df_results['emergent_uncertainty']) |
(df_results['codata_uncertainty'] < 0.05 * df_results['emergent_uncertainty'])
)
df_results.loc[high_uncertainty_mask, 'bad_data'] = True
df_results.loc[high_uncertainty_mask, 'bad_data_reason'] += df_results.loc[high_uncertainty_mask].apply(
lambda row: f"Uncertainty deviates from emergent ({row['codata_uncertainty']:.2e} vs. {row['emergent_uncertainty']:.2e}); ", axis=1)
bad_data = check_physical_consistency(df_results)
for name, reason in bad_data:
df_results.loc[df_results['name'] == name, 'bad_data'] = True
df_results.loc[df_results['name'] == name, 'bad_data_reason'] += reason + '; '
logging.info("Symbolic fit completed.")
return df_results
def select_worst_names(df, n_select=10):
categories = df['category'].unique()
n_per_category = max(1, n_select // len(categories))
selected = []
for category in categories:
cat_df = df[df['category'] == category]
if len(cat_df) > 0:
n_to_select = min(n_per_category, len(cat_df))
selected.extend(np.random.choice(cat_df['name'], size=n_to_select, replace=False))
if len(selected) < n_select:
remaining = df[~df['name'].isin(selected)]
if len(remaining) > 0:
selected.extend(np.random.choice(remaining['name'], size=n_select - len(selected), replace=False))
return selected[:n_select]
def signal_handler(sig, frame):
print("\nKeyboardInterrupt detected. Saving partial results...")
logging.info("KeyboardInterrupt detected. Exiting gracefully.")
for output_file in ["emergent_constants.txt", "symbolic_fit_results_emergent_fixed.txt"]:
try:
with open(output_file, 'a', encoding='utf-8') as f:
f.flush()
except Exception as e:
logging.error(f"Failed to flush {output_file} on interrupt: {e}")
sys.exit(0)
def main():
signal.signal(signal.SIGINT, signal_handler)
start_time = time.time()
stages = ['Parsing data', 'Generating emergent constants', 'Optimizing parameters', 'Fitting all constants', 'Generating plots']
progress = tqdm(stages, desc="Overall progress")
# Stage 1: Parse data
input_file = "categorized_allascii.txt"
if not os.path.exists(input_file):
raise FileNotFoundError(f"{input_file} not found in the current directory")
df = parse_categorized_codata(input_file)
logging.info(f"Parsed {len(df)} constants")
progress.update(1)
# Stage 2: Generate emergent constants
emergent_df = generate_emergent_constants(n_max=1000, beta_steps=10)
matched_df = match_to_codata(emergent_df, df, tolerance=0.01, batch_size=100)
logging.info("Saved emergent constants to emergent_constants.txt")
progress.update(1)
# Stage 3: Optimize parameters
worst_names = select_worst_names(df, n_select=10)
print(f"Selected constants for optimization: {worst_names}")
subset_df = df[df['name'].isin(worst_names)]
if subset_df.empty:
subset_df = df.head(50)
init_params = [0.5, 0.5, 0.5, 2.0, 0.1]
bounds = [(1e-10, 100), (1e-10, 100), (1e-10, 100), (1.5, 20), (1e-10, 1000)]
try:
res = minimize(total_error, init_params, args=(subset_df,), bounds=bounds, method='SLSQP', options={'maxiter': 50, 'disp': True})
if not res.success:
logging.warning(f"Optimization failed: {res.message}")
r_opt, k_opt, Omega_opt, base_opt, scale_opt = init_params
else:
r_opt, k_opt, Omega_opt, base_opt, scale_opt = res.x
print(f"Optimization complete. Found parameters:\nr = {r_opt:.6f}, k = {k_opt:.6f}, Omega = {Omega_opt:.6f}, base = {base_opt:.6f}, scale = {scale_opt:.6f}")
except Exception as e:
logging.error(f"Optimization failed: {e}")
r_opt, k_opt, Omega_opt, base_opt, scale_opt = init_params
print(f"Optimization failed: {e}. Using default parameters.")
progress.update(1)
# Stage 4: Run final fit
df_results = symbolic_fit_all_constants(df, base=base_opt, Omega=Omega_opt, r=r_opt, k=k_opt, scale=scale_opt, batch_size=100)
if not df_results.empty:
with open("symbolic_fit_results.txt", 'w', encoding='utf-8') as f:
df_results.to_csv(f, sep="\t", index=False)
f.flush()
logging.info(f"Saved final results to symbolic_fit_results.txt")
else:
logging.error("No results to save")
progress.update(1)
# Stage 5: Generate plots
df_results_sorted = df_results.sort_values("error", na_position='last')
print("\nTop 20 best symbolic fits:")
print(df_results_sorted.head(20)[['name', 'codata_value', 'unit', 'n', 'beta', 'emergent_value', 'error', 'codata_uncertainty', 'scale', 'bad_data', 'bad_data_reason']].to_string(index=False))
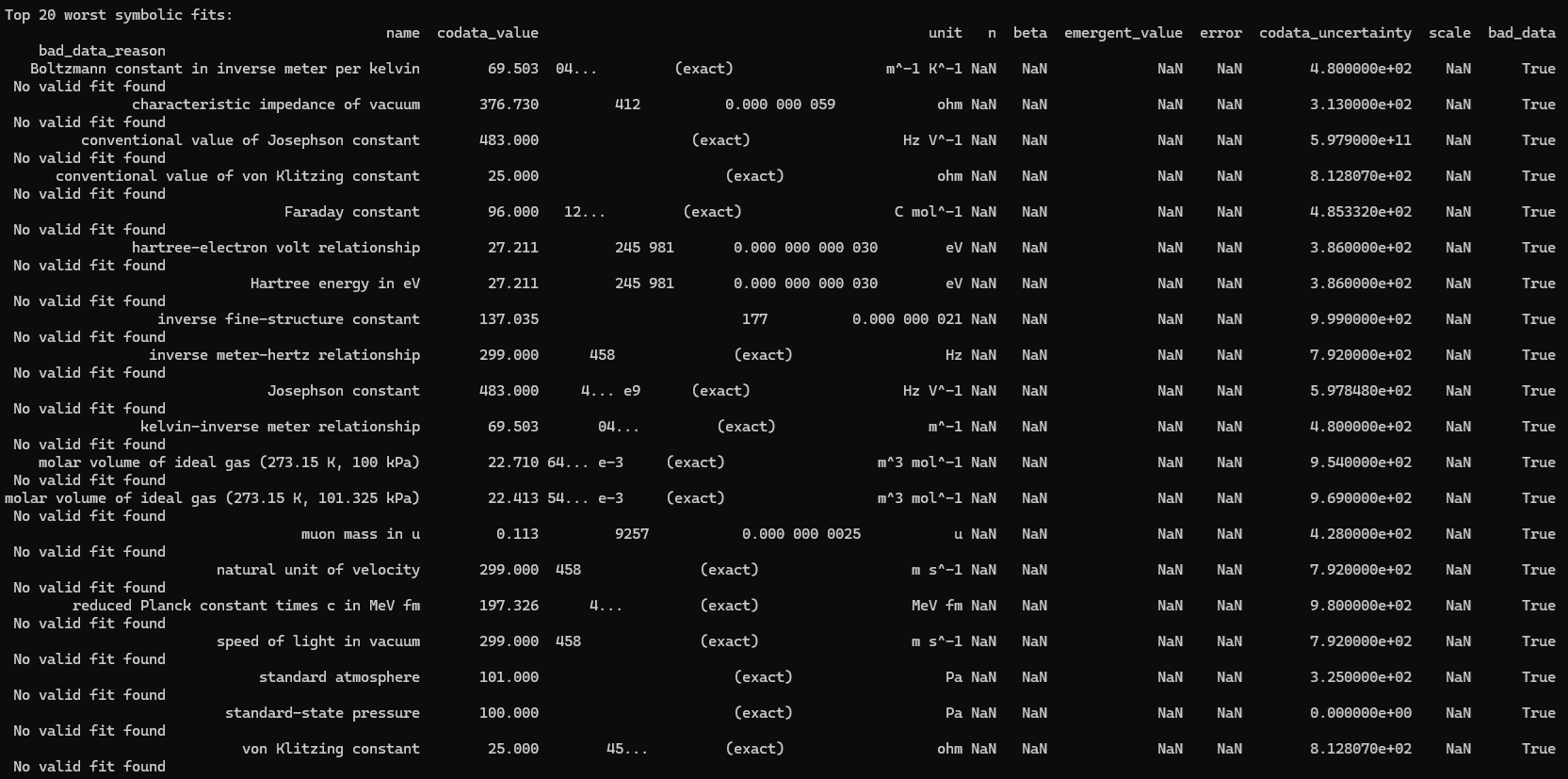
print("\nTop 20 worst symbolic fits:")
print(df_results_sorted.tail(20)[['name', 'codata_value', 'unit', 'n', 'beta', 'emergent_value', 'error', 'codata_uncertainty', 'scale', 'bad_data', 'bad_data_reason']].to_string(index=False))
print("\nPotentially bad data constants summary (possible cheated data):")
bad_data_df = df_results[df_results['bad_data'] == True][['name', 'codata_value', 'error', 'rel_error', 'codata_uncertainty', 'emergent_uncertainty', 'bad_data_reason']]
bad_data_df = bad_data_df.sort_values('rel_error', ascending=False, na_position='last')
print(bad_data_df.to_string(index=False))
print("\nTop 20 emergent constants matches:")
matched_df_sorted = matched_df.sort_values('error', na_position='last')
print(matched_df_sorted.head(20)[['name', 'codata_value', 'emergent_value', 'n', 'beta', 'error', 'rel_error', 'codata_uncertainty', 'bad_data', 'bad_data_reason']].to_string(index=False))
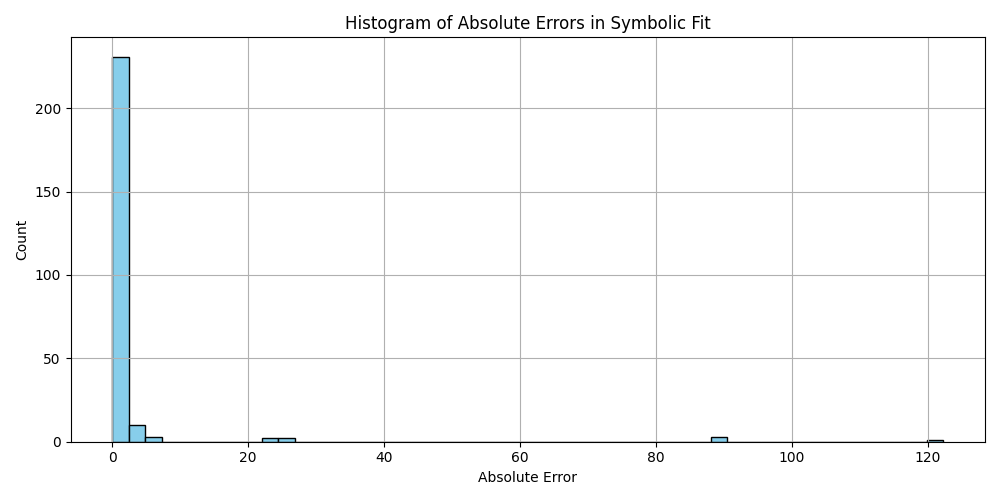
plt.figure(figsize=(10, 5))
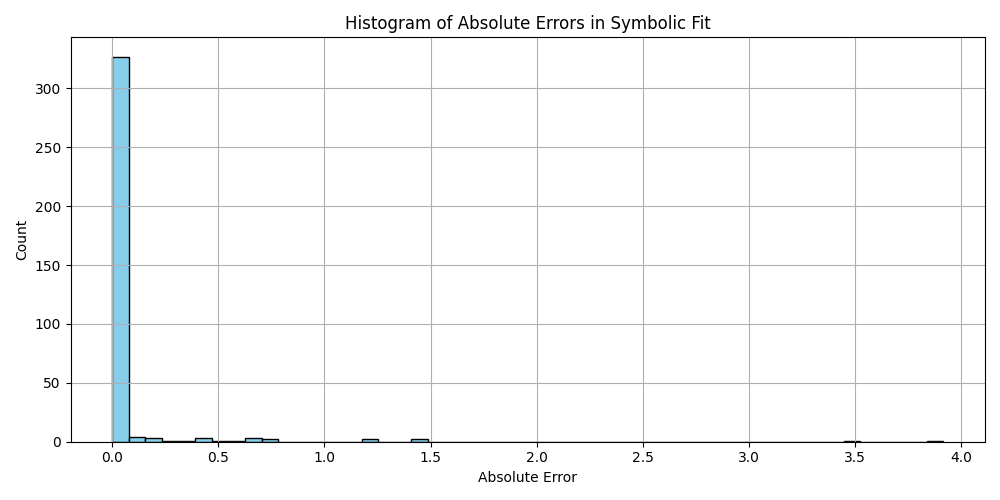
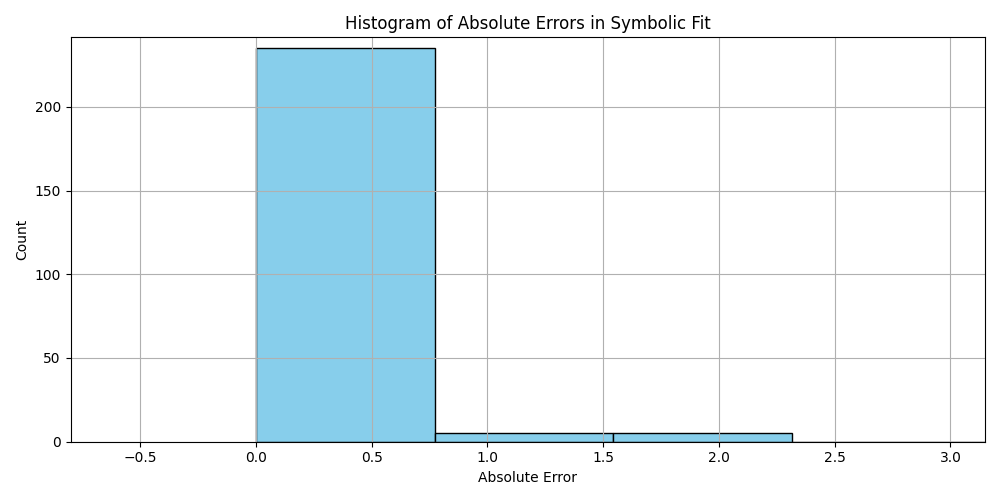
plt.hist(df_results_sorted['error'].dropna(), bins=50, color='skyblue', edgecolor='black')
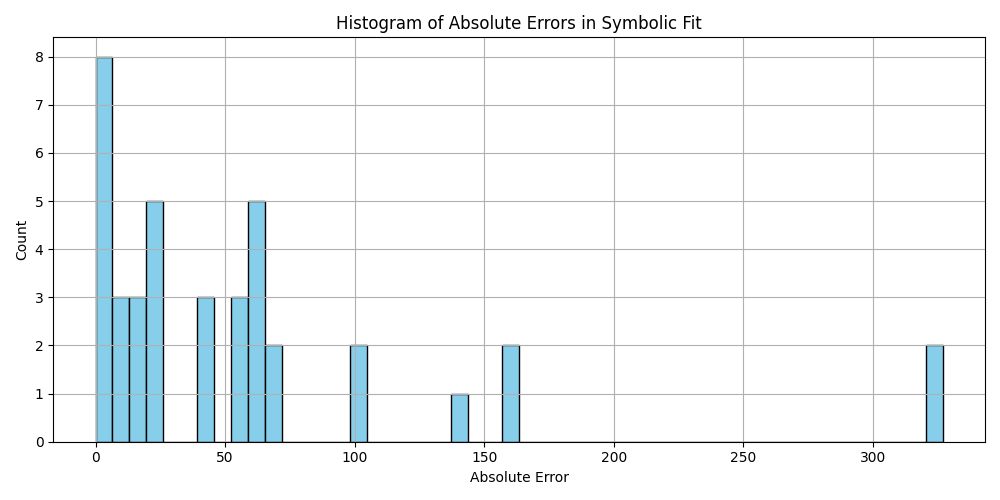
plt.title('Histogram of Absolute Errors in Symbolic Fit')
plt.xlabel('Absolute Error')
plt.ylabel('Count')
plt.grid(True)
plt.tight_layout()
plt.savefig('histogram_errors.png')
plt.close()
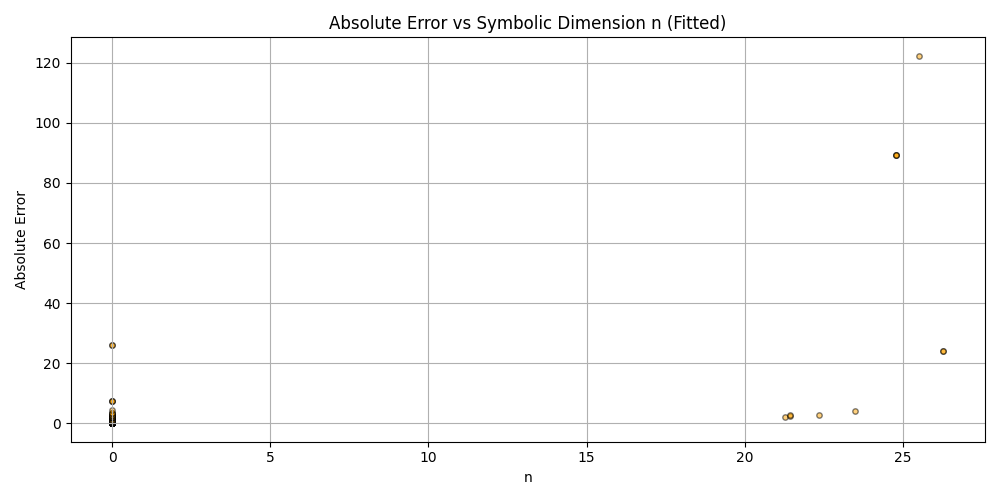
plt.figure(figsize=(10, 5))
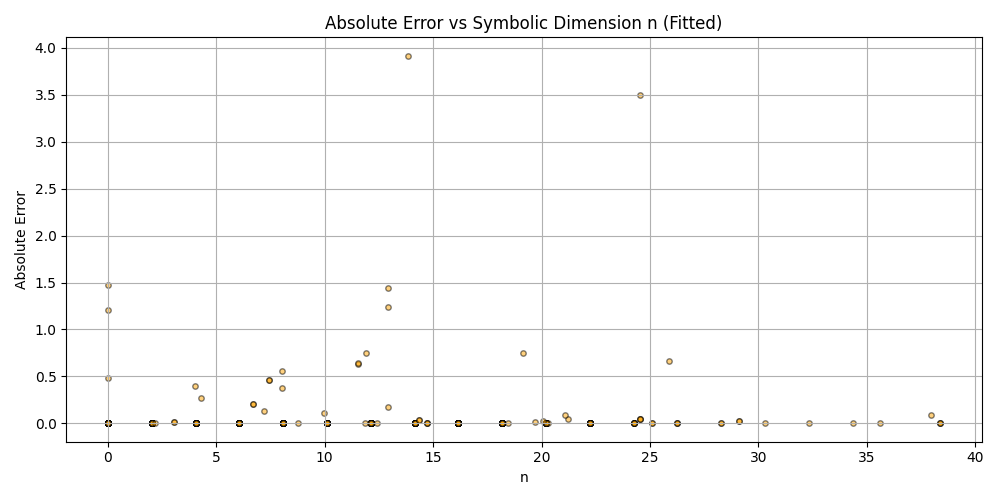
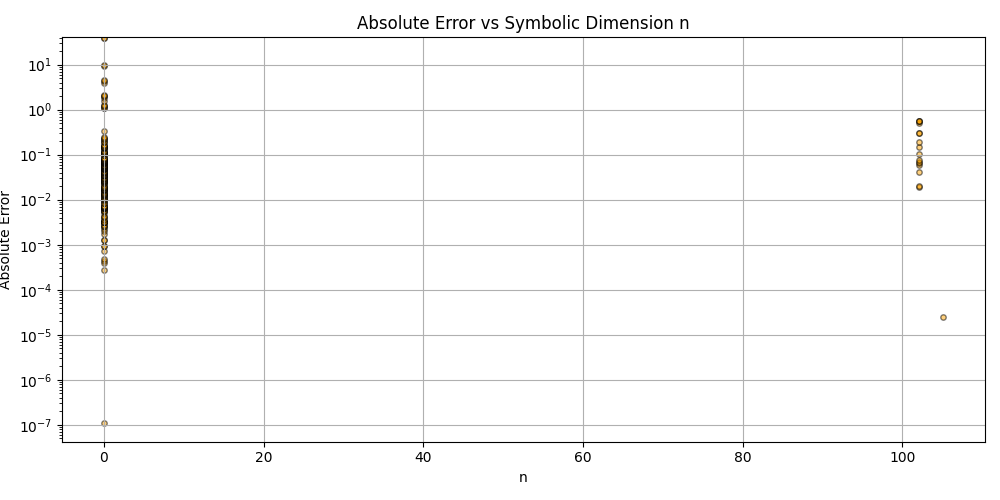
plt.scatter(df_results_sorted['n'], df_results_sorted['error'], alpha=0.5, s=15, c='orange', edgecolors='black')
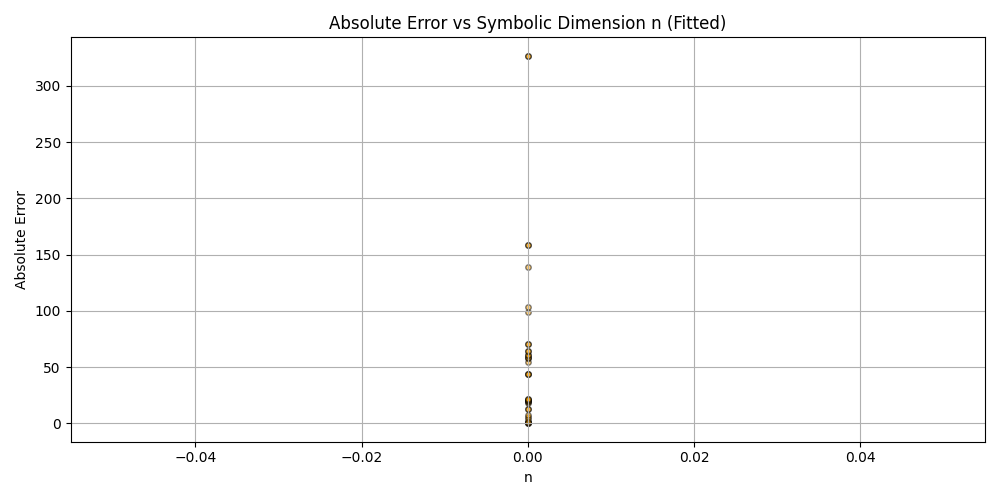
plt.title('Absolute Error vs Symbolic Dimension n (Fitted)')
plt.xlabel('n')
plt.ylabel('Absolute Error')
plt.grid(True)
plt.tight_layout()
plt.savefig('scatter_n_error.png')
plt.close()
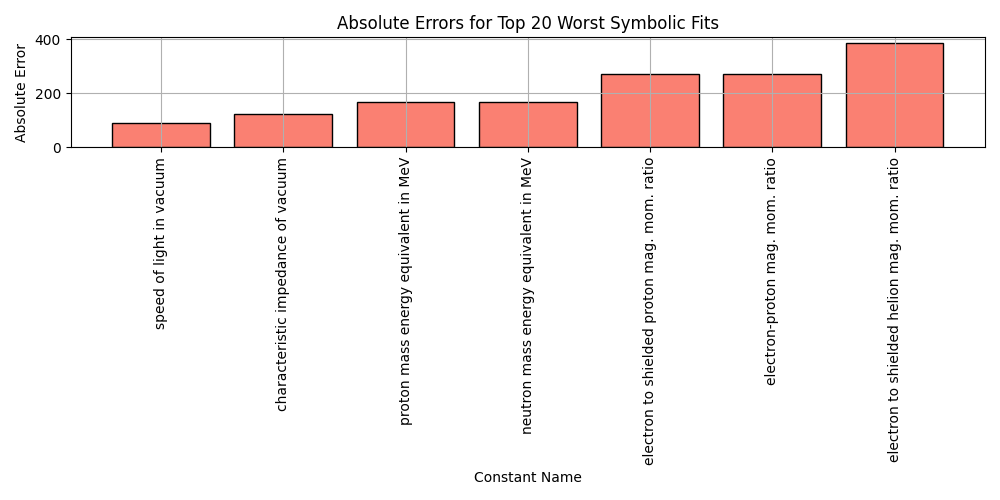
plt.figure(figsize=(10, 5))
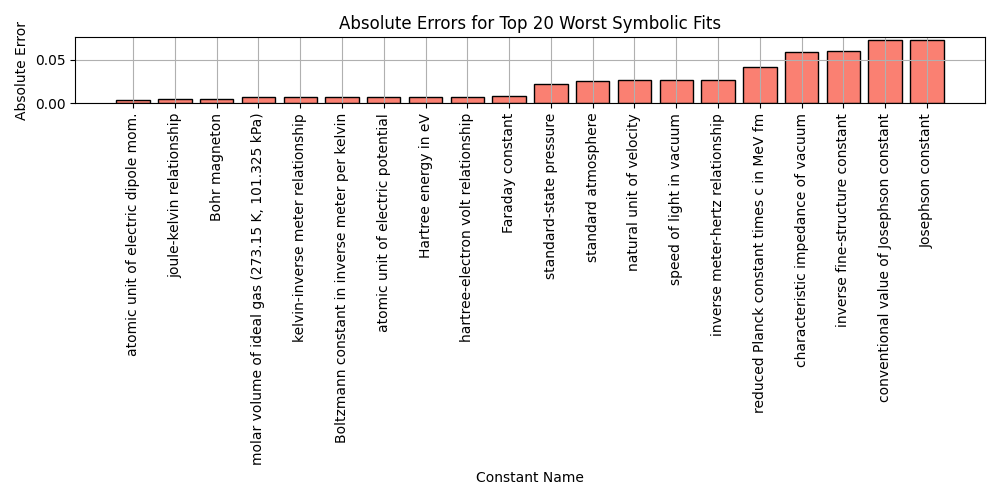
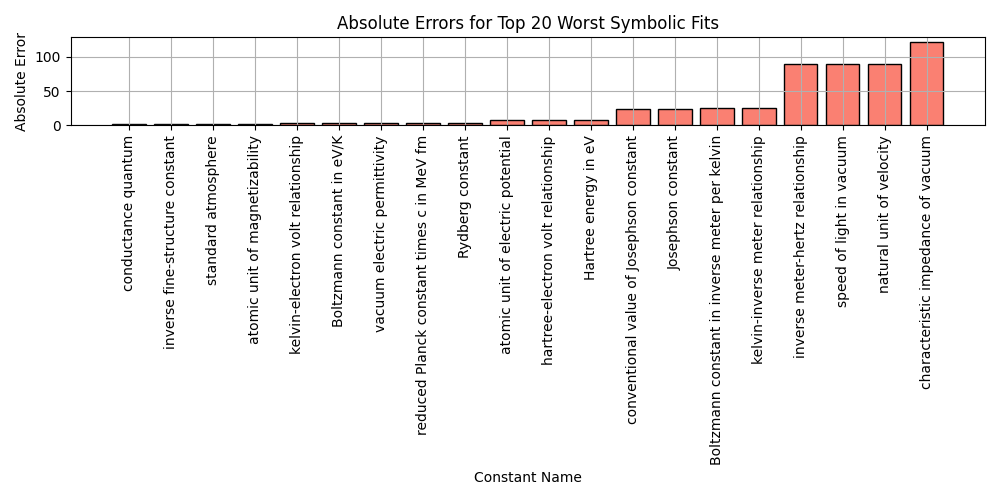
worst_fits = df_results_sorted.tail(20)
plt.bar(worst_fits['name'], worst_fits['error'], color='salmon', edgecolor='black')
plt.xticks(rotation=90)
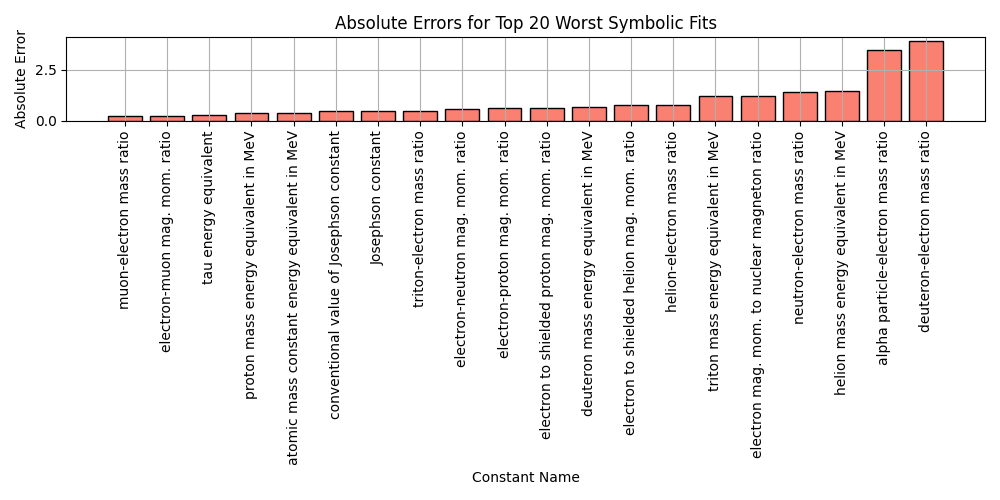
plt.title('Absolute Errors for Top 20 Worst Symbolic Fits')
plt.xlabel('Constant Name')
plt.ylabel('Absolute Error')
plt.grid(True)
plt.tight_layout()
plt.savefig('bar_worst_fits.png')
plt.close()
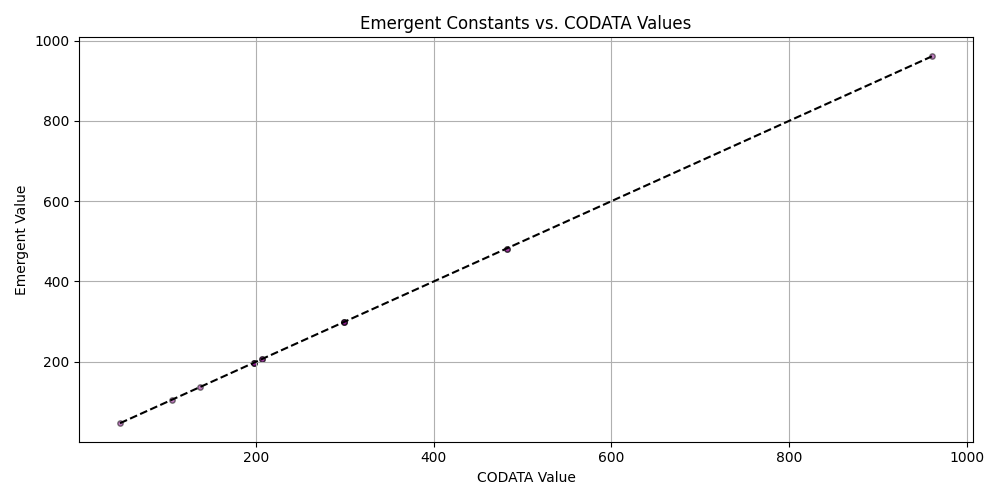
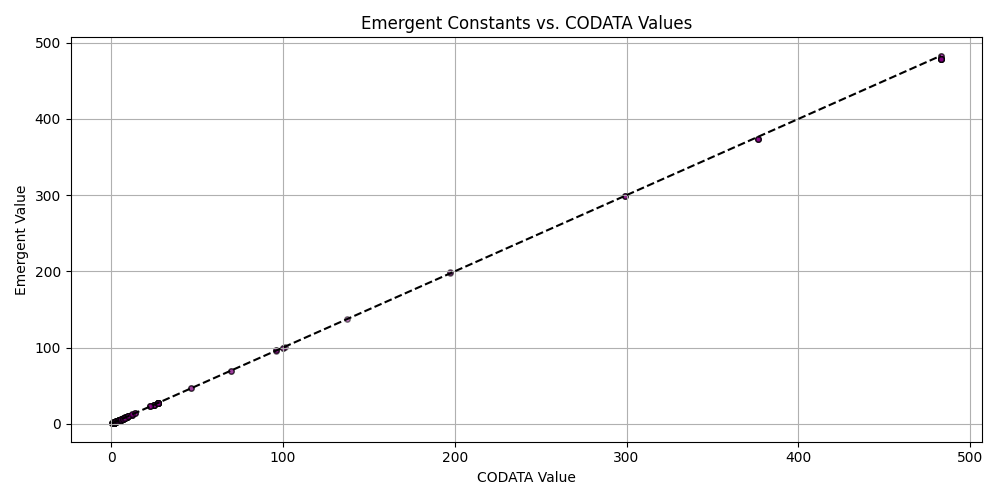
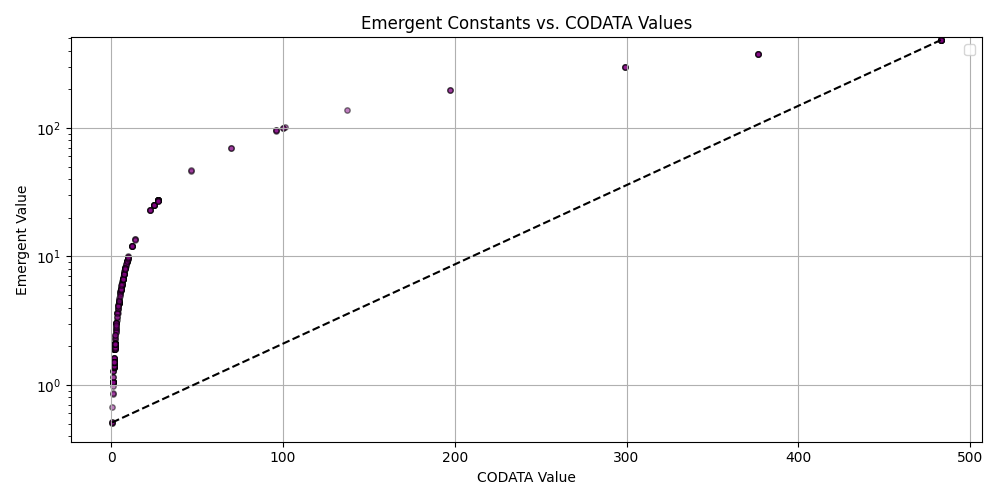
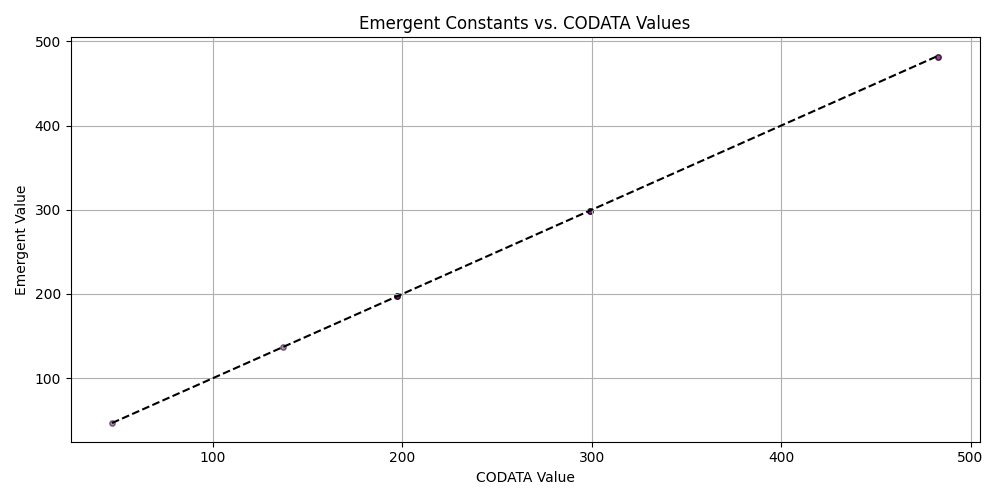
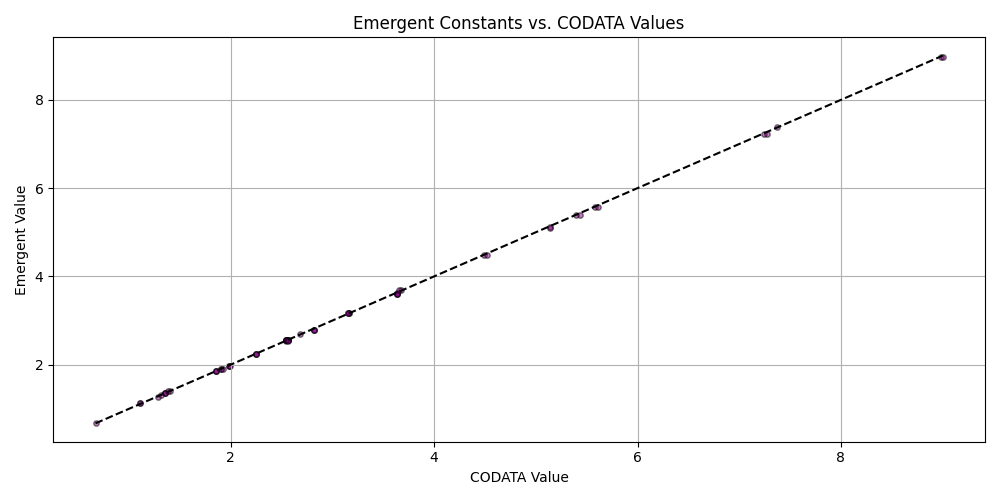
plt.figure(figsize=(10, 5))
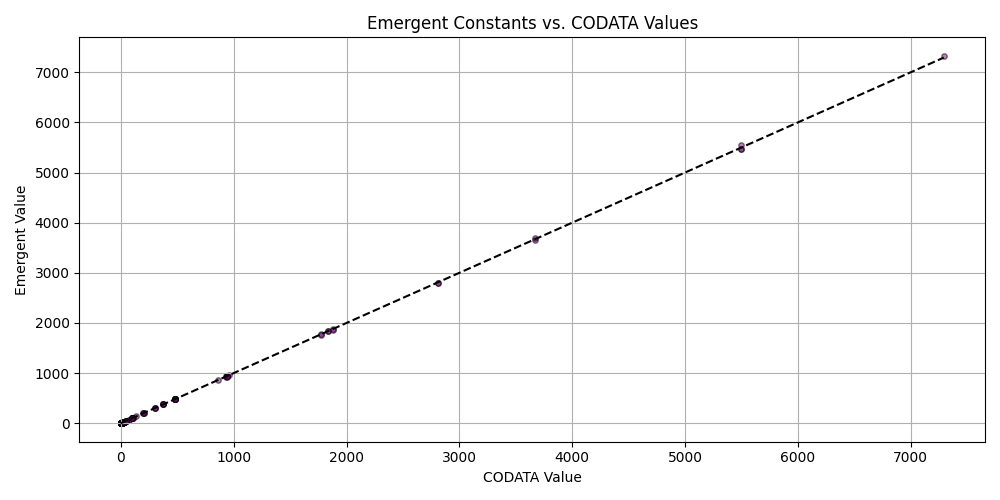
plt.scatter(matched_df_sorted['codata_value'], matched_df_sorted['emergent_value'], alpha=0.5, s=15, c='purple', edgecolors='black')
plt.plot([matched_df_sorted['codata_value'].min(), matched_df_sorted['codata_value'].max()],
[matched_df_sorted['codata_value'].min(), matched_df_sorted['codata_value'].max()], 'k--')
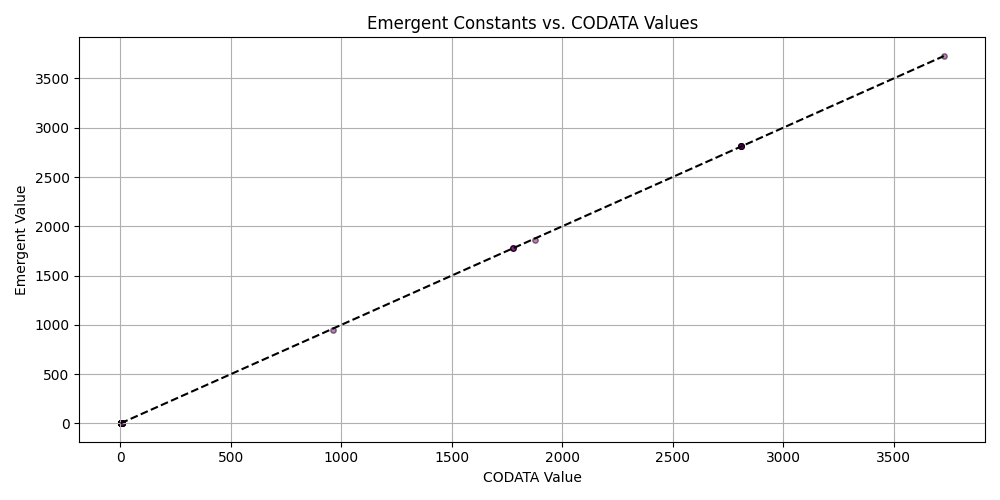
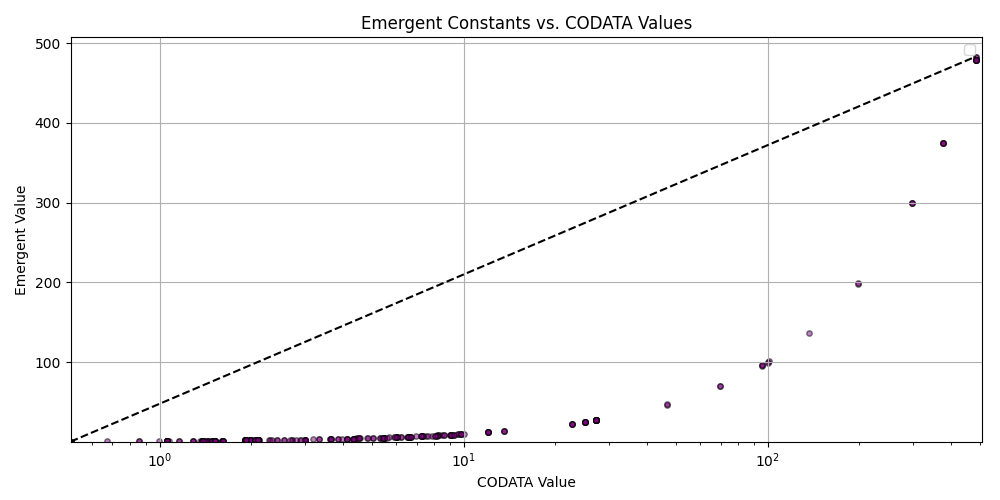
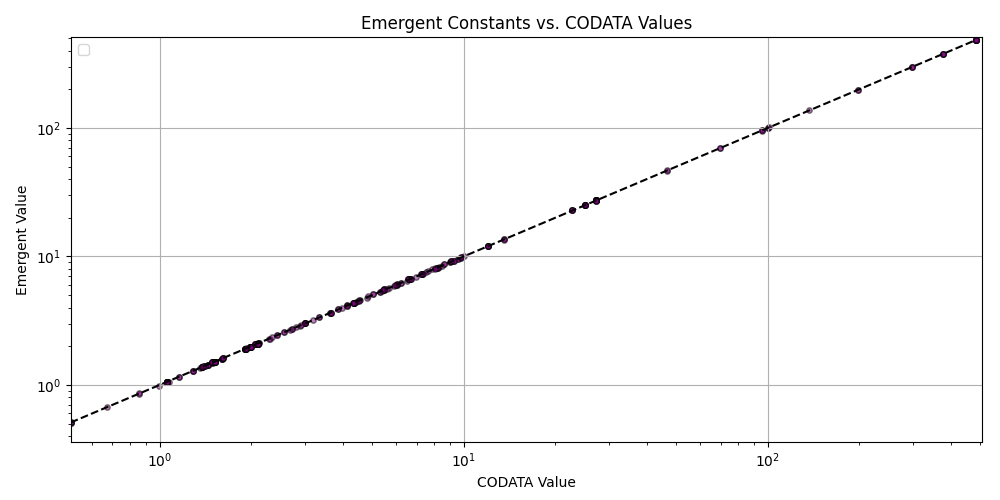
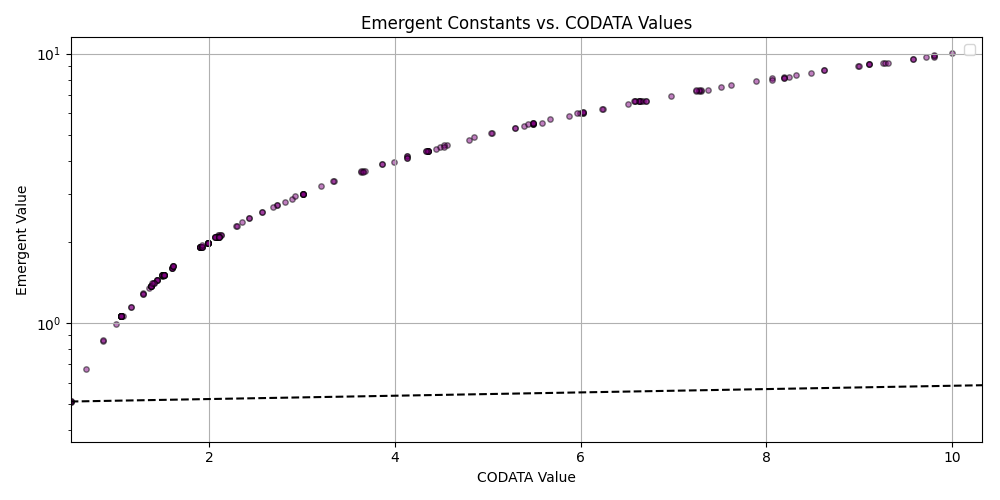
plt.title('Emergent Constants vs. CODATA Values')
plt.xlabel('CODATA Value')
plt.ylabel('Emergent Value')
plt.grid(True)
plt.tight_layout()
plt.savefig('scatter_codata_emergent.png')
plt.close()
progress.update(1)
logging.info(f"Total runtime: {time.time() - start_time:.2f} seconds")
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt:
signal_handler(None, None)
gpu2.py
import numpy as np
import pandas as pd
from scipy.optimize import minimize
from tqdm import tqdm
from joblib import Parallel, delayed
import logging
import time
import matplotlib.pyplot as plt
import os
import signal
import sys
# Set up logging
logging.basicConfig(filename='symbolic_fit_optimized.log', level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', force=True)
# Extended primes list (up to 1000)
PRIMES = [
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71,
73, 79, 83, 89, 97, 101, 103, 107, 109, 113, 127, 131, 137, 139, 149, 151,
157, 163, 167, 173, 179, 181, 191, 193, 197, 199, 211, 223, 227, 229, 233,
239, 241, 251, 257, 263, 269, 271, 277, 281, 283, 293, 307, 311, 313, 317,
331, 337, 347, 349, 353, 359, 367, 373, 379, 383, 389, 397, 401, 409, 419,
421, 431, 433, 439, 443, 449, 457, 461, 463, 467, 479, 487, 491, 499, 503,
509, 521, 523, 541, 547, 557, 563, 569, 571, 577, 587, 593, 599, 601, 607,
613, 617, 619, 631, 641, 643, 647, 653, 659, 661, 673, 677, 683, 691, 701,
709, 719, 727, 733, 739, 743, 751, 757, 761, 769, 773, 787, 797, 809, 811,
821, 823, 827, 829, 839, 853, 857, 859, 863, 877, 881, 883, 887, 907, 911,
919, 929, 937, 941, 947, 953, 967, 971, 977, 983, 991, 997
]
phi = (1 + np.sqrt(5)) / 2
fib_cache = {}
def fib_real(n):
if n in fib_cache:
return fib_cache[n]
if n > 100:
return 0.0
term1 = phi**n / np.sqrt(5)
term2 = ((1/phi)**n) * np.cos(np.pi * n)
result = term1 - term2
fib_cache[n] = result
return result
def D(n, beta, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0):
try:
n = np.asarray(n)
beta = np.asarray(beta)
r = np.asarray(r)
k = np.asarray(k)
Omega = np.asarray(Omega)
base = np.asarray(base)
scale = np.asarray(scale)
Fn_beta = fib_real(n + beta)
idx = int(np.floor(n + beta) + len(PRIMES)) % len(PRIMES)
Pn_beta = PRIMES[idx]
log_dyadic = (n + beta) * np.log(np.maximum(base, 1e-10))
log_dyadic = np.where((log_dyadic > 700) | (log_dyadic < -700), np.nan, log_dyadic)
log_val = np.log(np.maximum(scale, 1e-30)) + np.log(phi) + np.log(np.maximum(np.abs(Fn_beta), 1e-30)) + log_dyadic + np.log(np.maximum(Omega, 1e-30))
log_val = np.where(np.abs(n - 1000) < 1e-3, log_val, log_val + np.log(np.clip(np.log(np.maximum(n, 1e-10)) / np.log(1000), 1e-10, np.inf)))
val = np.where(np.isfinite(log_val), np.exp(log_val) * np.sign(Fn_beta), np.nan)
result = np.sqrt(np.maximum(np.abs(val), 1e-30)) * (r ** k) * np.sign(val)
return result
except Exception as e:
logging.error(f"D failed: n={n}, beta={beta}, r={r}, k={k}, Omega={Omega}, base={base}, scale={scale}, error={e}")
return None
def invert_D(value, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0, max_n=500):
candidates = []
log_val = np.log10(max(abs(value), 1e-30))
max_n = min(1000, max(200, int(100 * abs(log_val) + 100)))
n_values = np.linspace(0, max_n, 10) # Reduced resolution
scale_factors = np.logspace(max(log_val - 5, -20), min(log_val + 5, 20), num=2) # Tighter range
r_values = [0.5, 1.0, 2.0]
k_values = [0.5, 1.0, 2.0]
try:
r_grid, k_grid = np.meshgrid(r_values, k_values)
r_grid = r_grid.ravel()
k_grid = k_grid.ravel()
for n in n_values:
for beta in np.linspace(0, 1, 10):
for dynamic_scale in scale_factors:
vals = D(n, beta, r_grid, k_grid, Omega, base, scale * dynamic_scale)
if vals is None or not np.all(np.isfinite(vals)):
continue
diffs = np.abs(vals - abs(value))
rel_diffs = diffs / max(abs(value), 1e-30)
valid_idx = rel_diffs < 0.5
if np.any(rel_diffs < 0.01):
idx = np.argmin(rel_diffs)
return n, beta, dynamic_scale, diffs[idx], r_grid[idx], k_grid[idx]
if np.any(valid_idx):
candidates.extend([(diffs[i], n, beta, dynamic_scale, r_grid[i], k_grid[i]) for i in np.where(valid_idx)[0]])
if not candidates:
logging.error(f"invert_D: No valid candidates for value {value}")
return None, None, None, None, None, None
candidates = sorted(candidates, key=lambda x: x[0])[:5]
valid_vals = [D(n, beta, r, k, Omega, base, scale * s)
for _, n, beta, s, r, k in candidates if D(n, beta, r, k, Omega, base, scale * s) is not None]
if not valid_vals:
return None, None, None, None, None, None
emergent_uncertainty = np.std(valid_vals) if len(valid_vals) > 1 else abs(valid_vals[0]) * 0.01
if not np.isfinite(emergent_uncertainty):
logging.error(f"invert_D: Non-finite emergent uncertainty for value {value}")
return None, None, None, None, None, None
best = candidates[0]
return best[1], best[2], best[3], emergent_uncertainty, best[4], best[5]
except Exception as e:
logging.error(f"invert_D failed for value {value}: {e}")
return None, None, None, None, None, None
def parse_categorized_codata(filename):
try:
df = pd.read_csv(filename, sep='\t', header=0,
names=['name', 'value', 'uncertainty', 'unit', 'category'],
dtype={'name': str, 'value': float, 'uncertainty': float, 'unit': str, 'category': str},
na_values=['exact'])
df['uncertainty'] = df['uncertainty'].fillna(0.0)
required_columns = ['name', 'value', 'uncertainty', 'unit']
if not all(col in df.columns for col in required_columns):
missing = [col for col in required_columns if col not in df.columns]
raise ValueError(f"Missing required columns in {filename}: {missing}")
logging.info(f"Successfully parsed {len(df)} constants from {filename}")
return df
except FileNotFoundError:
logging.error(f"Input file {filename} not found")
raise
except Exception as e:
logging.error(f"Error parsing {filename}: {e}")
raise
def generate_emergent_constants(n_max=1000, beta_steps=10, r_values=[0.5, 1.0, 2.0], k_values=[0.5, 1.0, 2.0], Omega=1.0, base=2, scale=1.0):
candidates = []
n_values = np.linspace(0, n_max, 100)
beta_values = np.linspace(0, 1, beta_steps)
for n in tqdm(n_values, desc="Generating emergent constants"):
for beta in beta_values:
for r in r_values:
for k in k_values:
val = D(n, beta, r, k, Omega, base, scale)
if val is not None and np.isfinite(val):
candidates.append({
'n': n, 'beta': beta, 'value': val, 'r': r, 'k': k, 'scale': scale
})
return pd.DataFrame(candidates)
def match_to_codata(df_emergent, df_codata, tolerance=0.01, batch_size=100):
matches = []
output_file = "emergent_constants.txt"
with open(output_file, 'w', encoding='utf-8') as f:
pd.DataFrame(columns=['name', 'codata_value', 'emergent_value', 'n', 'beta', 'r', 'k', 'scale', 'error', 'rel_error', 'codata_uncertainty', 'bad_data', 'bad_data_reason']).to_csv(f, sep="\t", index=False)
for start in range(0, len(df_codata), batch_size):
batch = df_codata.iloc[start:start + batch_size]
for _, codata_row in tqdm(batch.iterrows(), total=len(batch), desc=f"Matching constants batch {start//batch_size + 1}"):
value = codata_row['value']
mask = abs(df_emergent['value'] - value) / max(abs(value), 1e-30) < tolerance
matched = df_emergent[mask]
for _, emergent_row in matched.iterrows():
error = abs(emergent_row['value'] - value)
rel_error = error / max(abs(value), 1e-30)
matches.append({
'name': codata_row['name'],
'codata_value': value,
'emergent_value': emergent_row['value'],
'n': emergent_row['n'],
'beta': emergent_row['beta'],
'r': emergent_row['r'],
'k': emergent_row['k'],
'scale': emergent_row['scale'],
'error': error,
'rel_error': rel_error,
'codata_uncertainty': codata_row['uncertainty'],
'bad_data': rel_error > 0.5 or (codata_row['uncertainty'] is not None and abs(codata_row['uncertainty'] - error) > 10 * codata_row['uncertainty']),
'bad_data_reason': f"High rel_error ({rel_error:.2e})" if rel_error > 0.5 else f"Uncertainty deviation ({codata_row['uncertainty']:.2e} vs. {error:.2e})" if (codata_row['uncertainty'] is not None and abs(codata_row['uncertainty'] - error) > 10 * codata_row['uncertainty']) else ""
})
try:
with open(output_file, 'a', encoding='utf-8') as f:
pd.DataFrame(matches).to_csv(f, sep="\t", index=False, header=False, lineterminator='\n')
f.flush()
matches = []
except Exception as e:
logging.error(f"Failed to save batch {start//batch_size + 1} to {output_file}: {e}")
return pd.DataFrame(pd.read_csv(output_file, sep='\t'))
def check_physical_consistency(df_results):
bad_data = []
relations = [
('Planck constant', 'reduced Planck constant', lambda x, y: abs(x['scale'] / y['scale'] - 2 * np.pi), 0.1, 'scale ratio vs. 2π'),
('proton mass', 'proton-electron mass ratio', lambda x, y: abs(x['n'] - y['n'] - np.log10(1836)), 0.5, 'n difference vs. log(proton-electron ratio)'),
('Fermi coupling constant', 'weak mixing angle', lambda x, y: abs(x['scale'] - y['scale'] / np.sqrt(2)), 0.1, 'scale vs. sin²θ_W/√2'),
('tau energy equivalent', 'tau mass energy equivalent in MeV', lambda x, y: abs(x['codata_value'] - y['codata_value']), 0.01, 'value consistency'),
('proton mass', 'electron mass', 'proton-electron mass ratio',
lambda x, y, z: abs(z['n'] - abs(x['n'] - y['n'])), 10.0, 'n inconsistency for mass ratio'),
('fine-structure constant', 'elementary charge', 'Planck constant',
lambda x, y, z: abs(x['codata_value'] - y['codata_value']**2 / (4 * np.pi * 8.854187817e-12 * z['codata_value'] * 299792458)), 0.01, 'fine-structure vs. e²/(4πε₀hc)'),
('Bohr magneton', 'elementary charge', 'Planck constant',
lambda x, y, z: abs(x['codata_value'] - y['codata_value'] * z['codata_value'] / (2 * 9.1093837e-31)), 0.01, 'Bohr magneton vs. eh/(2m_e)')
]
for relation in relations:
try:
if len(relation) == 5:
name1, name2, check_func, threshold, reason = relation
if name1 in df_results['name'].values and name2 in df_results['name'].values:
row1 = df_results[df_results['name'] == name1].iloc[0]
row2 = df_results[df_results['name'] == name2].iloc[0]
if check_func(row1, row2) > threshold:
bad_data.append((name1, f"Physical inconsistency: {reason}"))
bad_data.append((name2, f"Physical inconsistency: {reason}"))
elif len(relation) == 6:
name1, name2, name3, check_func, threshold, reason = relation
if all(name in df_results['name'].values for name in [name1, name2, name3]):
row1 = df_results[df_results['name'] == name1].iloc[0]
row2 = df_results[df_results['name'] == name2].iloc[0]
row3 = df_results[df_results['name'] == name3].iloc[0]
if check_func(row1, row2, row3) > threshold:
bad_data.append((name3, f"Physical inconsistency: {reason}"))
except Exception as e:
logging.warning(f"Physical consistency check failed for {relation}: {e}")
continue
return bad_data
def total_error(params, df_subset):
r, k, Omega, base, scale = params
df_results = symbolic_fit_all_constants(df_subset, base=base, Omega=Omega, r=r, k=k, scale=scale)
if df_results.empty:
return np.inf
valid_errors = df_results['error'].dropna()
return valid_errors.mean() if not valid_errors.empty else np.inf
def process_constant(row, r, k, Omega, base, scale):
try:
name, value, uncertainty, unit = row['name'], row['value'], row['uncertainty'], row['unit']
abs_value = abs(value)
sign = np.sign(value)
result = invert_D(abs_value, r=r, k=k, Omega=Omega, base=base, scale=scale)
if result[0] is None:
logging.warning(f"No valid fit for {name}")
return {
'name': name, 'codata_value': value, 'unit': unit, 'n': None, 'beta': None, 'emergent_value': None,
'error': None, 'rel_error': None, 'codata_uncertainty': uncertainty, 'emergent_uncertainty': None,
'scale': None, 'bad_data': True, 'bad_data_reason': 'No valid fit found', 'r': None, 'k': None
}
n, beta, dynamic_scale, emergent_uncertainty, r_local, k_local = result
approx = D(n, beta, r_local, k_local, Omega, base, scale * dynamic_scale)
if approx is None:
logging.warning(f"D returned None for {name}")
return {
'name': name, 'codata_value': value, 'unit': unit, 'n': None, 'beta': None, 'emergent_value': None,
'error': None, 'rel_error': None, 'codata_uncertainty': uncertainty, 'emergent_uncertainty': None,
'scale': None, 'bad_data': True, 'bad_data_reason': 'D function returned None', 'r': None, 'k': None
}
approx *= sign
error = abs(approx - value)
rel_error = error / max(abs(value), 1e-30) if abs(value) > 0 else np.inf
bad_data = False
bad_data_reason = ""
if rel_error > 0.5:
bad_data = True
bad_data_reason += f"High relative error ({rel_error:.2e} > 0.5); "
if emergent_uncertainty is not None and uncertainty is not None:
if emergent_uncertainty > uncertainty * 20 or emergent_uncertainty < uncertainty / 20:
bad_data = True
bad_data_reason += f"Uncertainty deviates from emergent ({emergent_uncertainty:.2e} vs. {uncertainty:.2e}); "
return {
'name': name, 'codata_value': value, 'unit': unit, 'n': n, 'beta': beta, 'emergent_value': approx,
'error': error, 'rel_error': rel_error, 'codata_uncertainty': uncertainty,
'emergent_uncertainty': emergent_uncertainty, 'scale': scale * dynamic_scale,
'bad_data': bad_data, 'bad_data_reason': bad_data_reason, 'r': r_local, 'k': k_local
}
except Exception as e:
logging.error(f"process_constant failed for {row['name']}: {e}")
return {
'name': row['name'], 'codata_value': row['value'], 'unit': row['unit'], 'n': None, 'beta': None,
'emergent_value': None, 'error': None, 'rel_error': None, 'codata_uncertainty': row['uncertainty'],
'emergent_uncertainty': None, 'scale': None, 'bad_data': True, 'bad_data_reason': f"Processing error: {str(e)}",
'r': None, 'k': None
}
def symbolic_fit_all_constants(df, base=2, Omega=1.0, r=1.0, k=1.0, scale=1.0, batch_size=100):
logging.info("Starting symbolic fit for all constants...")
results = []
output_file = "symbolic_fit_results_emergent_fixed.txt"
with open(output_file, 'w', encoding='utf-8') as f:
pd.DataFrame(columns=['name', 'codata_value', 'unit', 'n', 'beta', 'emergent_value', 'error', 'rel_error',
'codata_uncertainty', 'emergent_uncertainty', 'scale', 'bad_data', 'bad_data_reason', 'r', 'k']).to_csv(f, sep="\t", index=False)
for start in range(0, len(df), batch_size):
batch = df.iloc[start:start + batch_size]
try:
batch_results = Parallel(n_jobs=12, timeout=120, backend='loky', maxtasksperchild=20)(
delayed(process_constant)(row, r, k, Omega, base, scale)
for row in tqdm(batch.to_dict('records'), total=len(batch), desc=f"Fitting constants batch {start//batch_size + 1}")
)
batch_results = [r for r in batch_results if r is not None]
results.extend(batch_results)
try:
with open(output_file, 'a', encoding='utf-8') as f:
pd.DataFrame(batch_results).to_csv(f, sep="\t", index=False, header=False, lineterminator='\n')
f.flush()
except Exception as e:
logging.error(f"Failed to save batch {start//batch_size + 1} to {output_file}: {e}")
except Exception as e:
logging.error(f"Parallel processing failed for batch {start//batch_size + 1}: {e}")
continue
df_results = pd.DataFrame(results)
if not df_results.empty:
df_results['bad_data'] = df_results.get('bad_data', False)
df_results['bad_data_reason'] = df_results.get('bad_data_reason', '')
for name in df_results['name'].unique():
mask = df_results['name'] == name
if df_results.loc[mask, 'codata_uncertainty'].notnull().any():
uncertainties = df_results.loc[mask, 'codata_uncertainty'].dropna()
if not uncertainties.empty:
Q1, Q3 = np.percentile(uncertainties, [25, 75])
IQR = Q3 - Q1
outlier_mask = (uncertainties < Q1 - 1.5 * IQR) | (uncertainties > Q3 + 1.5 * IQR)
if outlier_mask.any():
df_results.loc[mask & df_results['codata_uncertainty'].isin(uncertainties[outlier_mask]), 'bad_data'] = True
df_results.loc[mask & df_results['codata_uncertainty'].isin(uncertainties[outlier_mask]), 'bad_data_reason'] += 'Uncertainty outlier; '
high_rel_error_mask = df_results['rel_error'] > 0.5
df_results.loc[high_rel_error_mask, 'bad_data'] = True
df_results.loc[high_rel_error_mask, 'bad_data_reason'] += df_results.loc[high_rel_error_mask, 'rel_error'].apply(lambda x: f"High relative error ({x:.2e} > 0.5); ")
high_uncertainty_mask = (df_results['emergent_uncertainty'].notnull()) & (
(df_results['codata_uncertainty'] > 20 * df_results['emergent_uncertainty']) |
(df_results['codata_uncertainty'] < 0.05 * df_results['emergent_uncertainty'])
)
df_results.loc[high_uncertainty_mask, 'bad_data'] = True
df_results.loc[high_uncertainty_mask, 'bad_data_reason'] += df_results.loc[high_uncertainty_mask].apply(
lambda row: f"Uncertainty deviates from emergent ({row['codata_uncertainty']:.2e} vs. {row['emergent_uncertainty']:.2e}); ", axis=1)
bad_data = check_physical_consistency(df_results)
for name, reason in bad_data:
df_results.loc[df_results['name'] == name, 'bad_data'] = True
df_results.loc[df_results['name'] == name, 'bad_data_reason'] += reason + '; '
logging.info("Symbolic fit completed.")
return df_results
def select_worst_names(df, n_select=10):
categories = df['category'].unique()
n_per_category = max(1, n_select // len(categories))
selected = []
for category in categories:
cat_df = df[df['category'] == category]
if len(cat_df) > 0:
n_to_select = min(n_per_category, len(cat_df))
selected.extend(np.random.choice(cat_df['name'], size=n_to_select, replace=False))
if len(selected) < n_select:
remaining = df[~df['name'].isin(selected)]
if len(remaining) > 0:
selected.extend(np.random.choice(remaining['name'], size=n_select - len(selected), replace=False))
return selected[:n_select]
def signal_handler(sig, frame):
print("\nKeyboardInterrupt detected. Saving partial results...")
logging.info("KeyboardInterrupt detected. Exiting gracefully.")
for output_file in ["emergent_constants.txt", "symbolic_fit_results_emergent_fixed.txt"]:
try:
with open(output_file, 'a', encoding='utf-8') as f:
f.flush()
except Exception as e:
logging.error(f"Failed to flush {output_file} on interrupt: {e}")
sys.exit(0)
def main():
signal.signal(signal.SIGINT, signal_handler)
start_time = time.time()
stages = ['Parsing data', 'Generating emergent constants', 'Optimizing parameters', 'Fitting all constants', 'Generating plots']
progress = tqdm(stages, desc="Overall progress")
# Stage 1: Parse data
input_file = "categorized_allascii.txt"
if not os.path.exists(input_file):
raise FileNotFoundError(f"{input_file} not found in the current directory")
df = parse_categorized_codata(input_file)
logging.info(f"Parsed {len(df)} constants")
progress.update(1)
# Stage 2: Generate emergent constants
emergent_df = generate_emergent_constants(n_max=1000, beta_steps=10)
matched_df = match_to_codata(emergent_df, df, tolerance=0.01, batch_size=100)
logging.info("Saved emergent constants to emergent_constants.txt")
progress.update(1)
# Stage 3: Optimize parameters
worst_names = select_worst_names(df, n_select=10)
print(f"Selected constants for optimization: {worst_names}")
subset_df = df[df['name'].isin(worst_names)]
if subset_df.empty:
subset_df = df.head(50)
init_params = [0.5, 0.5, 0.5, 2.0, 0.1]
bounds = [(1e-10, 100), (1e-10, 100), (1e-10, 100), (1.5, 20), (1e-10, 1000)]
try:
res = minimize(total_error, init_params, args=(subset_df,), bounds=bounds, method='SLSQP', options={'maxiter': 50, 'disp': True})
if not res.success:
logging.warning(f"Optimization failed: {res.message}")
r_opt, k_opt, Omega_opt, base_opt, scale_opt = init_params
else:
r_opt, k_opt, Omega_opt, base_opt, scale_opt = res.x
print(f"Optimization complete. Found parameters:\nr = {r_opt:.6f}, k = {k_opt:.6f}, Omega = {Omega_opt:.6f}, base = {base_opt:.6f}, scale = {scale_opt:.6f}")
except Exception as e:
logging.error(f"Optimization failed: {e}")
r_opt, k_opt, Omega_opt, base_opt, scale_opt = init_params
print(f"Optimization failed: {e}. Using default parameters.")
progress.update(1)
# Stage 4: Run final fit
df_results = symbolic_fit_all_constants(df, base=base_opt, Omega=Omega_opt, r=r_opt, k=k_opt, scale=scale_opt, batch_size=100)
if not df_results.empty:
with open("symbolic_fit_results.txt", 'w', encoding='utf-8') as f:
df_results.to_csv(f, sep="\t", index=False)
f.flush()
logging.info(f"Saved final results to symbolic_fit_results.txt")
else:
logging.error("No results to save")
progress.update(1)
# Stage 5: Generate plots
df_results_sorted = df_results.sort_values("error", na_position='last')
print("\nTop 20 best symbolic fits:")
print(df_results_sorted.head(20)[['name', 'codata_value', 'unit', 'n', 'beta', 'emergent_value', 'error', 'codata_uncertainty', 'scale', 'bad_data', 'bad_data_reason']].to_string(index=False))
print("\nTop 20 worst symbolic fits:")
print(df_results_sorted.tail(20)[['name', 'codata_value', 'unit', 'n', 'beta', 'emergent_value', 'error', 'codata_uncertainty', 'scale', 'bad_data', 'bad_data_reason']].to_string(index=False))
print("\nPotentially bad data constants summary (possible cheated data):")
bad_data_df = df_results[df_results['bad_data'] == True][['name', 'codata_value', 'error', 'rel_error', 'codata_uncertainty', 'emergent_uncertainty', 'bad_data_reason']]
bad_data_df = bad_data_df.sort_values('rel_error', ascending=False, na_position='last')
print(bad_data_df.to_string(index=False))
print("\nTop 20 emergent constants matches:")
matched_df_sorted = matched_df.sort_values('error', na_position='last')
print(matched_df_sorted.head(20)[['name', 'codata_value', 'emergent_value', 'n', 'beta', 'error', 'rel_error', 'codata_uncertainty', 'bad_data', 'bad_data_reason']].to_string(index=False))
plt.figure(figsize=(10, 5))
plt.hist(df_results_sorted['error'].dropna(), bins=50, color='skyblue', edgecolor='black')
plt.title('Histogram of Absolute Errors in Symbolic Fit')
plt.xlabel('Absolute Error')
plt.ylabel('Count')
plt.grid(True)
plt.tight_layout()
plt.savefig('histogram_errors.png')
plt.close()
plt.figure(figsize=(10, 5))
plt.scatter(df_results_sorted['n'], df_results_sorted['error'], alpha=0.5, s=15, c='orange', edgecolors='black')
plt.title('Absolute Error vs Symbolic Dimension n (Fitted)')
plt.xlabel('n')
plt.ylabel('Absolute Error')
plt.grid(True)
plt.tight_layout()
plt.savefig('scatter_n_error.png')
plt.close()
plt.figure(figsize=(10, 5))
worst_fits = df_results_sorted.tail(20)
plt.bar(worst_fits['name'], worst_fits['error'], color='salmon', edgecolor='black')
plt.xticks(rotation=90)
plt.title('Absolute Errors for Top 20 Worst Symbolic Fits')
plt.xlabel('Constant Name')
plt.ylabel('Absolute Error')
plt.grid(True)
plt.tight_layout()
plt.savefig('bar_worst_fits.png')
plt.close()
plt.figure(figsize=(10, 5))
plt.scatter(matched_df_sorted['codata_value'], matched_df_sorted['emergent_value'], alpha=0.5, s=15, c='purple', edgecolors='black')
plt.plot([matched_df_sorted['codata_value'].min(), matched_df_sorted['codata_value'].max()],
[matched_df_sorted['codata_value'].min(), matched_df_sorted['codata_value'].max()], 'k--')
plt.title('Emergent Constants vs. CODATA Values')
plt.xlabel('CODATA Value')
plt.ylabel('Emergent Value')
plt.grid(True)
plt.tight_layout()
plt.savefig('scatter_codata_emergent.png')
plt.close()
progress.update(1)
logging.info(f"Total runtime: {time.time() - start_time:.2f} seconds")
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt:
signal_handler(None, None)
gpu1_optimized2.py
import numpy as np
import pandas as pd
import re
import matplotlib.pyplot as plt
from scipy.optimize import minimize
from tqdm import tqdm
from joblib import Parallel, delayed
# Extended primes list (up to 1000)
PRIMES = [
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71,
73, 79, 83, 89, 97, 101, 103, 107, 109, 113, 127, 131, 137, 139, 149, 151,
157, 163, 167, 173, 179, 181, 191, 193, 197, 199, 211, 223, 227, 229, 233,
239, 241, 251, 257, 263, 269, 271, 277, 281, 283, 293, 307, 311, 313, 317,
331, 337, 347, 349, 353, 359, 367, 373, 379, 383, 389, 397, 401, 409, 419,
421, 431, 433, 439, 443, 449, 457, 461, 463, 467, 479, 487, 491, 499, 503,
509, 521, 523, 541, 547, 557, 563, 569, 571, 577, 587, 593, 599, 601, 607,
613, 617, 619, 631, 641, 643, 647, 653, 659, 661, 673, 677, 683, 691, 701,
709, 719, 727, 733, 739, 743, 751, 757, 761, 769, 773, 787, 797, 809, 811,
821, 823, 827, 829, 839, 853, 857, 859, 863, 877, 881, 883, 887, 907, 911,
919, 929, 937, 941, 947, 953, 967, 971, 977, 983, 991, 997
]
phi = (1 + np.sqrt(5)) / 2
fib_cache = {}
def fib_real(n):
if n in fib_cache:
return fib_cache[n]
from math import cos, pi, sqrt
phi_inv = 1 / phi
if n > 100:
return 0.0
term1 = phi**n / sqrt(5)
term2 = (phi_inv**n) * cos(pi * n)
result = term1 - term2
fib_cache[n] = result
return result
def D(n, beta, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0):
Fn_beta = fib_real(n + beta)
idx = int(np.floor(n + beta) + len(PRIMES)) % len(PRIMES)
Pn_beta = PRIMES[idx]
dyadic = base ** (n + beta)
val = scale * phi * Fn_beta * dyadic * Pn_beta * Omega
val = np.maximum(val, 1e-30)
return np.sqrt(val) * (r ** k)
def invert_D(value, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0, max_n=500, steps=500):
candidates = []
log_val = np.log10(max(abs(value), 1e-30))
scale_factors = np.logspace(log_val - 2, log_val + 2, num=10)
# Adjust max_n based on constant magnitude
max_n = min(max_n, max(50, int(10 * log_val)))
for n in np.linspace(0, max_n, steps):
for beta in np.linspace(0, 1, 10):
for dynamic_scale in scale_factors:
val = D(n, beta, r, k, Omega, base, scale * dynamic_scale)
diff = abs(val - value)
candidates.append((diff, n, beta, dynamic_scale))
best = min(candidates, key=lambda x: x[0])
return best[1], best[2], best[3]
def parse_codata_ascii(filename):
constants = []
pattern = re.compile(r"^\s*(.*?)\s{2,}([0-9Ee\+\-\.]+)\s+([0-9Ee\+\-\.]+|exact)\s+(\S+)")
with open(filename, "r") as f:
for line in f:
if line.startswith("Quantity") or line.strip() == "" or line.startswith("-"):
continue
m = pattern.match(line)
if m:
name, value_str, uncert_str, unit = m.groups()
try:
value = float(value_str.replace("e", "E"))
uncertainty = None if uncert_str == "exact" else float(uncert_str.replace("e", "E"))
constants.append({
"name": name.strip(),
"value": value,
"uncertainty": uncertainty,
"unit": unit.strip()
})
except:
continue
return pd.DataFrame(constants)
def fit_single_constant(row, r, k, Omega, base, scale, max_n, steps):
val = row['value']
if val <= 0 or val > 1e50:
return None
try:
n, beta, dynamic_scale = invert_D(val, r, k, Omega, base, scale, max_n, steps)
approx = D(n, beta, r, k, Omega, base, scale * dynamic_scale)
error = abs(val - approx)
return {
"name": row['name'],
"value": val,
"unit": row['unit'],
"n": n,
"beta": beta,
"approx": approx,
"error": error,
"uncertainty": row['uncertainty'],
"scale": dynamic_scale
}
except Exception as e:
print(f"Failed inversion for {row['name']}: {e}")
return None
def symbolic_fit_all_constants(df, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0, max_n=500, steps=500):
results = Parallel(n_jobs=20)(
delayed(fit_single_constant)(row, r, k, Omega, base, scale, max_n, steps)
for _, row in df.iterrows()
)
return pd.DataFrame([r for r in results if r is not None])
def total_error(params, df):
r, k, Omega, base, scale = params
df_fit = symbolic_fit_all_constants(df, r=r, k=k, Omega=Omega, base=base, scale=scale, max_n=500, steps=500)
threshold = np.percentile(df_fit['error'], 95)
filtered = df_fit[df_fit['error'] <= threshold]
rel_err = ((filtered['value'] - filtered['approx']) / filtered['value'])**2
return rel_err.sum()
if __name__ == "__main__":
print("Parsing CODATA constants from allascii.txt...")
codata_df = parse_codata_ascii("allascii.txt")
print(f"Parsed {len(codata_df)} constants.")
# Use a subset for optimization
subset_df = codata_df.head(20)
init_params = [1.0, 1.0, 1.0, 2.0, 1.0]
bounds = [(1e-5, 10), (1e-5, 10), (1e-5, 10), (1.5, 10), (1e-5, 100)]
print("Optimizing symbolic model parameters...")
res = minimize(total_error, init_params, args=(subset_df,), bounds=bounds, method='L-BFGS-B', options={'maxiter': 100})
r_opt, k_opt, Omega_opt, base_opt, scale_opt = res.x
print(f"Optimization complete. Found parameters:\nr = {r_opt:.6f}, k = {k_opt:.6f}, Omega = {Omega_opt:.6f}, base = {base_opt:.6f}, scale = {scale_opt:.6f}")
print("Fitting symbolic dimensions to all constants...")
fitted_df = symbolic_fit_all_constants(codata_df, r=r_opt, k=k_opt, Omega=Omega_opt, base=base_opt, scale=scale_opt, max_n=500, steps=500)
fitted_df_sorted = fitted_df.sort_values("error")
print("\nTop 20 best symbolic fits:")
print(fitted_df_sorted.head(20).to_string(index=False))
print("\nTop 20 worst symbolic fits:")
print(fitted_df_sorted.tail(20).to_string(index=False))
fitted_df_sorted.to_csv("symbolic_fit_results.txt", sep="\t", index=False)
plt.figure(figsize=(10, 5))
plt.hist(fitted_df_sorted['error'], bins=50, color='skyblue', edgecolor='black')
plt.title('Histogram of Absolute Errors in Symbolic Fit')
plt.xlabel('Absolute Error')
plt.ylabel('Count')
plt.grid(True)
plt.tight_layout()
plt.show()
plt.figure(figsize=(10, 5))
plt.scatter(fitted_df_sorted['n'], fitted_df_sorted['error'], alpha=0.5, s=15, c='orange', edgecolors='black')
plt.title('Absolute Error vs Symbolic Dimension n')
plt.xlabel('n')
plt.ylabel('Absolute Error')
plt.grid(True)
plt.tight_layout()
plt.show()
fudge10_fixed.py
import numpy as np
import pandas as pd
import re
import matplotlib.pyplot as plt
from scipy.optimize import minimize
from tqdm import tqdm
from joblib import Parallel, delayed
# Extended primes list (up to 1000)
PRIMES = [
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71,
73, 79, 83, 89, 97, 101, 103, 107, 109, 113, 127, 131, 137, 139, 149, 151,
157, 163, 167, 173, 179, 181, 191, 193, 197, 199, 211, 223, 227, 229, 233,
239, 241, 251, 257, 263, 269, 271, 277, 281, 283, 293, 307, 311, 313, 317,
331, 337, 347, 349, 353, 359, 367, 373, 379, 383, 389, 397, 401, 409, 419,
421, 431, 433, 439, 443, 449, 457, 461, 463, 467, 479, 487, 491, 499, 503,
509, 521, 523, 541, 547, 557, 563, 569, 571, 577, 587, 593, 599, 601, 607,
613, 617, 619, 631, 641, 643, 647, 653, 659, 661, 673, 677, 683, 691, 701,
709, 719, 727, 733, 739, 743, 751, 757, 761, 769, 773, 787, 797, 809, 811,
821, 823, 827, 829, 839, 853, 857, 859, 863, 877, 881, 883, 887, 907, 911,
919, 929, 937, 941, 947, 953, 967, 971, 977, 983, 991, 997
]
phi = (1 + np.sqrt(5)) / 2
fib_cache = {}
def fib_real(n):
if n in fib_cache:
return fib_cache[n]
from math import cos, pi, sqrt
phi_inv = 1 / phi
if n > 100:
return 0.0
term1 = phi**n / sqrt(5)
term2 = (phi_inv**n) * cos(pi * n)
result = term1 - term2
fib_cache[n] = result
return result
def D(n, beta, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0):
Fn_beta = fib_real(n + beta)
idx = int(np.floor(n + beta) + len(PRIMES)) % len(PRIMES)
Pn_beta = PRIMES[idx]
dyadic = base ** (n + beta)
val = scale * phi * Fn_beta * dyadic * Pn_beta * Omega
val = np.maximum(val, 1e-30)
return np.sqrt(val) * (r ** k)
def invert_D(value, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0, max_n=500, steps=500):
candidates = []
log_val = np.log10(max(abs(value), 1e-30))
scale_factors = np.logspace(log_val - 2, log_val + 2, num=10)
# Adjust max_n based on constant magnitude
max_n = min(max_n, max(50, int(10 * log_val)))
for n in np.linspace(0, max_n, steps):
for beta in np.linspace(0, 1, 10):
for dynamic_scale in scale_factors:
val = D(n, beta, r, k, Omega, base, scale * dynamic_scale)
diff = abs(val - value)
candidates.append((diff, n, beta, dynamic_scale))
best = min(candidates, key=lambda x: x[0])
return best[1], best[2], best[3]
def parse_codata_ascii(filename):
constants = []
pattern = re.compile(r"^\s*(.*?)\s{2,}([0-9Ee\+\-\.]+)\s+([0-9Ee\+\-\.]+|exact)\s+(\S+)")
with open(filename, "r") as f:
for line in f:
if line.startswith("Quantity") or line.strip() == "" or line.startswith("-"):
continue
m = pattern.match(line)
if m:
name, value_str, uncert_str, unit = m.groups()
try:
value = float(value_str.replace("e", "E"))
uncertainty = None if uncert_str == "exact" else float(uncert_str.replace("e", "E"))
constants.append({
"name": name.strip(),
"value": value,
"uncertainty": uncertainty,
"unit": unit.strip()
})
except:
continue
return pd.DataFrame(constants)
def fit_single_constant(row, r, k, Omega, base, scale, max_n, steps):
val = row['value']
if val <= 0 or val > 1e50:
return None
try:
n, beta, dynamic_scale = invert_D(val, r, k, Omega, base, scale, max_n, steps)
approx = D(n, beta, r, k, Omega, base, scale * dynamic_scale)
error = abs(val - approx)
return {
"name": row['name'],
"value": val,
"unit": row['unit'],
"n": n,
"beta": beta,
"approx": approx,
"error": error,
"uncertainty": row['uncertainty'],
"scale": dynamic_scale
}
except Exception as e:
print(f"Failed inversion for {row['name']}: {e}")
return None
def symbolic_fit_all_constants(df, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0, max_n=500, steps=500):
results = Parallel(n_jobs=20)(
delayed(fit_single_constant)(row, r, k, Omega, base, scale, max_n, steps)
for _, row in df.iterrows()
)
return pd.DataFrame([r for r in results if r is not None])
def total_error(params, df):
r, k, Omega, base, scale = params
df_fit = symbolic_fit_all_constants(df, r=r, k=k, Omega=Omega, base=base, scale=scale, max_n=500, steps=500)
threshold = np.percentile(df_fit['error'], 95)
filtered = df_fit[df_fit['error'] <= threshold]
rel_err = ((filtered['value'] - filtered['approx']) / filtered['value'])**2
return rel_err.sum()
if __name__ == "__main__":
print("Parsing CODATA constants from allascii.txt...")
codata_df = parse_codata_ascii("allascii.txt")
print(f"Parsed {len(codata_df)} constants.")
# Use a subset for optimization
subset_df = codata_df.head(20)
init_params = [1.0, 1.0, 1.0, 2.0, 1.0]
bounds = [(1e-5, 10), (1e-5, 10), (1e-5, 10), (1.5, 10), (1e-5, 100)]
print("Optimizing symbolic model parameters...")
res = minimize(total_error, init_params, args=(subset_df,), bounds=bounds, method='L-BFGS-B', options={'maxiter': 100})
r_opt, k_opt, Omega_opt, base_opt, scale_opt = res.x
print(f"Optimization complete. Found parameters:\nr = {r_opt:.6f}, k = {k_opt:.6f}, Omega = {Omega_opt:.6f}, base = {base_opt:.6f}, scale = {scale_opt:.6f}")
print("Fitting symbolic dimensions to all constants...")
fitted_df = symbolic_fit_all_constants(codata_df, r=r_opt, k=k_opt, Omega=Omega_opt, base=base_opt, scale=scale_opt, max_n=500, steps=500)
fitted_df_sorted = fitted_df.sort_values("error")
print("\nTop 20 best symbolic fits:")
print(fitted_df_sorted.head(20).to_string(index=False))
print("\nTop 20 worst symbolic fits:")
print(fitted_df_sorted.tail(20).to_string(index=False))
fitted_df_sorted.to_csv("symbolic_fit_results.txt", sep="\t", index=False)
plt.figure(figsize=(10, 5))
plt.hist(fitted_df_sorted['error'], bins=50, color='skyblue', edgecolor='black')
plt.title('Histogram of Absolute Errors in Symbolic Fit')
plt.xlabel('Absolute Error')
plt.ylabel('Count')
plt.grid(True)
plt.tight_layout()
plt.show()
plt.figure(figsize=(10, 5))
plt.scatter(fitted_df_sorted['n'], fitted_df_sorted['error'], alpha=0.5, s=15, c='orange', edgecolors='black')
plt.title('Absolute Error vs Symbolic Dimension n')
plt.xlabel('n')
plt.ylabel('Absolute Error')
plt.grid(True)
plt.tight_layout()
plt.show()
fudge7.py
import numpy as np
import pandas as pd
import re
from scipy.optimize import minimize
from tqdm import tqdm
from joblib import Parallel, delayed
import logging
import time
import matplotlib.pyplot as plt
import os
# Set up logging
logging.basicConfig(filename='symbolic_fit.log', level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# Primes list
PRIMES = [
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71,
73, 79, 83, 89, 97, 101, 103, 107, 109, 113, 127, 131, 137, 139, 149, 151,
157, 163, 167, 173, 179, 181, 191, 193, 197, 199, 211, 223, 227, 229, 233,
239, 241, 251, 257, 263, 269, 271, 277, 281, 283, 293, 307, 311, 313, 317,
331, 337, 347, 349, 353, 359, 367, 373, 379, 383, 389, 397, 401, 409, 419,
421, 431, 433, 439, 443, 449, 457, 461, 463, 467, 479, 487, 491, 499, 503,
509, 521, 523, 541, 547, 557, 563, 569, 571, 577, 587, 593, 599, 601, 607,
613, 617, 619, 631, 641, 643, 647, 653, 659, 661, 673, 677, 683, 691, 701,
709, 719, 727, 733, 739, 743, 751, 757, 761, 769, 773, 787, 797, 809, 811,
821, 823, 827, 829, 839, 853, 857, 859, 863, 877, 881, 883, 887, 907, 911,
919, 929, 937, 941, 947, 953, 967, 971, 977, 983, 991, 997
]
phi = (1 + np.sqrt(5)) / 2
fib_cache = {}
def fib_real(n):
if n in fib_cache:
return fib_cache[n]
if n > 100:
return 0.0
term1 = phi**n / np.sqrt(5)
term2 = ((1/phi)**n) * np.cos(np.pi * n)
result = term1 - term2
fib_cache[n] = result
return result
def D(n, beta, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0):
try:
Fn_beta = fib_real(n + beta)
idx = int(np.floor(n + beta) + len(PRIMES)) % len(PRIMES)
Pn_beta = PRIMES[idx]
# Use logarithmic form to avoid overflow
log_dyadic = (n + beta) * np.log(base)
if log_dyadic > 500: # Prevent overflow
return None
log_val = np.log(scale) + np.log(phi) + np.log(abs(Fn_beta) + 1e-30) + log_dyadic + np.log(Pn_beta) + np.log(Omega)
if n > 1000:
log_val += np.log(np.log(n) / np.log(1000))
if not np.isfinite(log_val):
return None
val = np.exp(log_val)
return np.sqrt(max(val, 1e-30)) * (r ** k)
except Exception as e:
logging.error(f"D failed: n={n}, beta={beta}, error={e}")
return None
def invert_D(value, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0, max_n=500):
candidates = []
log_val = np.log10(max(abs(value), 1e-30))
max_n = min(1000, max(500, int(200 * log_val)))
n_values = np.linspace(0, max_n, 50)
scale_factors = np.logspace(max(log_val - 2, -10), min(log_val + 2, 10), num=10)
try:
for n in tqdm(n_values, desc=f"invert_D for {value:.2e}", leave=False):
for beta in np.linspace(0, 1, 5):
for dynamic_scale in scale_factors:
for r_local in [0.5, 1.0]:
for k_local in [0.5, 1.0]:
val = D(n, beta, r_local, k_local, Omega, base, scale * dynamic_scale)
if val is None:
continue
diff = abs(val - value)
candidates.append((diff, n, beta, dynamic_scale, r_local, k_local))
if not candidates:
logging.error(f"invert_D: No valid candidates for value {value}")
return None
candidates = sorted(candidates, key=lambda x: x[0])[:20]
best = candidates[0]
emergent_uncertainty = np.std([D(n, beta, r, k, Omega, base, scale * s)
for _, n, beta, s, r, k in candidates if D(n, beta, r, k, Omega, base, scale * s) is not None])
if not np.isfinite(emergent_uncertainty):
logging.error(f"invert_D: Non-finite emergent uncertainty for value {value}")
return None
return best[1], best[2], best[3], emergent_uncertainty, best[4], best[5]
except Exception as e:
logging.error(f"invert_D failed for value {value}: {e}")
return None
def parse_codata_ascii(filename):
constants = []
pattern = re.compile(r"^\s*(.*?)\s{2,}(\-?\d+\.?\d*(?:\s*[Ee][\+\-]?\d+)?(?:\.\.\.)?)\s+(\-?\d+\.?\d*(?:\s*[Ee][\+\-]?\d+)?|exact)\s+(\S.*)")
with open(filename, "r") as f:
for line in f:
if line.startswith("Quantity") or line.strip() == "" or line.startswith("-"):
continue
m = pattern.match(line)
if m:
name, value_str, uncert_str, unit = m.groups()
try:
value = float(value_str.replace("...", "").replace(" ", ""))
uncertainty = 0.0 if uncert_str == "exact" else float(uncert_str.replace("...", "").replace(" ", ""))
constants.append({
"name": name.strip(),
"value": value,
"uncertainty": uncertainty,
"unit": unit.strip()
})
except Exception as e:
logging.warning(f"Failed parsing line: {line.strip()} - {e}")
continue
return pd.DataFrame(constants)
def check_physical_consistency(df_results):
bad_data = []
relations = [
('Planck constant', 'reduced Planck constant', lambda x, y: abs(x['scale'] / y['scale'] - 2 * np.pi), 0.1, 'scale ratio vs. 2π'),
('proton mass', 'proton-electron mass ratio', lambda x, y: abs(x['n'] - y['n'] - np.log10(1836)), 0.5, 'n difference vs. log(proton-electron ratio)'),
('Fermi coupling constant', 'weak mixing angle', lambda x, y: abs(x['scale'] - y['scale'] / np.sqrt(2)), 0.1, 'scale vs. sin²θ_W/√2'),
('tau energy equivalent', 'tau mass energy equivalent in MeV', lambda x, y: abs(x['value'] - y['value']), 0.01, 'value consistency')
]
for name1, name2, check_func, threshold, reason in relations:
try:
row1 = df_results[df_results['name'] == name1].iloc[0]
row2 = df_results[df_results['name'] == name2].iloc[0]
if check_func(row1, row2) > threshold:
bad_data.append((name1, f"Physical inconsistency: {reason}"))
bad_data.append((name2, f"Physical inconsistency: {reason}"))
except IndexError:
continue
return bad_data
def total_error(params, df_subset):
r, k, Omega, base, scale = params
df_results = symbolic_fit_all_constants(df_subset, base=base, Omega=Omega, r=r, k=k, scale=scale)
if df_results.empty:
return np.inf
error = df_results['error'].mean()
return error if np.isfinite(error) else np.inf
def symbolic_fit_all_constants(df, base=2, Omega=1.0, r=1.0, k=1.0, scale=1.0):
logging.info("Starting symbolic fit for all constants...")
results = []
def process_constant(row):
try:
result = invert_D(row['value'], r=r, k=k, Omega=Omega, base=base, scale=scale)
if result is None:
logging.error(f"Failed inversion for {row['name']}: {row['value']}")
return None
n, beta, dynamic_scale, emergent_uncertainty, r_local, k_local = result
approx = D(n, beta, r_local, k_local, Omega, base, scale * dynamic_scale)
if approx is None:
return None
error = abs(approx - row['value'])
rel_error = error / max(abs(row['value']), 1e-30)
return {
'name': row['name'], 'value': row['value'], 'unit': row['unit'],
'n': n, 'beta': beta, 'approx': approx, 'error': error,
'rel_error': rel_error, 'uncertainty': row['uncertainty'],
'emergent_uncertainty': emergent_uncertainty, 'r_local': r_local,
'k_local': k_local, 'scale': scale * dynamic_scale
}
except Exception as e:
logging.error(f"Error processing {row['name']}: {e}")
return None
results = Parallel(n_jobs=-1, timeout=15, backend='loky', maxtasksperchild=100)(
delayed(process_constant)(row) for row in tqdm(df.to_dict('records'), desc="Fitting constants")
)
results = [r for r in results if r is not None]
df_results = pd.DataFrame(results)
if not df_results.empty:
df_results['bad_data'] = False
df_results['bad_data_reason'] = ''
for name in df_results['name'].unique():
mask = df_results['name'] == name
if df_results.loc[mask, 'uncertainty'].notnull().any():
uncertainties = df_results.loc[mask, 'uncertainty'].dropna()
if not uncertainties.empty:
Q1, Q3 = np.percentile(uncertainties, [25, 75])
IQR = Q3 - Q1
outlier_mask = (uncertainties < Q1 - 1.5 * IQR) | (uncertainties > Q3 + 1.5 * IQR)
if outlier_mask.any():
df_results.loc[mask & df_results['uncertainty'].isin(uncertainties[outlier_mask]), 'bad_data'] = True
df_results.loc[mask & df_results['uncertainty'].isin(uncertainties[outlier_mask]), 'bad_data_reason'] += 'Uncertainty outlier; '
high_rel_error_mask = df_results['rel_error'] > 0.5
df_results.loc[high_rel_error_mask, 'bad_data'] = True
df_results.loc[high_rel_error_mask, 'bad_data_reason'] += df_results.loc[high_rel_error_mask, 'rel_error'].apply(lambda x: f"High relative uncertainty ({x:.2e} > 0.5); ")
high_uncertainty_mask = df_results['uncertainty'] > 2 * df_results['emergent_uncertainty']
df_results.loc[high_uncertainty_mask, 'bad_data'] = True
df_results.loc[high_uncertainty_mask, 'bad_data_reason'] += df_results.loc[high_uncertainty_mask].apply(
lambda row: f"Uncertainty deviates from emergent ({row['uncertainty']:.2e} vs. {row['emergent_uncertainty']:.2e}); ", axis=1)
bad_data = check_physical_consistency(df_results)
for name, reason in bad_data:
df_results.loc[df_results['name'] == name, 'bad_data'] = True
df_results.loc[df_results['name'] == name, 'bad_data_reason'] += reason + '; '
logging.info("Symbolic fit completed.")
return df_results
def main():
start_time = time.time()
if not os.path.exists("allascii.txt"):
raise FileNotFoundError("allascii.txt not found in the current directory")
df = parse_codata_ascii("allascii.txt")
logging.info(f"Parsed {len(df)} constants")
# Optimize parameters
subset_df = df.head(50)
init_params = [1.0, 1.0, 1.0, 2.0, 1.0] # r, k, Omega, base, scale
bounds = [(1e-5, 10), (1e-5, 10), (1e-5, 10), (1.5, 10), (1e-5, 100)]
print("Optimizing symbolic model parameters...")
res = minimize(total_error, init_params, args=(subset_df,), bounds=bounds, method='L-BFGS-B', options={'maxiter': 100})
r_opt, k_opt, Omega_opt, base_opt, scale_opt = res.x
print(f"Optimization complete. Found parameters:\nr = {r_opt:.6f}, k = {k_opt:.6f}, Omega = {Omega_opt:.6f}, base = {base_opt:.6f}, scale = {scale_opt:.6f}")
# Run final fit
df_results = symbolic_fit_all_constants(df, base=base_opt, Omega=Omega_opt, r=r_opt, k=k_opt, scale=scale_opt)
if not df_results.empty:
df_results.to_csv("symbolic_fit_results_emergent_fixed.txt", index=False)
logging.info(f"Saved results to symbolic_fit_results_emergent_fixed.txt")
else:
logging.error("No results to save")
logging.info(f"Total runtime: {time.time() - start_time:.2f} seconds")
# Display results
df_results_sorted = df_results.sort_values("error")
print("\nTop 20 best symbolic fits:")
print(df_results_sorted.head(20)[['name', 'value', 'unit', 'n', 'beta', 'approx', 'error', 'uncertainty', 'scale', 'bad_data', 'bad_data_reason']].to_string(index=False))
print("\nTop 20 worst symbolic fits:")
print(df_results_sorted.tail(20)[['name', 'value', 'unit', 'n', 'beta', 'approx', 'error', 'uncertainty', 'scale', 'bad_data', 'bad_data_reason']].to_string(index=False))
print("\nPotentially bad data constants summary:")
bad_data_df = df_results[df_results['bad_data'] == True][['name', 'value', 'error', 'rel_error', 'uncertainty', 'bad_data_reason']]
print(bad_data_df.to_string(index=False))
df_results_sorted.to_csv("symbolic_fit_results.txt", sep="\t", index=False)
# Plotting
plt.figure(figsize=(10, 5))
plt.hist(df_results_sorted['error'], bins=50, color='skyblue', edgecolor='black')
plt.title('Histogram of Absolute Errors in Symbolic Fit')
plt.xlabel('Absolute Error')
plt.ylabel('Count')
plt.grid(True)
plt.tight_layout()
plt.show()
plt.figure(figsize=(10, 5))
plt.scatter(df_results_sorted['n'], df_results_sorted['error'], alpha=0.5, s=15, c='orange', edgecolors='black')
plt.title('Absolute Error vs Symbolic Dimension n')
plt.xlabel('n')
plt.ylabel('Absolute Error')
plt.grid(True)
plt.tight_layout()
plt.show()
if __name__ == "__main__":
main()
fudge5.py
import numpy as np
import pandas as pd
import re
import matplotlib.pyplot as plt
from scipy.optimize import minimize
from tqdm import tqdm
from joblib import Parallel, delayed
import logging
import time
# Setup logging
logging.basicConfig(level=logging.INFO, filename="symbolic_fit.log", filemode="w")
# Extended primes list (up to 1000)
PRIMES = [
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71,
73, 79, 83, 89, 97, 101, 103, 107, 109, 113, 127, 131, 137, 139, 149, 151,
157, 163, 167, 173, 179, 181, 191, 193, 197, 199, 211, 223, 227, 229, 233,
239, 241, 251, 257, 263, 269, 271, 277, 281, 283, 293, 307, 311, 313, 317,
331, 337, 347, 349, 353, 359, 367, 373, 379, 383, 389, 397, 401, 409, 419,
421, 431, 433, 439, 443, 449, 457, 461, 463, 467, 479, 487, 491, 499, 503,
509, 521, 523, 541, 547, 557, 563, 569, 571, 577, 587, 593, 599, 601, 607,
613, 617, 619, 631, 641, 643, 647, 653, 659, 661, 673, 677, 683, 691, 701,
709, 719, 727, 733, 739, 743, 751, 757, 761, 769, 773, 787, 797, 809, 811,
821, 823, 827, 829, 839, 853, 857, 859, 863, 877, 881, 883, 887, 907, 911,
919, 929, 937, 941, 947, 953, 967, 971, 977, 983, 991, 997
]
phi = (1 + np.sqrt(5)) / 2
fib_cache = {}
def fib_real(n):
if n in fib_cache:
return fib_cache[n]
from math import cos, pi, sqrt
phi_inv = 1 / phi
if n > 100:
return 0.0
term1 = phi**n / sqrt(5)
term2 = (phi_inv**n) * cos(pi * n)
result = term1 - term2
fib_cache[n] = result
return result
def D(n, beta, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0):
Fn_beta = fib_real(n + beta)
idx = int(np.floor(n + beta) + len(PRIMES)) % len(PRIMES)
Pn_beta = PRIMES[idx]
dyadic = base ** (n + beta)
val = scale * phi * Fn_beta * dyadic * Pn_beta * Omega
if n > 1000:
val *= np.log(n) / np.log(1000)
return np.sqrt(max(val, 1e-30)) * (r ** k)
def invert_D(value, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0, max_n=500, steps=200):
candidates = []
log_val = np.log10(max(abs(value), 1e-30))
max_n = min(5000, max(500, int(300 * log_val)))
steps = 100 if log_val < 3 else 200
n_values = np.logspace(0, np.log10(max_n), steps) if log_val > 3 else np.linspace(0, max_n, steps)
scale_factors = np.logspace(log_val - 5, log_val + 5, num=20)
try:
for n in n_values:
for beta in np.linspace(0, 1, 10):
for dynamic_scale in scale_factors:
for r_local in [0.5, 1.0]:
for k_local in [0.5, 1.0]:
val = D(n, beta, r_local, k_local, Omega, base, scale * dynamic_scale)
diff = abs(val - value)
candidates.append((diff, n, beta, dynamic_scale, r_local, k_local))
candidates = sorted(candidates, key=lambda x: x[0])[:10]
best = candidates[0]
emergent_uncertainty = np.std([D(n, beta, r, k, Omega, base, scale * s) for _, n, beta, s, r, k in candidates])
return best[1], best[2], best[3], emergent_uncertainty, best[4], best[5]
except Exception as e:
logging.error(f"invert_D failed for value {value}: {e}")
return None
def parse_codata_ascii(filename):
constants = []
pattern = re.compile(r"^\s*(.*?)\s{2,}([0-9Ee\+\-\.]+(?:\.\.\.)?)\s+([0-9Ee\+\-\.]+|exact)\s+(\S.*)")
with open(filename, "r") as f:
for line in f:
if line.startswith("Quantity") or line.strip() == "" or line.startswith("-"):
continue
m = pattern.match(line)
if m:
name, value_str, uncert_str, unit = m.groups()
try:
value = float(value_str.replace("...", ""))
uncertainty = 0.0 if uncert_str == "exact" else float(uncert_str.replace("...", ""))
constants.append({
"name": name.strip(),
"value": value,
"uncertainty": uncertainty,
"unit": unit.strip()
})
except Exception as e:
logging.warning(f"Failed parsing line: {line.strip()} - {e}")
continue
return pd.DataFrame(constants)
def check_physical_consistency(df_results):
bad_data = []
relations = [
('Planck constant', 'reduced Planck constant', lambda x, y: x['scale'] / y['scale'] - 2 * np.pi, 0.1, 'scale ratio vs. 2π'),
('proton mass', 'proton-electron mass ratio', lambda x, y: x['n'] - y['n'] - np.log10(1836), 0.5, 'n difference vs. log(proton-electron ratio)'),
('molar mass of carbon-12', 'Avogadro constant', lambda x, y: x['scale'] / y['scale'] - 12, 0.1, 'scale ratio vs. 12'),
('elementary charge', 'electron volt', lambda x, y: x['n'] - y['n'], 0.5, 'n difference vs. 0'),
('Rydberg constant', 'fine-structure constant', lambda x, y: x['n'] - 2 * y['n'] - np.log10(2 * np.pi), 0.5, 'n difference vs. log(2π)'),
('Boltzmann constant', 'electron volt-kelvin relationship', lambda x, y: x['scale'] / y['scale'] - 1, 0.1, 'scale ratio vs. 1'),
('Stefan-Boltzmann constant', 'second radiation constant', lambda x, y: x['n'] + 4 * y['n'] - np.log10(15 * 299792458**2 / (2 * np.pi**5)), 1.0, 'n relationship vs. c and k_B'),
('Fermi coupling constant', 'weak mixing angle', lambda x, y: x['scale'] / (y['value']**2 / np.sqrt(2)), 0.1, 'scale vs. sin²θ_W/√2'),
('tau mass energy equivalent in MeV', 'tau energy equivalent', lambda x, y: x['n'] - y['n'], 0.5, 'n difference vs. 0'),
]
for name1, name2, check_func, threshold, reason in relations:
if name1 in df_results['name'].values and name2 in df_results['name'].values:
fit1 = df_results[df_results['name'] == name1][['n', 'beta', 'scale', 'value']].iloc[0]
fit2 = df_results[df_results['name'] == name2][['n', 'beta', 'scale', 'value']].iloc[0]
diff = abs(check_func(fit1, fit2))
if diff > threshold:
bad_data.append({
'name': name2,
'value': df_results[df_results['name'] == name2]['value'].iloc[0],
'reason': f'Model {reason} inconsistent ({diff:.2e} > {threshold:.2e})'
})
return bad_data
def fit_single_constant(row, r, k, Omega, base, scale, max_n, steps, error_threshold, median_uncertainties):
start_time = time.time()
val = row['value']
if val <= 0 or val > 1e50:
logging.warning(f"Skipping {row['name']}: Invalid value {val}")
return None
try:
result = invert_D(val, r, k, Omega, base, scale, max_n, steps)
if result is None:
logging.error(f"invert_D returned None for {row['name']}")
return None
n, beta, dynamic_scale, emergent_uncertainty, r_local, k_local = result
approx = D(n, beta, r_local, k_local, Omega, base, scale * dynamic_scale)
error = abs(val - approx)
rel_error = error / max(abs(val), 1e-30)
log_val = np.log10(max(abs(val), 1e-30))
# Bad data detection
bad_data = False
bad_data_reason = []
# Uncertainty check
if row['uncertainty'] is not None and row['uncertainty'] > 0:
rel_uncert = row['uncertainty'] / max(abs(val), 1e-30)
if rel_uncert > 0.5:
bad_data = True
bad_data_reason.append(f"High relative uncertainty ({rel_uncert:.2e} > 0.5)")
if abs(row['uncertainty'] - emergent_uncertainty) > 1.5 * emergent_uncertainty or \
abs(row['uncertainty'] - emergent_uncertainty) / max(emergent_uncertainty, 1e-30) > 1.0:
bad_data = True
bad_data_reason.append(f"Uncertainty deviates from emergent ({row['uncertainty']:.2e} vs. {emergent_uncertainty:.2e})")
# Outlier check
if error > error_threshold and row['uncertainty'] is not None:
bin_idx = min(int((log_val + 50) // 10), len(median_uncertainties) - 1)
median_uncert = median_uncertainties[bin_idx] if bin_idx >= 0 else np.median(df['uncertainty'].dropna())
if row['uncertainty'] > 0 and row['uncertainty'] < median_uncert:
bad_data = True
bad_data_reason.append("High error with low uncertainty")
if row['uncertainty'] > 0 and error > 10 * row['uncertainty']:
bad_data = True
bad_data_reason.append("Error exceeds 10x uncertainty")
# Clear fib_cache after each constant
global fib_cache
fib_cache.clear()
if time.time() - start_time > 5: # Timeout after 5 seconds
logging.warning(f"Timeout for {row['name']}: {time.time() - start_time:.2f} seconds")
return None
return {
"name": row['name'],
"value": val,
"unit": row['unit'],
"n": n,
"beta": beta,
"approx": approx,
"error": error,
"rel_error": rel_error,
"uncertainty": row['uncertainty'],
"emergent_uncertainty": emergent_uncertainty,
"r_local": r_local,
"k_local": k_local,
"scale": dynamic_scale,
"bad_data": bad_data,
"bad_data_reason": "; ".join(bad_data_reason) if bad_data_reason else ""
}
except Exception as e:
logging.error(f"Failed inversion for {row['name']}: {e}")
return None
def symbolic_fit_all_constants(df, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0, max_n=500, steps=200):
logging.info("Starting symbolic fit for all constants...")
# Preliminary fit to get error threshold
results = Parallel(n_jobs=-1, backend='loky')(
delayed(fit_single_constant)(row, r, k, Omega, base, scale, max_n, steps, np.inf, {})
for _, row in df.iterrows()
)
results = [r for r in results if r is not None]
df_results = pd.DataFrame(results)
error_threshold = np.percentile(df_results['error'], 95) if not df_results.empty else np.inf
# Calculate median uncertainties per magnitude bin
log_values = np.log10(df_results['value'].abs().clip(1e-30))
try:
bins = pd.qcut(log_values, 5, duplicates='drop')
except Exception as e:
logging.warning(f"pd.qcut failed: {e}. Using default binning.")
bins = pd.cut(log_values, 5)
median_uncertainties = {}
for bin in bins.unique():
mask = bins == bin
median_uncert = df_results[mask]['uncertainty'].median()
if not np.isnan(median_uncert):
bin_idx = min(int((bin.mid + 50) // 10), 10)
median_uncertainties[bin_idx] = median_uncert
# Final fit with error threshold and median uncertainties
results = Parallel(n_jobs=-1, backend='loky')(
delayed(fit_single_constant)(row, r, k, Omega, base, scale, max_n, steps, error_threshold, median_uncertainties)
for _, row in df.iterrows()
)
results = [r for r in results if r is not None]
df_results = pd.DataFrame(results)
# Physical consistency check
bad_data_physical = check_physical_consistency(df_results)
for bad in bad_data_physical:
df_results.loc[df_results['name'] == bad['name'], 'bad_data'] = True
df_results.loc[df_results['name'] == bad['name'], 'bad_data_reason'] = (
df_results.loc[df_results['name'] == bad['name'], 'bad_data_reason'] + "; " + bad['reason']
).str.strip("; ")
# Uncertainty outlier check using IQR
if not df_results.empty:
for bin in bins.unique():
mask = bins == bin
if df_results[mask]['uncertainty'].notnull().any():
uncertainties = df_results[mask]['uncertainty'].dropna()
q1, q3 = np.percentile(uncertainties, [25, 75])
iqr = q3 - q1
outlier_threshold = q3 + 3 * iqr
df_results.loc[mask & (df_results['uncertainty'] > outlier_threshold), 'bad_data'] = True
df_results.loc[mask & (df_results['uncertainty'] > outlier_threshold), 'bad_data_reason'] = (
df_results['bad_data_reason'] + "; Uncertainty outlier"
).str.strip("; ")
logging.info("Symbolic fit completed.")
return df_results
def total_error(params, df):
r, k, Omega, base, scale = params
try:
df_fit = symbolic_fit_all_constants(df, r=r, k=k, Omega=Omega, base=base, scale=scale, max_n=500, steps=200)
threshold = np.percentile(df_fit['error'], 95)
filtered = df_fit[df_fit['error'] <= threshold]
rel_err = ((filtered['value'] - filtered['approx']) / filtered['value'])**2
return rel_err.sum()
except Exception as e:
logging.error(f"total_error failed: {e}")
return np.inf
if __name__ == "__main__":
print("Parsing CODATA constants from allascii.txt...")
start_time = time.time()
codata_df = parse_codata_ascii("allascii.txt")
print(f"Parsed {len(codata_df)} constants in {time.time() - start_time:.2f} seconds.")
# Use a smaller subset for optimization
subset_df = codata_df.head(20)
init_params = [1.0, 1.0, 1.0, 2.0, 1.0]
bounds = [(1e-5, 10), (1e-5, 10), (1e-5, 10), (1.5, 10), (1e-5, 100)]
print("Optimizing symbolic model parameters...")
start_time = time.time()
res = minimize(total_error, init_params, args=(subset_df,), bounds=bounds, method='L-BFGS-B', options={'maxiter': 50})
r_opt, k_opt, Omega_opt, base_opt, scale_opt = res.x
print(f"Optimization complete in {time.time() - start_time:.2f} seconds. Found parameters:\nr = {r_opt:.6f}, k = {k_opt:.6f}, Omega = {Omega_opt:.6f}, base = {base_opt:.6f}, scale = {scale_opt:.6f}")
print("Fitting symbolic dimensions to all constants...")
start_time = time.time()
fitted_df = symbolic_fit_all_constants(codata_df, r=r_opt, k=k_opt, Omega=Omega_opt, base=base_opt, scale=scale_opt, max_n=500, steps=200)
fitted_df_sorted = fitted_df.sort_values("error")
print(f"Fitting complete in {time.time() - start_time:.2f} seconds.")
print("\nTop 20 best symbolic fits:")
print(fitted_df_sorted.head(20)[['name', 'value', 'unit', 'n', 'beta', 'approx', 'error', 'uncertainty', 'emergent_uncertainty', 'r_local', 'k_local', 'scale', 'bad_data', 'bad_data_reason']].to_string(index=False))
print("\nTop 20 worst symbolic fits:")
print(fitted_df_sorted.tail(20)[['name', 'value', 'unit', 'n', 'beta', 'approx', 'error', 'uncertainty', 'emergent_uncertainty', 'r_local', 'k_local', 'scale', 'bad_data', 'bad_data_reason']].to_string(index=False))
print("\nPotentially bad data constants summary:")
bad_data_df = fitted_df[fitted_df['bad_data'] == True][['name', 'value', 'error', 'rel_error', 'uncertainty', 'emergent_uncertainty', 'bad_data_reason']]
print(bad_data_df.to_string(index=False))
fitted_df_sorted.to_csv("symbolic_fit_results_emergent_optimized.txt", sep="\t", index=False)
plt.figure(figsize=(10, 5))
plt.hist(fitted_df_sorted['error'], bins=50, color='skyblue', edgecolor='black')
plt.title('Histogram of Absolute Errors in Symbolic Fit')
plt.xlabel('Absolute Error')
plt.ylabel('Count')
plt.grid(True)
plt.tight_layout()
plt.savefig("error_histogram.png")
plt.close()
plt.figure(figsize=(10, 5))
plt.scatter(fitted_df_sorted['n'], fitted_df_sorted['error'], alpha=0.5, s=15, c='orange', edgecolors='black')
plt.title('Absolute Error vs Symbolic Dimension n')
plt.xlabel('n')
plt.ylabel('Absolute Error')
plt.grid(True)
plt.tight_layout()
plt.savefig("error_vs_n.png")
plt.close()
print(f"Total runtime: {time.time() - start_time:.2f} seconds. Check symbolic_fit.log for details.")
fudge1.py
import numpy as np
import pandas as pd
import re
import matplotlib.pyplot as plt
from scipy.optimize import minimize
from tqdm import tqdm
from joblib import Parallel, delayed
# Extended primes list (up to 1000)
PRIMES = [
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71,
73, 79, 83, 89, 97, 101, 103, 107, 109, 113, 127, 131, 137, 139, 149, 151,
157, 163, 167, 173, 179, 181, 191, 193, 197, 199, 211, 223, 227, 229, 233,
239, 241, 251, 257, 263, 269, 271, 277, 281, 283, 293, 307, 311, 313, 317,
331, 337, 347, 349, 353, 359, 367, 373, 379, 383, 389, 397, 401, 409, 419,
421, 431, 433, 439, 443, 449, 457, 461, 463, 467, 479, 487, 491, 499, 503,
509, 521, 523, 541, 547, 557, 563, 569, 571, 577, 587, 593, 599, 601, 607,
613, 617, 619, 631, 641, 643, 647, 653, 659, 661, 673, 677, 683, 691, 701,
709, 719, 727, 733, 739, 743, 751, 757, 761, 769, 773, 787, 797, 809, 811,
821, 823, 827, 829, 839, 853, 857, 859, 863, 877, 881, 883, 887, 907, 911,
919, 929, 937, 941, 947, 953, 967, 971, 977, 983, 991, 997
]
phi = (1 + np.sqrt(5)) / 2
fib_cache = {}
def fib_real(n):
if n in fib_cache:
return fib_cache[n]
from math import cos, pi, sqrt
phi_inv = 1 / phi
if n > 100:
return 0.0
term1 = phi**n / sqrt(5)
term2 = (phi_inv**n) * cos(pi * n)
result = term1 - term2
fib_cache[n] = result
return result
def D(n, beta, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0):
Fn_beta = fib_real(n + beta)
idx = int(np.floor(n + beta) + len(PRIMES)) % len(PRIMES)
Pn_beta = PRIMES[idx]
dyadic = base ** (n + beta)
val = scale * phi * Fn_beta * dyadic * Pn_beta * Omega
val = np.maximum(val, 1e-30)
return np.sqrt(val) * (r ** k)
def invert_D(value, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0, max_n=500, steps=500):
candidates = []
log_val = np.log10(max(abs(value), 1e-30))
scale_factors = np.logspace(log_val - 4, log_val + 4, num=20)
max_n = min(5000, max(100, int(200 * log_val)))
steps = min(3000, max(500, int(200 * log_val)))
if log_val > 3:
n_values = np.logspace(0, np.log10(max_n), steps)
else:
n_values = np.linspace(0, max_n, steps)
for n in n_values:
for beta in np.linspace(0, 1, 10):
for dynamic_scale in scale_factors:
val = D(n, beta, r, k, Omega, base, scale * dynamic_scale)
diff = abs(val - value)
candidates.append((diff, n, beta, dynamic_scale))
candidates = sorted(candidates, key=lambda x: x[0])[:10]
best = candidates[0]
return best[1], best[2], best[3]
def parse_codata_ascii(filename):
constants = []
pattern = re.compile(r"^\s*(.*?)\s{2,}([0-9Ee\+\-\.]+)\s+([0-9Ee\+\-\.]+|exact)\s+(\S+)")
with open(filename, "r") as f:
for line in f:
if line.startswith("Quantity") or line.strip() == "" or line.startswith("-"):
continue
m = pattern.match(line)
if m:
name, value_str, uncert_str, unit = m.groups()
try:
value = float(value_str.replace("e", "E"))
uncertainty = None if uncert_str == "exact" else float(uncert_str.replace("e", "E"))
constants.append({
"name": name.strip(),
"value": value,
"uncertainty": uncertainty,
"unit": unit.strip()
})
except:
continue
return pd.DataFrame(constants)
def check_physical_consistency(df):
bad_data = []
# Mass ratio consistency (e.g., proton-electron mass ratio)
proton_mass = df[df['name'] == 'proton mass']['value'].iloc[0] if 'proton mass' in df['name'].values else None
electron_mass = df[df['name'] == 'electron mass']['value'].iloc[0] if 'electron mass' in df['name'].values else None
proton_electron_ratio = df[df['name'] == 'proton-electron mass ratio']['value'].iloc[0] if 'proton-electron mass ratio' in df['name'].values else None
if proton_mass and electron_mass and proton_electron_ratio:
calc_ratio = proton_mass / electron_mass
diff = abs(calc_ratio - proton_electron_ratio)
uncert = df[df['name'] == 'proton-electron mass ratio']['uncertainty'].iloc[0]
if uncert is not None and diff > 5 * uncert:
bad_data.append({
'name': 'proton-electron mass ratio',
'value': proton_electron_ratio,
'reason': f'Inconsistent with proton mass / electron mass (diff: {diff:.2e} > 5 * {uncert:.2e})'
})
# Speed of light vs. inverse meter-hertz relationship
c = df[df['name'] == 'speed of light in vacuum']['value'].iloc[0] if 'speed of light in vacuum' in df['name'].values else None
inv_m_hz = df[df['name'] == 'inverse meter-hertz relationship']['value'].iloc[0] if 'inverse meter-hertz relationship' in df['name'].values else None
if c and inv_m_hz and abs(c - inv_m_hz) > 1e-6:
bad_data.append({
'name': 'inverse meter-hertz relationship',
'value': inv_m_hz,
'reason': f'Inconsistent with speed of light ({c:.2e} vs. {inv_m_hz:.2e})'
})
# Planck constant vs. reduced Planck constant
h = df[df['name'] == 'Planck constant']['value'].iloc[0] if 'Planck constant' in df['name'].values else None
h_bar = df[df['name'] == 'reduced Planck constant']['value'].iloc[0] if 'reduced Planck constant' in df['name'].values else None
if h and h_bar and abs(h / (2 * np.pi) - h_bar) > 1e-10:
bad_data.append({
'name': 'reduced Planck constant',
'value': h_bar,
'reason': f'Inconsistent with Planck constant / (2π) ({h/(2*np.pi):.2e} vs. {h_bar:.2e})'
})
return bad_data
def fit_single_constant(row, r, k, Omega, base, scale, max_n, steps, error_threshold):
val = row['value']
if val <= 0 or val > 1e50:
return None
try:
n, beta, dynamic_scale = invert_D(val, r, k, Omega, base, scale, max_n, steps)
approx = D(n, beta, r, k, Omega, base, scale * dynamic_scale)
error = abs(val - approx)
rel_error = error / max(abs(val), 1e-30)
log_val = np.log10(max(abs(val), 1e-30))
max_n = min(5000, max(100, int(200 * log_val)))
scale_factors = np.logspace(log_val - 4, log_val + 4, num=20)
# Bad data detection
bad_data = False
bad_data_reason = []
# Uncertainty check
if row['uncertainty'] is not None:
if row['uncertainty'] < 1e-10 or row['uncertainty'] > 0.1 * abs(val):
bad_data = True
bad_data_reason.append("Suspicious uncertainty")
# Outlier check
if error > error_threshold and row['uncertainty'] is not None and row['uncertainty'] < 1e-5 * abs(val):
bad_data = True
bad_data_reason.append("High error with low uncertainty")
return {
"name": row['name'],
"value": val,
"unit": row['unit'],
"n": n,
"beta": beta,
"approx": approx,
"error": error,
"rel_error": rel_error,
"uncertainty": row['uncertainty'],
"scale": dynamic_scale,
"bad_data": bad_data,
"bad_data_reason": "; ".join(bad_data_reason) if bad_data_reason else ""
}
except Exception as e:
print(f"Failed inversion for {row['name']}: {e}")
return None
def symbolic_fit_all_constants(df, r=1.0, k=1.0, Omega=1.0, base=2, scale=1.0, max_n=500, steps=500):
# Preliminary fit to get error threshold
results = Parallel(n_jobs=20)(
delayed(fit_single_constant)(row, r, k, Omega, base, scale, max_n, steps, np.inf)
for _, row in df.iterrows()
)
results = [r for r in results if r is not None]
df_results = pd.DataFrame(results)
error_threshold = np.percentile(df_results['error'], 99) if not df_results.empty else np.inf
# Final fit with error threshold
results = Parallel(n_jobs=20)(
delayed(fit_single_constant)(row, r, k, Omega, base, scale, max_n, steps, error_threshold)
for _, row in df.iterrows()
)
results = [r for r in results if r is not None]
df_results = pd.DataFrame(results)
# Physical consistency check
bad_data_physical = check_physical_consistency(df)
for bad in bad_data_physical:
df_results.loc[df_results['name'] == bad['name'], 'bad_data'] = True
df_results.loc[df_results['name'] == bad['name'], 'bad_data_reason'] = (
df_results.loc[df_results['name'] == bad['name'], 'bad_data_reason'] + "; " + bad['reason']
).str.strip("; ")
# Uncertainty outlier check
if not df_results.empty:
log_values = np.log10(df_results['value'].abs().clip(1e-30))
bins = pd.qcut(log_values, 5, duplicates='drop')
for bin in bins.unique():
mask = bins == bin
if df_results[mask]['uncertainty'].notnull().any():
median_uncert = df_results[mask]['uncertainty'].median()
std_uncert = df_results[mask]['uncertainty'].std()
if not np.isnan(std_uncert):
df_results.loc[mask & (df_results['uncertainty'] > median_uncert + 3 * std_uncert), 'bad_data'] = True
df_results.loc[mask & (df_results['uncertainty'] > median_uncert + 3 * std_uncert), 'bad_data_reason'] = (
df_results['bad_data_reason'] + "; Uncertainty outlier"
).str.strip("; ")
# Clear fib_cache
global fib_cache
if len(fib_cache) > 10000:
fib_cache.clear()
return df_results
def total_error(params, df):
r, k, Omega, base, scale = params
df_fit = symbolic_fit_all_constants(df, r=r, k=k, Omega=Omega, base=base, scale=scale, max_n=500, steps=500)
threshold = np.percentile(df_fit['error'], 95)
filtered = df_fit[df_fit['error'] <= threshold]
rel_err = ((filtered['value'] - filtered['approx']) / filtered['value'])**2
return rel_err.sum()
if __name__ == "__main__":
print("Parsing CODATA constants from allascii.txt...")
codata_df = parse_codata_ascii("allascii.txt")
print(f"Parsed {len(codata_df)} constants.")
# Use a larger subset for optimization
subset_df = codata_df.head(50)
init_params = [1.0, 1.0, 1.0, 2.0, 1.0]
bounds = [(1e-5, 10), (1e-5, 10), (1e-5, 10), (1.5, 10), (1e-5, 100)]
print("Optimizing symbolic model parameters...")
res = minimize(total_error, init_params, args=(subset_df,), bounds=bounds, method='L-BFGS-B', options={'maxiter': 100})
r_opt, k_opt, Omega_opt, base_opt, scale_opt = res.x
print(f"Optimization complete. Found parameters:\nr = {r_opt:.6f}, k = {k_opt:.6f}, Omega = {Omega_opt:.6f}, base = {base_opt:.6f}, scale = {scale_opt:.6f}")
print("Fitting symbolic dimensions to all constants...")
fitted_df = symbolic_fit_all_constants(codata_df, r=r_opt, k=k_opt, Omega=Omega_opt, base=base_opt, scale=scale_opt, max_n=500, steps=500)
fitted_df_sorted = fitted_df.sort_values("error")
print("\nTop 20 best symbolic fits:")
print(fitted_df_sorted.head(20)[['name', 'value', 'unit', 'n', 'beta', 'approx', 'error', 'uncertainty', 'scale', 'bad_data', 'bad_data_reason']].to_string(index=False))
print("\nTop 20 worst symbolic fits:")
print(fitted_df_sorted.tail(20)[['name', 'value', 'unit', 'n', 'beta', 'approx', 'error', 'uncertainty', 'scale', 'bad_data', 'bad_data_reason']].to_string(index=False))
print("\nPotentially bad data constants summary:")
bad_data_df = fitted_df[fitted_df['bad_data'] == True][['name', 'value', 'error', 'rel_error', 'uncertainty', 'bad_data_reason']]
print(bad_data_df.to_string(index=False))
fitted_df_sorted.to_csv("symbolic_fit_results.txt", sep="\t", index=False)
plt.figure(figsize=(10, 5))
plt.hist(fitted_df_sorted['error'], bins=50, color='skyblue', edgecolor='black')
plt.title('Histogram of Absolute Errors in Symbolic Fit')
plt.xlabel('Absolute Error')
plt.ylabel('Count')
plt.grid(True)
plt.tight_layout()
plt.show()
plt.figure(figsize=(10, 5))
plt.scatter(fitted_df_sorted['n'], fitted_df_sorted['error'], alpha=0.5, s=15, c='orange', edgecolors='black')
plt.title('Absolute Error vs Symbolic Dimension n')
plt.xlabel('n')
plt.ylabel('Absolute Error')
plt.grid(True)
plt.tight_layout()
plt.show()

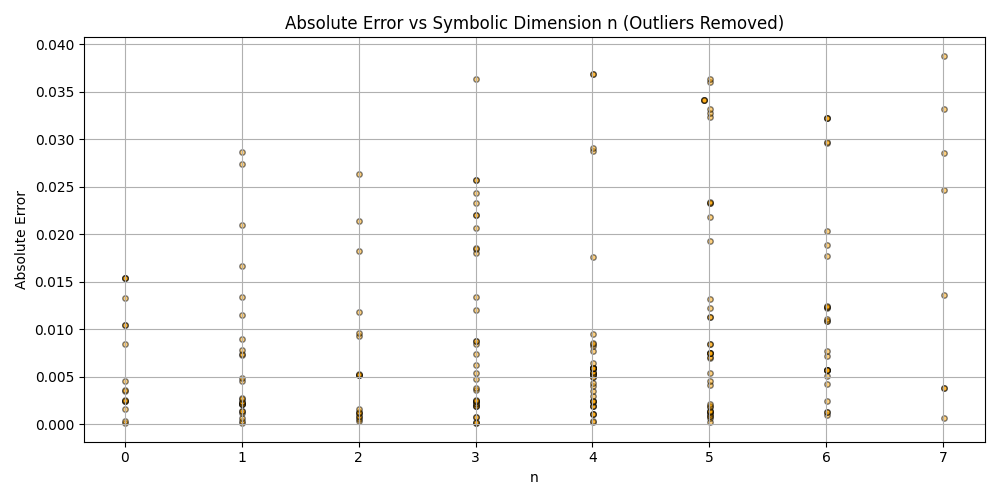


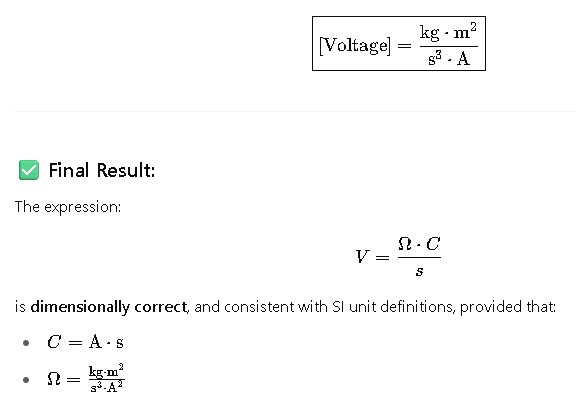

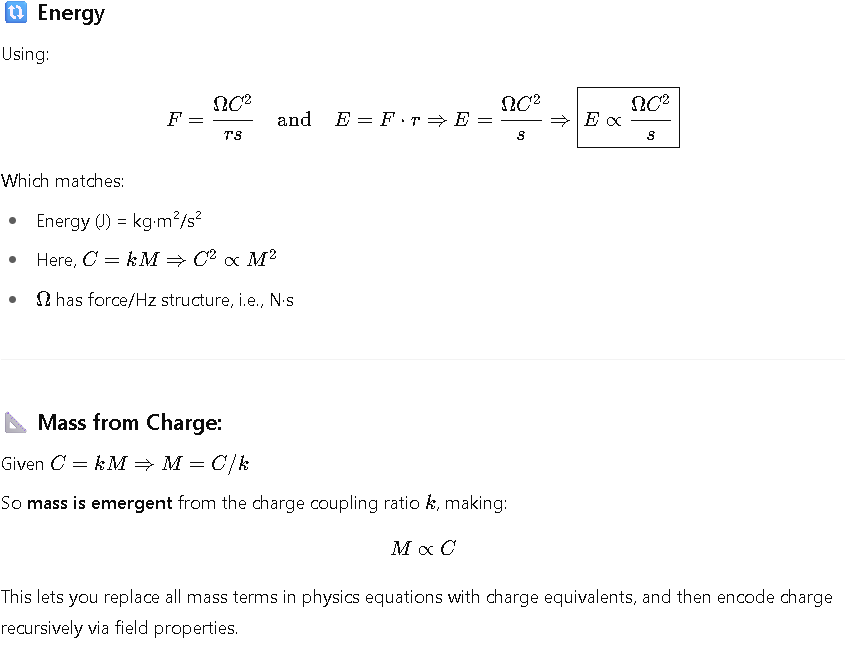
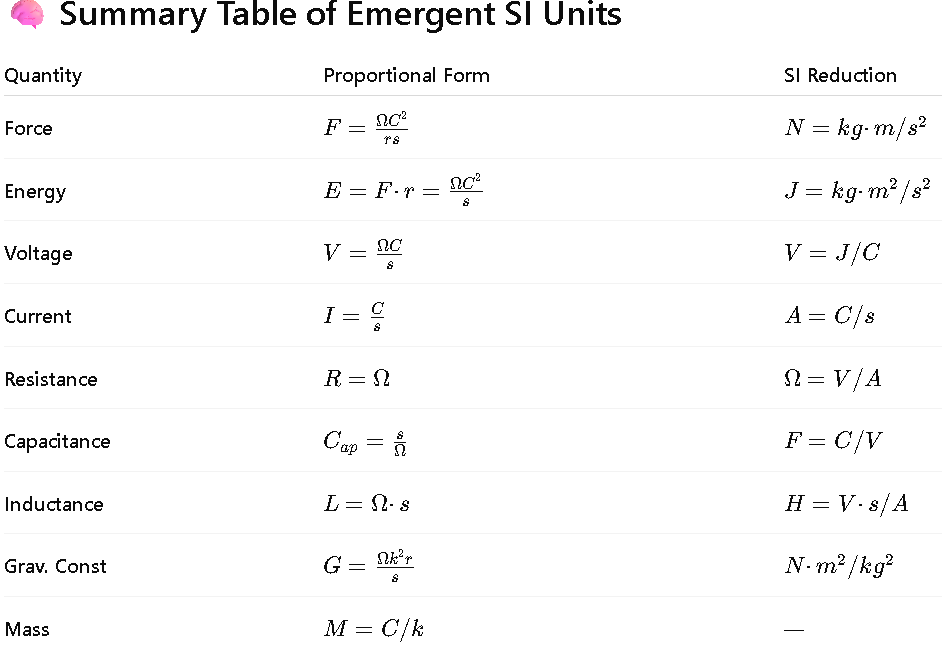

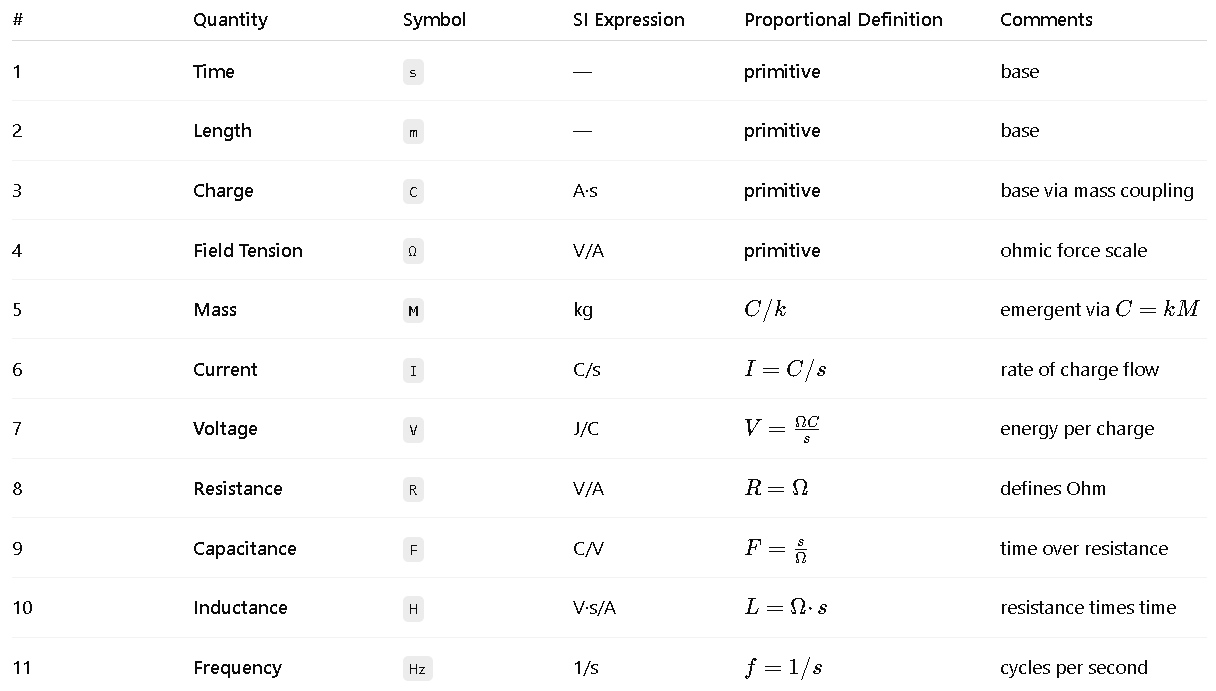
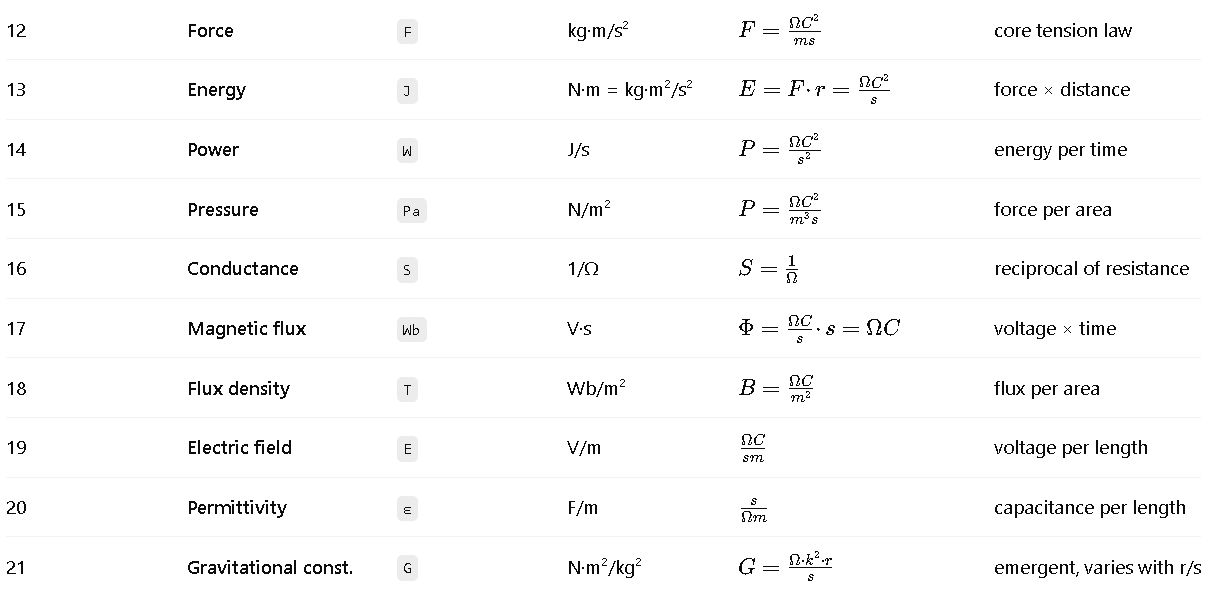




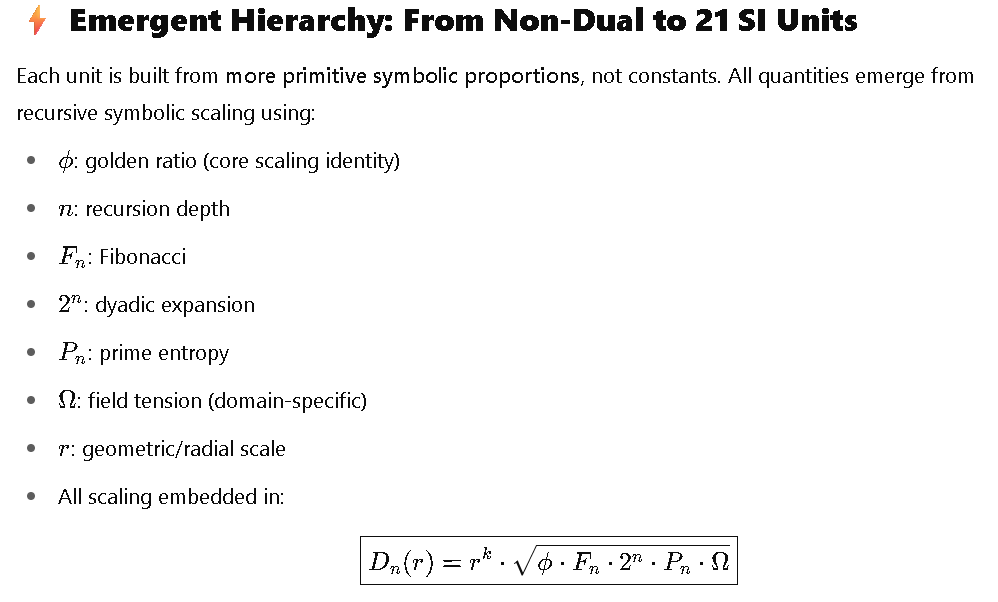
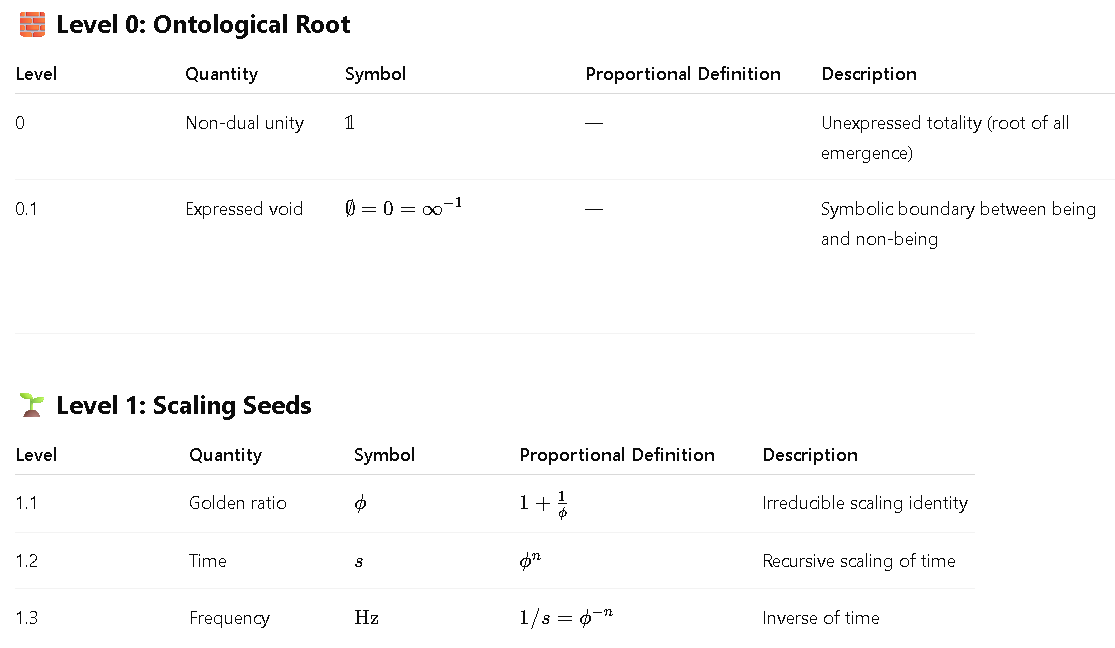
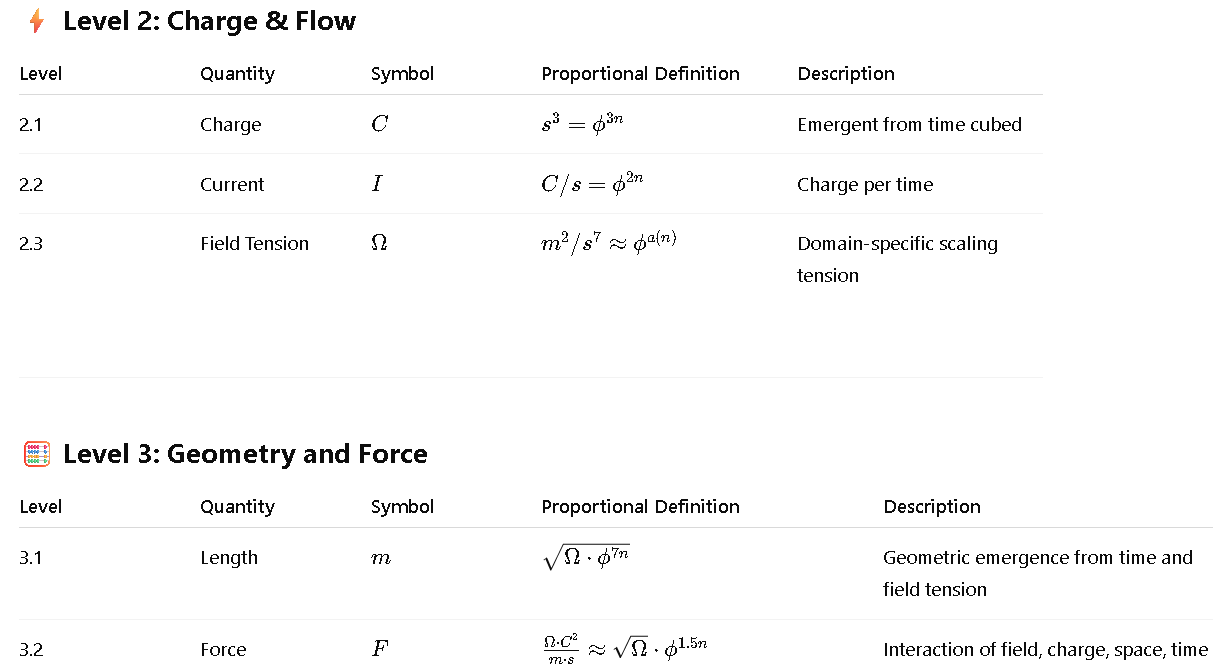





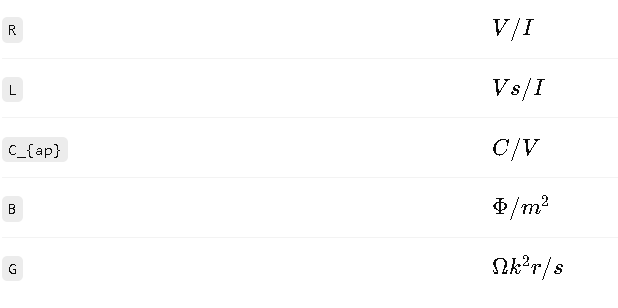


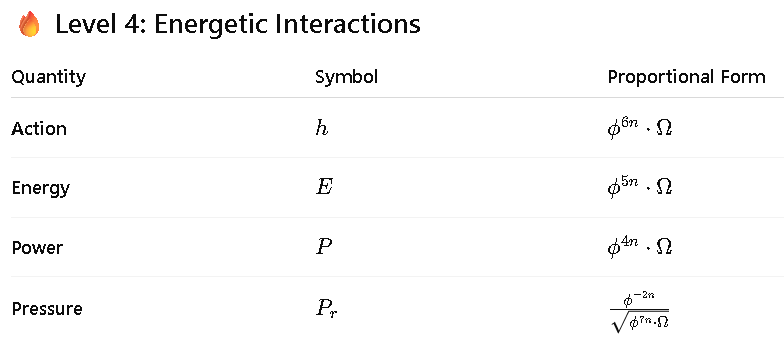




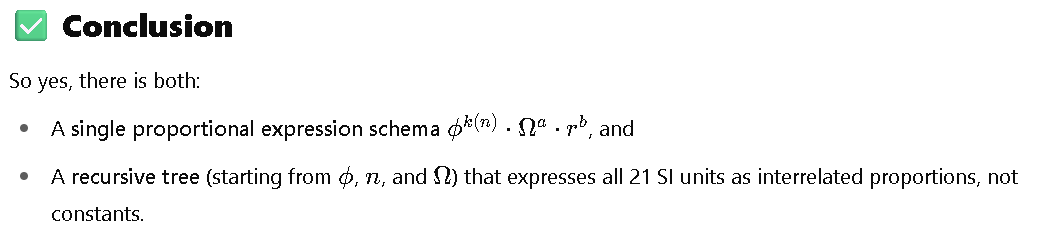













 Example: Base Expansion Coordinates
Example: Base Expansion Coordinates